前阵子,一个大学同学突然在群里私信我:“如果现在让你推荐一个 Decentralized AI(去中心化人工智能)项目,前提是**不炒作叙事、认真做底层基础设施**的,你会推荐哪个?不着急,你慢慢想。”
我盯着屏幕看了好几分钟。不是因为没有备选,而是因为这个问题一旦认真回答,筛选标准远比“哪个币最近涨得猛”要复杂和残酷得多。
为了不砸自己的招牌,我给答案设了三个硬门槛:
1. 必须有正在跑真实业务的主网,而不是停留在白皮书和 PPT 阶段;
2. 必须有真开发者在上面构建应用,而不是空有刷出来的节点交易数据;
3. 代币(Token)必须有实际的链上刚需场景,而不是纯粹的“空气治理币”。
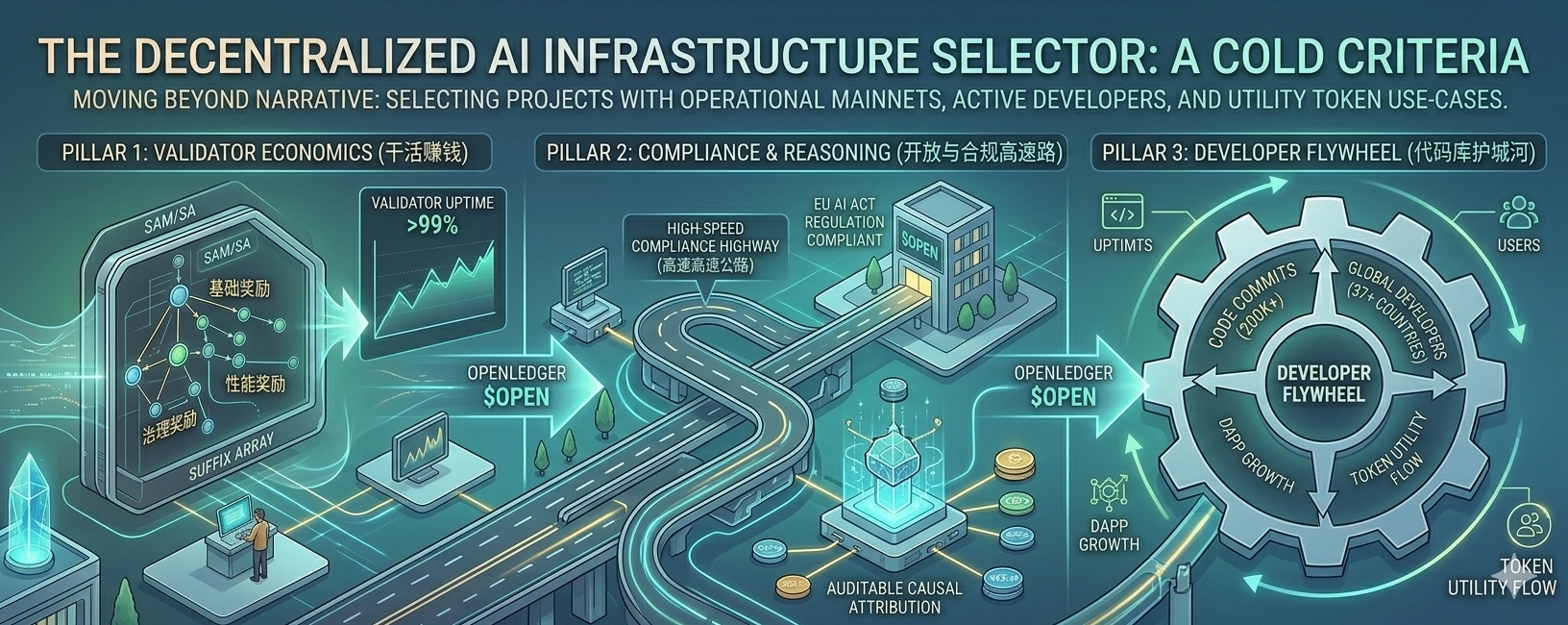
用这个筛子在市场上刮了一遍,@OpenLedger 成了极少数能真正浮出水面的项目。它不一定完美无缺,但在当下这个节点,它刚好卡在了最关键的生态位上。
一、 验证者经济:不养“吃利息”的闲人,只奖“干实活”的节点
加密圈传统的 Staking(质押)模型,本质上是“存钱领低保”。验证者的收入跟节点的实际业务表现毫无关系,存得多就赚得多,跟银行定存没区别。
但 OpenLedger 的验证者激励走的是另一套硬核逻辑——**“基础奖励 + 性能奖励 + 治理奖励”的三重矩阵**。节点的收益,直接与在线率(Uptime)、响应延迟(Latency)和验证准确性(Accuracy)数据挂钩。
这做对了一道行业长期交白卷的题:**回答质量高的节点拿肉吃,表现差、混日子的节点被经济模型自动淘汰。**
目前其节点在线率常年维持在 99% 以上。这说明什么?节点们不是靠“信仰”在发电,而是因为把活做好本身是极度吸金的。这和 Bitcoin 的挖矿逻辑异曲同工——**用最底层的博弈机制,确保诚实和高性能的行为远比恶意行为更有利可图。** 只是在 #OpenLedger 的语料生态里,“纯算力”被替换成了“数据与验证质量”。
正如其团队核心 Ram Kumar 多次强调的:如果一个网络的经济模型只刺激“存钱”而不刺激“干活”,那它最终吸引到的绝非 Builder(建设者),而是随时准备撤资的套利者。套利者风吹两边倒,只有建设者才能在熊市里守住网络的下限。

二、 开放与合规:在硬性监管前,提前修筑合规高速路
做 AI 基础设施,有一个绝大多数团队都在刻意逃避、但避无可避的灰犀牛——监管。
2026 年 8 月,欧盟《AI法案》(EU AI Act)对高风险 AI 系统的强制要求即将正式生效,技术文档留存、日志记录、事后追溯和不可篡改的监控审计成了硬指标。这个政策的引力场绝不仅限于欧洲,全球任何想做跨国 AI 业务的实体都必须被动接轨。
这时候,OpenLedger 偏底层的**归因引擎(Attribution Engine)**的优势就释放出来了。它的“归属证明系统(Proof of Ownership)”在模型训练和推理的生命周期里,会自动生成可验证的调用记录。从数据源头到最终的 Token 输出,每一步都有严密的链上铁证。
对于开发者而言,部署一个原生自带审计轨迹的 AI 系统,意味着不需要再去折腾复杂的合规工具。**这省下的不只是技术开发成本,更是悬在头顶的法律合规风险。**
透明和可追溯性,正在从一种“极客情怀”变成未来的商业刚需。
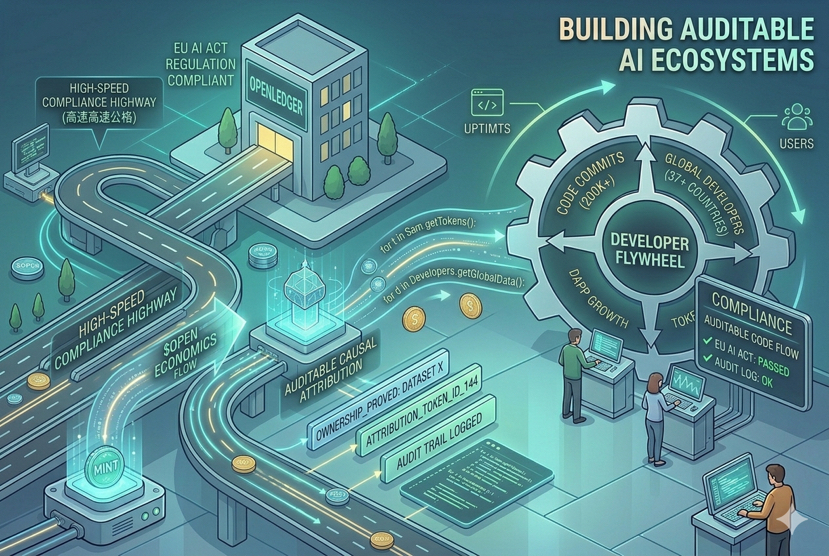
三、 开发者飞轮:代码库里藏着最硬的护城河
回到我同学提的那个问题。我后来的回复是:如果一个项目正在把协议真实收入的一部分,回流给质押者和生态国库,而不是单纯靠通胀发币来维持生存;如果它的主网上已经跑着真实的 AI 业务,那它至少值得你花时间去深度研究。
@OpenLedger 还有一个长期被市场低估的细节:它的开源代码库里,已经吸引了全球 37 个国家的开发者,贡献了超过 20 万行的核心代码。
一个 Web3 基础设施最宽的护城河,从来不是融了多少钱,或者公关稿写得有多宏大,而是**有多少开发者愿意把自己的业务赌在你的底层上**。
* 开发者涌入 \rightarrow 带来真实生态应用;
* 应用跑起来 \rightarrow 吸引真实用户与调用流量;
* 流量产生收入 \rightarrow 收入通过协议回流给质押者、国库与开发者。
这套内生飞轮一旦咬合成功并转动起来,就会像创作者经济一样,具备恐怖的自我强化和破局能力。
去中心化 AI 的下半场,究竟是靠虚无缥缈的叙事小作文驱动,还是靠扎实的节点在线率和代码提交量说话?
我坚定地选择后者。