Die Schnittstelle zwischen künstlicher Intelligenz und Blockchain-Technologie war lange Zeit von spekulativem Hype geprägt. Doch während wir uns durch 2026 bewegen, durchläuft der Markt einen massiven Wandel: Die Branche wechselt von spekulativen "KI-Erzählungen" zu produktionsbereiter, nutzenorientierter Infrastruktur.
An der absoluten Spitze dieser strukturellen Revolution steht @OpenLedger (OpenLedger), ein eigens gebautes, EVM-kompatibles Ethereum Layer-2 Netzwerk, das speziell entwickelt wurde, um den Lebenszyklus von dezentraler, verifizierbarer KI zu unterstützen. Unterstützt von Branchenvisionären wie Balaji Srinivasan (ehemaliger CTO von Coinbase) und Sreeram Kannan (Gründer von EigenLabs), beantwortet dieses Protokoll eine der drängendsten Fragen des digitalen Zeitalters: Wie machen wir KI rechenschaftspflichtig, verifizierbar und wirtschaftlich fair?
Hier ist eine umfassende Übersicht, wie #openlendger die Regeln des Datenbesitzes neu schreibt, warum sein natives Utility-Token $open die Marktaufmerksamkeit erregt und was auf dem ehrgeizigen Fahrplan 2026 bevorsteht.
Die Vision: Über Black-Box-KI hinausgehen
Traditionelle KI-Modelle sind grundsätzlich extraktiv. Technologiekonzerne scrapen die kollektive Intelligenz des Internets, trainieren massive Modelle und erfassen 100% des finanziellen Aufschwungs. Datenproduzenten – Akademiker, Fachexperten und alltägliche Internetnutzer – bleiben völlig aus der Wertschöpfungskette ausgeschlossen.
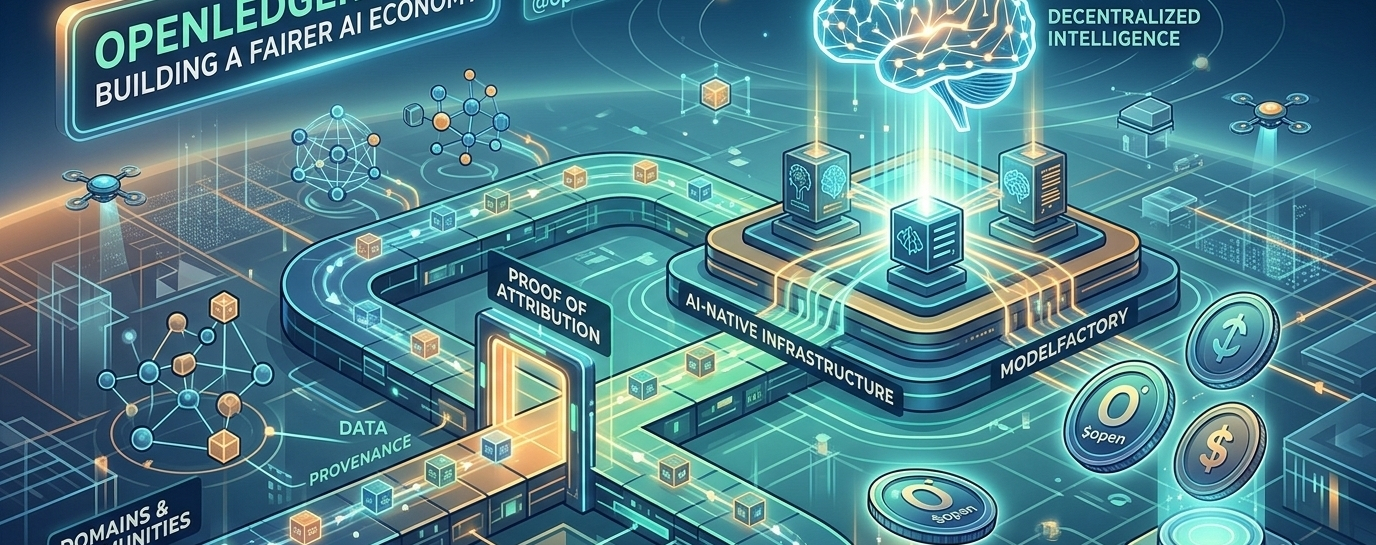
@OpenLedger ändert dieses Paradigma, indem es das Konzept der "Bezahlbaren KI" einführt. Durch die Protokollierung der Herkunft und Nutzung von Daten auf einem dezentralen Ledger etabliert die Plattform ein transparentes, automatisiertes Royaltiesystem.
Die technologische Überlegenheit des Protokolls liegt in seinen drei grundlegenden Komponenten:
Datanets: Das sind spezialisierte, gemeinschaftlich kuratierte und validierte Daten-Kollaborationsnetzwerke. Anstatt allgemeine Scrapes zu machen, co-kreieren die Gemeinschaften Nischen-Datensätze von hoher Qualität (wie spezialisierte medizinische Aufzeichnungen oder Codebasen), die erstklassige Nahrung für gezieltes KI-Modelltraining sind.
Proof of Attribution (PoA): Die zentrale Konsens- und Tracking-Engine des Netzwerks. PoA protokolliert unveränderlich die Herkunft jedes Datensatzes, Modells und KI-Agenten On-Chain. Wenn ein KI-Agent eine Aufgabe ausführt, berechnet PoA genau, welche Datenquelle den Output beeinflusst hat, was automatisierte, in Echtzeit ausgeführte Mikro-Zahlungen an die Beitragszahler auslöst.
OpenLoRA & ModelFactory: Die Senkung der Hardwarebarrieren ist entscheidend für das Scaling. OpenLoRA ermöglicht das Hosting und die Ausführung von Tausenden spezialisierter Low-Rank Adaptation (LoRA)-Modelle auf minimaler GPU-Infrastruktur, was die Betriebskosten erheblich senkt.
2026 Meilensteine: Von Mainnet zu globalem Maßstab
Nach dem erfolgreichen Start seines Mainnets Ende 2025 hat OpenLedger eine aggressive Entwicklungsmomentum beibehalten. Im Jahr 2026 hat das Projekt bedeutende technologische und gemeinschaftliche Meilensteine erreicht:
1. Der Rollout der 9-Layer Full-Stack-Plattform
Früher in diesem Jahr hat @OpenLedger seine umfassende Full-Stack-Architektur vorgestellt. Diese neunstufige Plattform reicht von Low-Level-Entwicklerumgebungen und Node-Orchestrierung bis hin zu autonomen KI-Agentenökonomien. Durch die Schaffung eines End-to-End-Rahmenwerks können Entwickler Daten sammeln, Modelle trainieren, Inferenz hosten und On-Chain-Finanzen verwalten, ohne das Ökosystem zu verlassen.
2. Cloud-Konfigurations-Upgrades: Vereinfachung der KI-Bereitstellung
Eines der hartnäckigsten Nadelöhre in der dezentralen KI ist die schiere Reibung bei der Bereitstellung. Um dem entgegenzuwirken, hat das Netzwerk eine Reihe robuster Cloud-Konfigurationsupdates eingeführt. Diese Updates vereinfachen, wie Entwickler virtuelle Maschinen aufsetzen, containerisierte KI-Modelle verwalten und mit verteilten GPU-Netzwerken interagieren. Durch die Standardisierung der Bereitstellung hat #openlendger die Übergangszeit von Code zu lebenden, umsatzgenerierenden KI-Agenten erheblich verkürzt.
3. Veröffentlichung des KI-Marktplatzes & Die Yapper Arena
Der bevorstehende dezentrale KI-Marktplatz ermöglicht es Entwicklern, ihre KI-Agenten direkt zu monetarisieren. Jede Eingabe und Ausführung wird transparent abgerechnet, wobei die Einnahmen an die ursprünglichen Modellschöpfer und Datenanbieter zurückfließen. Dies folgt auf den Abschluss der "Yapper Arena"-Gemeinschaftsinitiative im März 2026, die einen massiven Preispool von 2 Millionen Tokens verteilte, um die frühen Tester, Entwickler und Befürworter der Plattform zu belohnen.
Der Wirtschaftsmotor: Tokenomics von $open
Das native Asset $OPEN dient als wirtschaftliche Lebensader für das gesamte Layer-2-Ökosystem. Es ist mit einer Hard Cap von 1 Milliarde Tokens konzipiert und strukturiert sich um konstante Nutzenabsaugungen:
Netzwerkgebühren (Gas): Jede On-Chain-Attributionsverifizierung, Datensatz-Upload und Smart Contract-Interaktion wird in $OPEN bezahlt.
Attributionsabwicklungen: Entwickler zahlen für die Nutzung von Modellen, und die Belohnungen werden programmgesteuert an Node-Betreiber und Datenbeitragszahler in $OPEN zurückgeleitet.
Sicherheits-Staking: Um "vergiftete Daten" oder böswillige Validierungen zu verhindern, müssen Nodes und KI-Agenten $open staken, um dem Netzwerk beizutreten, was die finanziellen Anreize mit der Netzwerkgesundheit in Einklang bringt.
Governance: Inhaber von $open stimmen aktiv über Protokoll-Upgrades, Zuwendungsverteilungen und die Parameter ab, die neue Datanets regeln.
Die Zukunft: Eine liquide Schicht für Intelligenz
In einer digitalen Landschaft, die zunehmend mit synthetischen Daten und Deepfakes überladen ist, wird verifizierbares "Open Data" zu einer Premium-Asset-Klasse. Durch die Umwandlung statischer Datensätze, trainierter Modelle und autonomer KI-Agenten in liquide, komposable On-Chain-Finanzassets schnitzt sich @undefined eine hoch verteidigbare Nische im Web3-Bereich.
Durch den starken Fokus auf die Vereinfachung der Entwicklerreibung, Verbesserung der Bereitstellungsinfrastruktur und strenge Durchsetzung der Datenattribution beweist #openleder , dass die Zukunft der künstlichen Intelligenz nicht den schädlichen monopolistischen Gatekeepern gehören muss. Durch die Kraft von $open kann die Zukunft der KI Open-Source, kollaborativ und für alle lohnend sein.