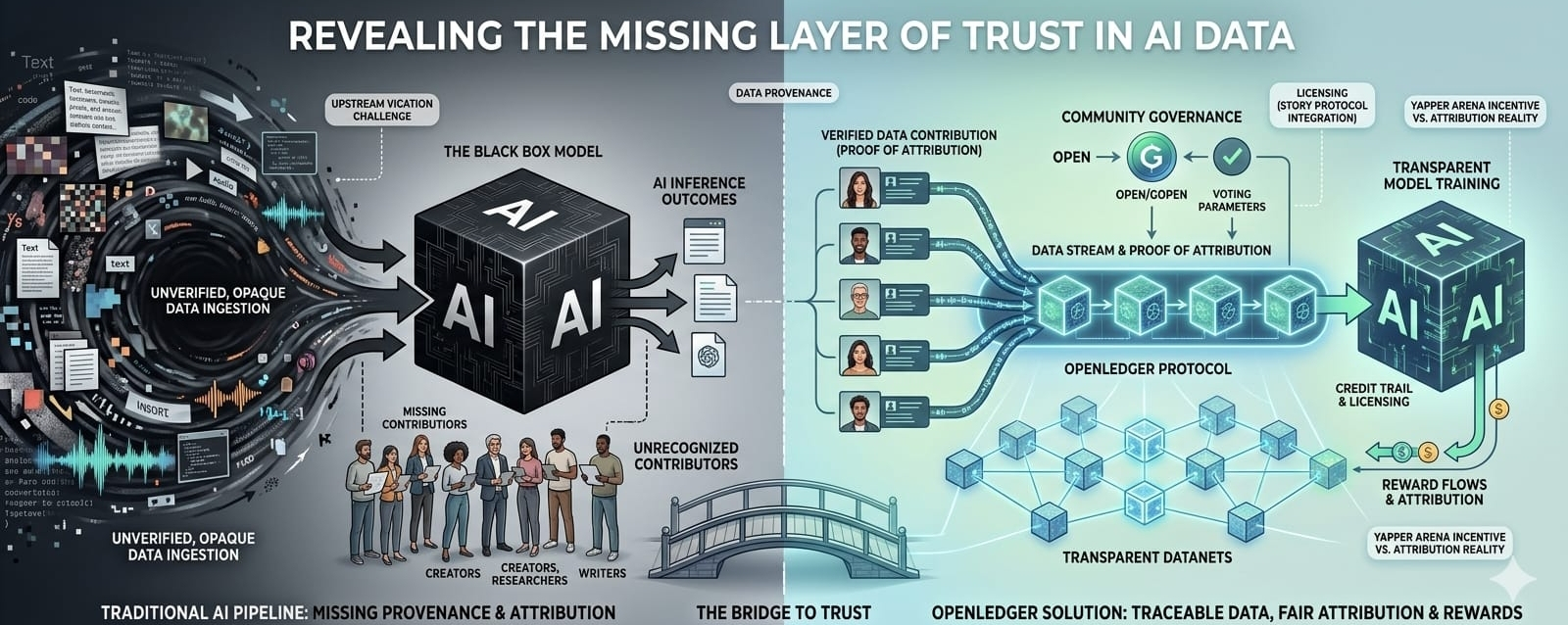
I spent a good part of today thinking about something that honestly started as a very dry question, but slowly became more interesting the longer I sat with it: where does the data behind AI models actually come from, and who gets to claim ownership over it once it becomes useful? Not the surface-level version of the question where people argue about whether AI is good or bad, but the more basic one. Who created the data, who gave permission for it to be used, who gets credited after it becomes part of a model, and who gets rewarded when that model starts generating value? That thought led me toward OpenLedger, and at first I expected the usual AI plus blockchain pitch that sounds good for a few minutes and then starts feeling empty. But the more I looked at what OpenLedger is trying to build, the more it felt like the project is touching a part of AI transparency that people do not talk about enough.
Most of the time, when people talk about transparency in AI, they are talking about the model after it has already been trained. They want to know why it gave a certain answer, whether the output is biased, whether the model can explain itself, or whether users can audit its decisions. Those are important questions, but they are not the first questions. Before any model gives an answer, before anyone tests its behavior, before anyone argues about its reasoning, there is a data pipeline that made the model possible in the first place. And that pipeline is usually hidden. Data is collected from different places, cleaned, mixed, trained on, and then somehow disappears into the final system. By the time users interact with the model, there is rarely a clear trail left behind. You cannot easily ask whose data was used, whether it was licensed properly, whether the original contributors agreed to it, or whether anyone was compensated. The model is visible, but the data history behind it is mostly gone.
That is the part where OpenLedger becomes interesting to me. Its Proof of Attribution system is trying to create a permanent record of data contributions before they vanish into the training process. Instead of treating data like invisible fuel that gets burned once the model is trained, OpenLedger is trying to make each contribution traceable. When a dataset is uploaded or when someone contributes to a specific Datanet, that contribution can be recorded on-chain, creating a trail that is not just dependent on a company saying, “trust us.” In theory, if that data helps improve a model or influences value later, the contributor can still be recognized and rewarded. That is a very different way of thinking about AI data because it turns the contributor into part of the value chain rather than someone whose work quietly disappears once the model becomes useful.
The governance side also adds another layer to the idea. OPEN holders being able to convert into GOPEN for governance means the community is not only watching the system from the outside or speculating on the token. They can participate in decisions around how attribution works, how parameters are defined, and what the protocol should recognize as valid contribution. That matters because attribution is not just a technical problem. It is also a rules problem. Someone has to decide what counts, how it counts, and how rewards should move when data becomes useful. A lot of projects use the phrase community governance very loosely, but in OpenLedger’s case, governance is connected to the actual structure of the attribution layer, which makes the idea feel more practical than just another slogan.
Still, the part I cannot ignore is that recording something on-chain does not automatically make the original data clean. A ledger can preserve a record, but it cannot magically prove that the person uploading the data had the right to upload it in the first place. If someone contributes scraped, copied, or misappropriated data, the system may still record that contribution accurately. In that case, the transparency is real, but the fairness is not. The chain can show who submitted the data, when it was submitted, and how it moved through the protocol, but the more difficult question is whether that data was ethically and legally sourced before it entered the system. That upstream problem is where the entire idea becomes much harder than it looks.
The way I keep thinking about it is like a perfect receipt system for a marketplace. Every sale is recorded, every buyer and seller is visible, every payment can be traced, and the accounting looks clean. But if nobody checks whether the goods were stolen before they entered the market, then the record can be perfect while the system underneath is still flawed. That is the tension OpenLedger has to deal with. Proof of Attribution can help solve the problem of invisible contribution, but it also needs strong ways to deal with bad or questionable data before attribution turns into reward. Otherwise, the system could end up rewarding the wrong people simply because they were the first to put something on-chain.
That is why the connection with Story Protocol feels important. If OpenLedger can combine its attribution system with stronger licensing standards and clearer ownership frameworks for AI training data, then the project starts looking less like a simple blockchain record and more like a real trust layer for AI data management. Attribution is powerful, but attribution with licensing, permission, and compliance is much stronger. The challenge is that this kind of system has to be tested in the real world, not just described well. It needs actual contributors, real Datanets, legitimate datasets, and reward flows that prove the mechanism works beyond theory. The idea is strong, but the execution is what will decide whether it becomes infrastructure or just another well-written narrative.
There is also an interesting contrast happening around the current incentives. The 2 million OPEN Yapper Arena is clearly built to create attention and community activity, and that makes sense from a market perspective. Projects need visibility, especially in a space where narratives move quickly. But it also creates a strange tension because social engagement and real attribution are not the same thing. One measures who is talking about the project. The other measures whether valuable, legitimate data is entering the system and being used fairly. Both can matter, but they should not be confused. If the loudest activity around an attribution protocol is mostly people farming attention, then it becomes important to watch whether the actual data layer is growing at the same pace.
That is where I am landing on OpenLedger for now. I think the project is asking the right question, and that alone makes it more interesting than a lot of AI blockchain ideas I have seen. Most people are focused on making AI outputs more transparent, but OpenLedger is looking further back and asking whether the data behind those outputs can be traced, credited, and rewarded. That is a much deeper issue because AI models are only as legitimate as the data systems that feed them. The part that still needs proof is whether the protocol can verify not just that data was contributed, but that it was contributed fairly and legally. If OpenLedger can solve that, or even make serious progress toward it, then it could become a meaningful layer in the future of AI data ownership. If not, it may still create transparency, but transparency alone will not be enough. The real test is whether the ledger can support trust, not just record activity.
