That distinction sounds subtle. It changes everything about how you read the protocol.
A platform accepts contributions. A market prices them. The difference lives in the incentive layer, what gets rewarded, at what rate, and under what conditions. @OpenLedger Datanet architecture makes considerably more sense once you read it as market design rather than infrastructure design. That framing also connects everything covered in this series into a single coherent picture.
The Constraints Are Not Restrictions. They Are Market Architecture.
Start with the rules that initially look like limitations.
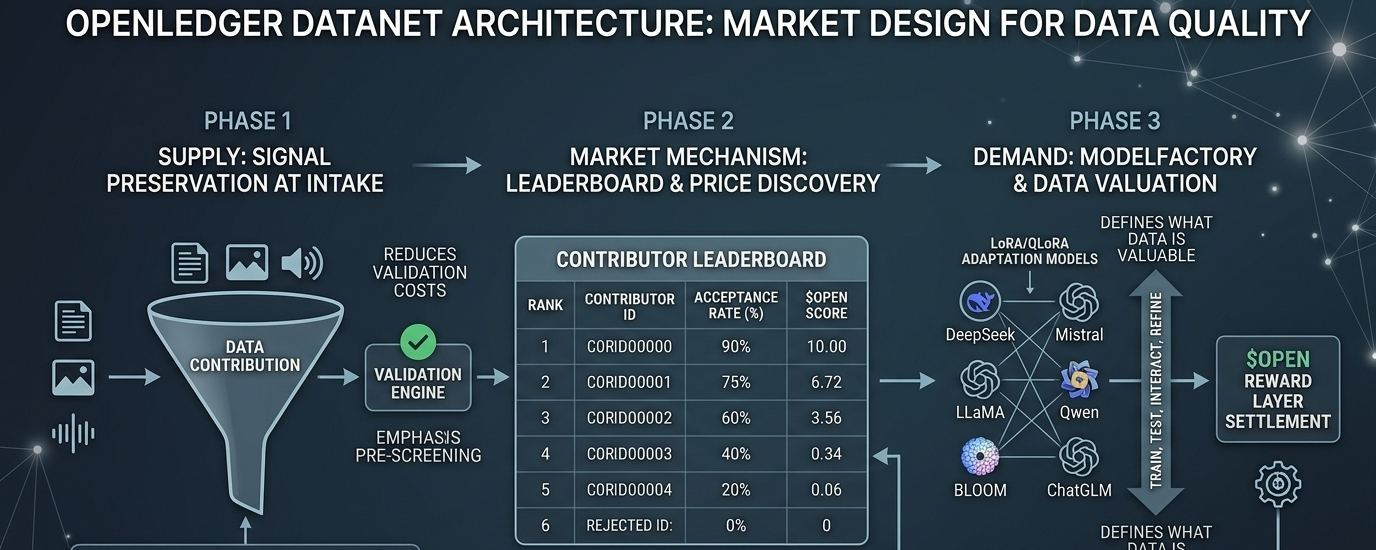
Text, images, and audio cannot be mixed within a single Datanet. Files are capped at 10 megabytes per contribution window. Maximum twenty files per submission. Format validation runs before anything enters the pipeline. Most people read these as spam filters. Spam control is part of it. The deeper function is signal preservation at the supply level.
When a data market operates without constraints, it fills with noise at the same rate it fills with value. Platforms that allowed unrestricted open contribution in earlier AI data experiments spent enormous downstream resources filtering output that should never have entered the training pipeline in the first place. OpenLedger's limits do not restrict contribution volume for its own sake. They reduce the cost of validating what arrives. That is a different problem being solved, and solving it at the intake layer is significantly more efficient than solving it after the fact.
The Leaderboard Is a Price Discovery Mechanism
This is the part of the Datanet design that gets misread most often. The leaderboard does not rank contributors by volume uploaded. It ranks by acceptance rate, the ratio of validated contributions against total submissions attempted.
Rejected files do not penalize the contributor's position. Only accepted files build ranking and accumulate contribution score. That specific design choice matters because it encourages experimentation without punishing failure. A contributor can test edge-case formats, underrepresented data types, or novel inputs without destroying their standing in the process.
What the leaderboard is actually doing is surfacing the market rate for data quality in real time. High acceptance rate signals consistent value. Low acceptance rate signals noise. The $OPEN reward layer settles against that signal rather than against raw participation count. This is how you build a sustainable data economy rather than a data dump with token incentives layered on top.
ModelFactory Defines the Demand Side of the Same Market
Earlier in this series, ModelFactory appeared as an accessibility story, no-code LLM fine-tuning for anyone without a development background. The more precise read is that ModelFactory defines what data is actually valuable at any given moment by determining what is being trained.
LoRA and QLoRA support matters here specifically. Because full fine-tuning at scale remains expensive, the models being built on #OpenLedger are lightweight adaptation models, domain-specific, built to improve on a narrow task efficiently. The data that scores highest in Datanet is the data that improves those specific models most directly.
DeepSeek, Mistral, Qwen, LLaMA, BLOOM, ChatGLM, the breadth of supported model families means the demand surface for data stays wide. Different model families value different data characteristics. That creates genuine diversity in what earns Open rewards rather than concentrating emissions toward one narrow category of contribution indefinitely.
Train, test, interact, refine. That continuous loop is not just a product workflow. It is the feedback mechanism that keeps the market honest about what data is actually worth at each stage of model development.
Where Open Sits in All of This
OPEN settles a data market that has real quality constraints on the supply side and active model training defining the demand side. That is a structurally more durable demand foundation than most infrastructure tokens currently operate with.
My position in Open remains in profit through this build-out phase. The data market design was part of the original reasoning. Markets with genuine quality filtering tend to produce more sustainable economic signals over time than open platforms where all participation gets rewarded equally regardless of value delivered.
Watch the acceptance rate data as Datanet scales. That number will say more about the health of this economy than the price chart will in the short term.