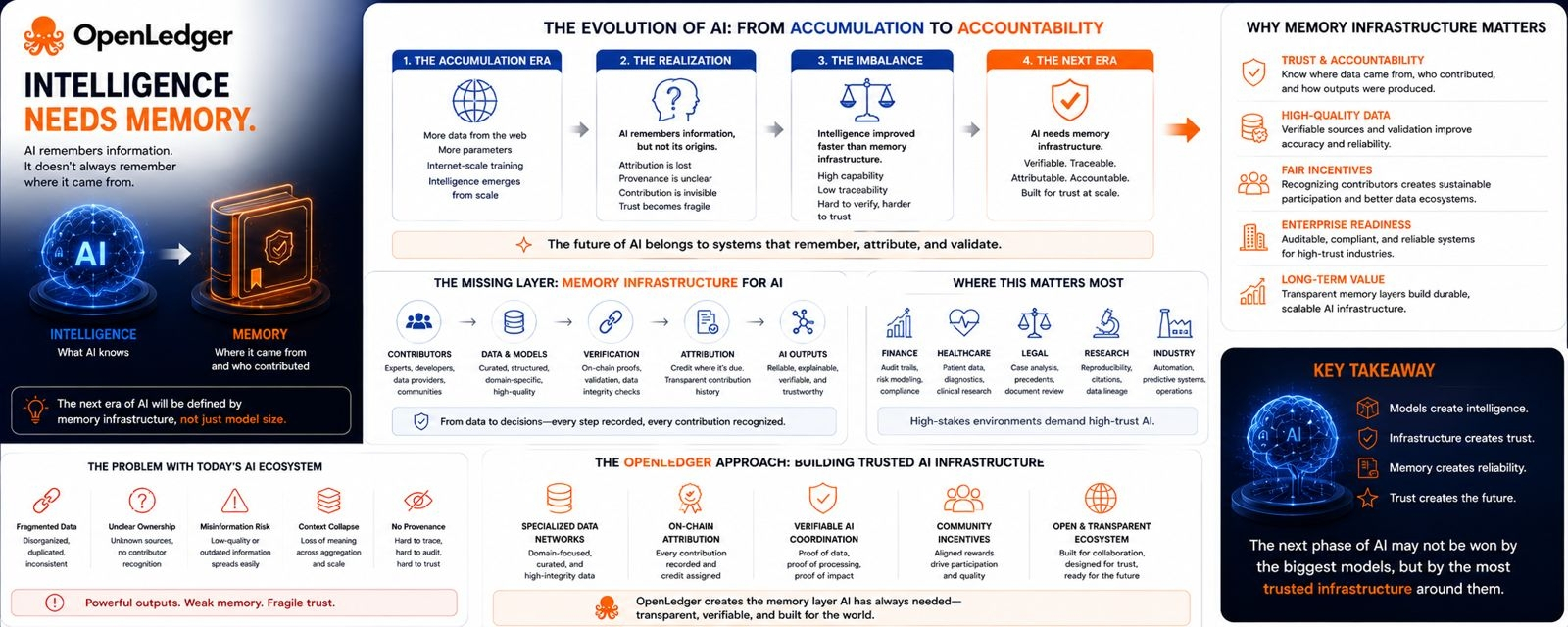
And if I tell from bottom of my heart thee first generation of AI systems was built around accumulation.
More data. More parameters. More internet-scale training. The underlying assumption was simple: if models absorbed enough information from the web, intelligence would naturally emerge from scale itself. And to a remarkable extent, it did. Modern AI systems can summarize research, generate software, simulate conversation, analyze markets, and produce content at a speed that would have seemed unrealistic only a few years ago.
But the more capable these systems become, the more visible another problem starts to appear.
AI remembers information. It does not necessarily remember where that information came from.
That distinction matters far more than most people initially expected.
What stands out to me is that the current AI ecosystem has become incredibly efficient at extracting knowledge while remaining surprisingly weak at preserving attribution, provenance, and contribution history. Models ingest massive amounts of public and private information, yet the relationship between inputs and outputs often becomes difficult to trace once training is complete.
In practical terms, intelligence improved faster than memory infrastructure.
And I think that imbalance is becoming one of the defining challenges of the next AI era.
The internet was never designed to function as a structured memory system for machine intelligence. It was designed as a massive, decentralized publishing environment shaped by human behavior, incentives, advertising systems, social interaction, and information velocity. AI models trained on that environment inherit both its strengths and its weaknesses.
They inherit scale.
But they also inherit fragmentation, inconsistency, misinformation, duplication, context collapse, and unclear ownership structures.
This creates a serious structural issue as AI moves deeper into high-trust environments like finance, healthcare, cybersecurity, scientific research, and legal systems. In these sectors, raw intelligence alone is not enough. Organizations increasingly need systems capable of showing how knowledge was formed, which sources influenced outputs, whether information can be verified, and how accountability can be maintained across complex workflows.
Memory becomes operational infrastructure.
Not metaphorical memory. Systemic memory.
I keep coming back to the idea that modern AI lacks durable context layers. Most systems are optimized for response generation rather than historical transparency. They can produce answers fluently while offering limited visibility into contribution lineage, dataset integrity, or reasoning provenance.
That works in low-friction consumer environments. It becomes much harder to defend in enterprise or institutional systems where trust must survive scrutiny.
And this is where the conversation around decentralized AI infrastructure becomes more interesting than many people realize.
A lot of public discussion still frames blockchain and AI integration too simplistically, usually reducing it to token speculation or vague narratives about “decentralized intelligence.” But the deeper and more important question is actually about coordination and memory.
How do intelligent systems preserve trustworthy records of contribution, validation, modification, and usage over time?
That is a fundamentally different problem.
Projects like OpenLedger are exploring this idea through verifiable AI infrastructure and specialized data ecosystems. What makes this direction meaningful is not the branding around decentralization itself, but the attempt to build systems where contributors, datasets, models, and outputs exist inside more transparent and traceable environments.
Because once AI systems begin operating as economic infrastructure, memory stops being optional.
Attribution starts affecting incentives. Provenance starts affecting trust. Validation starts affecting adoption.
The system needs to remember who contributed, what changed, and why it matters.
This becomes especially important as AI shifts toward specialized domain intelligence. General-purpose models remain powerful, but many real-world environments increasingly depend on narrower, context-rich systems trained on curated and verifiable data sources. Financial modeling, medical diagnostics, industrial automation, legal reasoning, and scientific discovery all require stronger relationships between knowledge and accountability.
In these environments, forgetting is expensive.
A model may generate a technically plausible answer while relying on outdated assumptions, unverifiable information, or low-quality training patterns inherited from the open web. Without strong memory systems around data provenance and validation, users often struggle to distinguish confidence from reliability.
And AI systems are very good at sounding reliable.
That tension between fluency and trust is becoming more important than raw capability growth itself.
What also fascinates me is the economic side of this shift. The internet created enormous value through invisible contribution layers. Millions of people generated content, behavioral data, moderation signals, feedback loops, and specialized knowledge that eventually trained intelligent systems. Yet most contributors remained disconnected from ownership, attribution, or long-term participation in the value their information helped create.
AI inherited the internet’s intelligence. But not its memory of contribution.
I think future AI infrastructure will increasingly attempt to solve this imbalance. Not perfectly, because attribution in collective intelligence systems is incredibly difficult, but more effectively than current architectures allow. Systems that can preserve transparent contribution histories may create stronger incentives, better data quality, and more sustainable coordination models over time.
That does not mean every AI system needs radical openness or fully decentralized governance. Some centralized coordination will remain necessary for performance, security, and operational consistency. But purely opaque systems operating at massive scale will continue facing growing pressure from enterprises, regulators, researchers, and users demanding clearer accountability structures.
Eventually every mature infrastructure system develops memory layers.
Financial systems developed auditing frameworks. Supply chains developed tracking systems. Software development developed version control. Scientific research developed citation structures and reproducibility standards.
AI will likely move in the same direction.
Because intelligence without memory creates fragile ecosystems. Systems become more capable while becoming harder to verify. Information moves faster while accountability becomes weaker. Outputs scale while provenance disappears into abstraction.
That may be efficient in the short term.
It is probably unstable in the long term.
The next stage of AI may not be defined only by who builds the largest models or the fastest inference systems. It may be shaped by who builds the most trustworthy memory architecture around intelligence itself.
And honestly, I think that shift is already starting.