been going through openledger’s architecture notes and a few community threads, and i keep bouncing between “this is a coherent design” and “this might be a token-first incentive loop waiting for demand.” most people think openledger is just another ai + crypto token that pays people to upload datasets. that’s the oversimplified story. the harder (and more interesting) claim is that it can link data contribution → model improvement/usage → on-chain payout in a way that doesn’t collapse under gaming.
the system seems to revolve around a few moving parts.
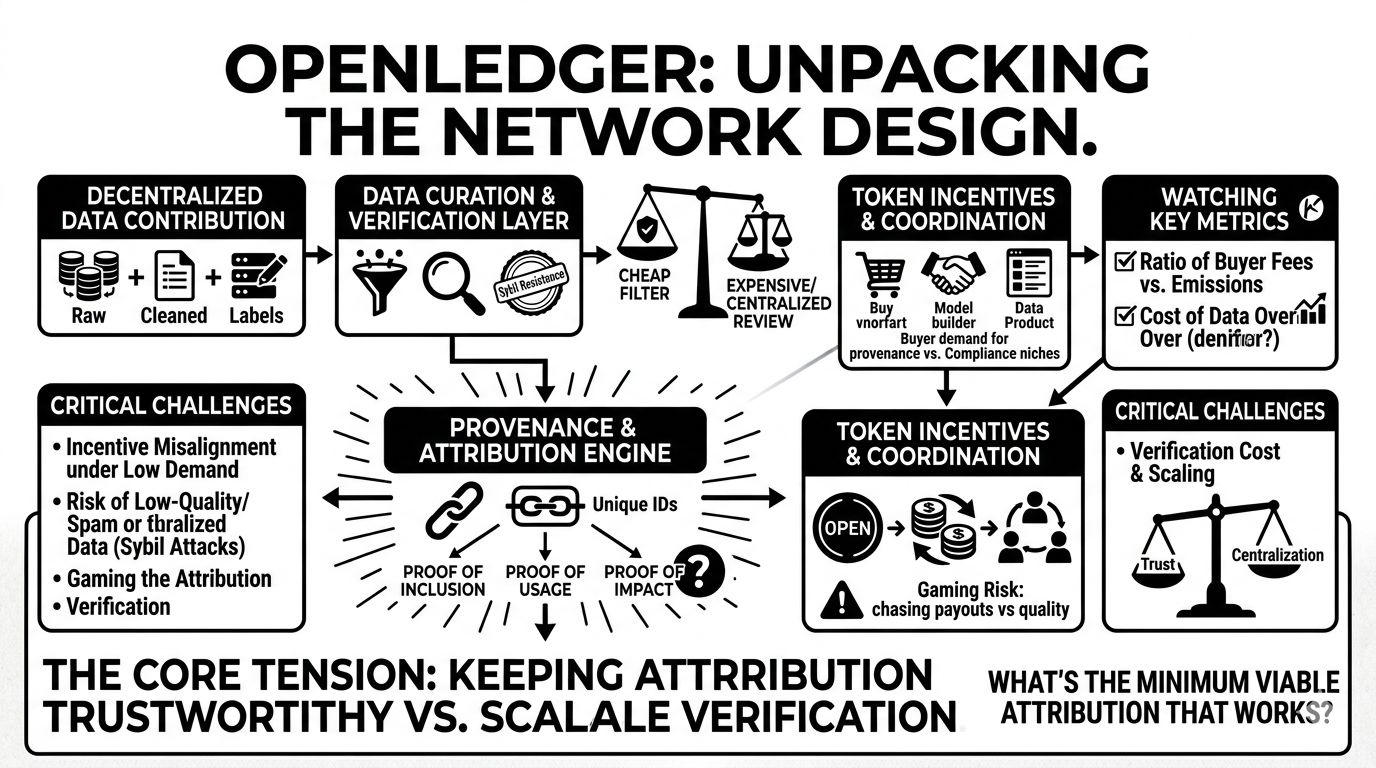
decentralized data contribution system
openledger’s contribution layer looks like it wants to accept a wide range of inputs: raw data, cleaned corpora, labels, maybe even evaluation traces. what caught my attention is that the “decentralized” part isn’t only storage; it’s also who gets to define what “useful” means. and that’s where the protocol design starts to matter. if anyone can contribute anything, you need a cheap filter. if the filter is expensive (human review, heavy compute checks), the network quietly recentralizes into a few gatekeepers or “curation syndicates.”attribution + reward mechanism
and this is the part i keep thinking about. attribution is the core promise: contributors get paid because their data actually creates downstream value. but measuring that in ml is not clean. even in closed systems, assigning credit to a dataset or a labeling run is fuzzy. on-chain, you now have adversaries who will actively try to manufacture “credit.” so i’m trying to understand what openledger’s practical attribution target is: is it “proof of inclusion” (your data was in the training set), “proof of usage” (your dataset was purchased/accessed), or something closer to “proof of impact” (your data measurably improved model performance)?
those are wildly different in terms of verification cost and attack surface. proof of purchase is easy but gameable. proof of impact is meaningful but potentially too expensive, and it raises questions like: who runs the evals? how do you stop someone from overfitting attribution tests? what’s the dispute process if a contributor claims credit and a model builder disputes it?
marketplace dynamics between data and model builders
the project implies a market where model builders source data (or maybe “data products”) with provenance and licensing clarity. i can see a realistic use case: a team fine-tuning a customer support model for a regulated industry wants a dataset of annotated tickets, plus a trail that shows consent/licensing, labeling lineage, and how updates were made. centralized platforms can provide that with internal logs, but you’re trusting the platform and you usually can’t port the reputation/attribution elsewhere. openledger’s bet is that provenance + payment rails become portable infrastructure.
still, this assumes enough buyers value provenance enough to pay for it, not just say they do. i’m not sure how deep that market is today, outside specific compliance-heavy niches.
token incentives + network coordination (plus scalability/verification)
the token seems to coordinate who contributes, who verifies, and who earns. the long-term design question is whether incentives converge toward real utility or stay stuck on proxy metrics (uploads, labels, “activity”). if early rewards are mostly emissions, you can bootstrap supply fast, but you also train contributors to chase payouts rather than quality. then the verification layer has to do more work (and more work costs money). there’s a tight coupling here: weak verification → spam; strong verification → higher overhead and possible centralization.
so who creates value? contributors do, but only if buyers show up and pay repeatedly. model builders create value too, because they’re the ones turning data into revenue-generating models. the protocol’s role is basically to reduce trust costs (provenance, attribution, settlement) enough that it’s worth coordinating on-chain instead of just signing contracts and using a normal data vendor.
my main concern is incentive misalignment under low demand. if buyer spend is thin, the token has to subsidize everything, and attribution becomes a fight over a small pie. that’s where low-quality data, sybil contributions, and “wash usage” (fake purchases to farm rewards) can show up fast.
no perfect conclusion yet. i’m still undecided on whether openledger can keep attribution trustworthy without making verification so heavy that only a few actors can run it.
watching:
share of contributor rewards funded by real buyer fees vs emissions
cost to verify/curate a new dataset over time (does it trend down?)
frequency of repeat purchases / reuse of the same data assets
evidence of effective anti-spam measures (sybil resistance, disputes resolved cleanly)
if attribution ends up being “good enough” rather than perfect, what’s the minimum viable version that still creates a defensible market?