
Let me start with something simple — most people still look at AI systems like neutral machines. You give data, it processes, you get output.
But when you look at @OpenLedger a little differently, that simplicity starts breaking apart.
Because here, data is not just something you throw into a system anymore.
It is something that has to earn its place inside the system.
And that small shift changes everything — not loudly, not visually, but structurally.
And this is exactly where things start getting interesting.
Datanets: Where Freedom Gets Filtered Before Entry
At first look, the contribution layer feels restrictive.
Separate formats. File caps. Daily limits. Strict validation rules.
And the immediate reaction is obvious — this feels less “Web3 freedom” and more “controlled environment.”
But that interpretation misses the point.
Because the system is not trying to maximize freedom of input.
It is trying to maximize survivability of signal.
And those two are not the same thing.
In most open systems, everything is allowed in and filtered later.
Here, filtering begins before entry even happens.
So contribution is no longer just: “upload whatever you have.”
It becomes: “can your data survive the system’s structure?”
And that alone silently reshapes behavior.
Leaderboard Logic: Reputation Built on Acceptance, Not Activity
Now the ranking system reveals a deeper shift.
Most platforms reward volume.
More uploads → more visibility → higher rank.
But here, the logic quietly moves away from quantity.
It focuses on something more subtle:
How often does the system accept what you contribute?
That single metric changes user psychology.
Because now people don’t optimize for spam or scale.
They optimize for:
structural accuracy
consistency
alignment with system expectations
And the most important design detail:
Rejected contributions don’t punish you.
That sounds small, but it completely changes risk behavior.
Because it creates a system where:
experimentation is safe
but noise has no reward
That balance is rare.
ModelFactory: Turning AI Training Into an Iterative ➰ 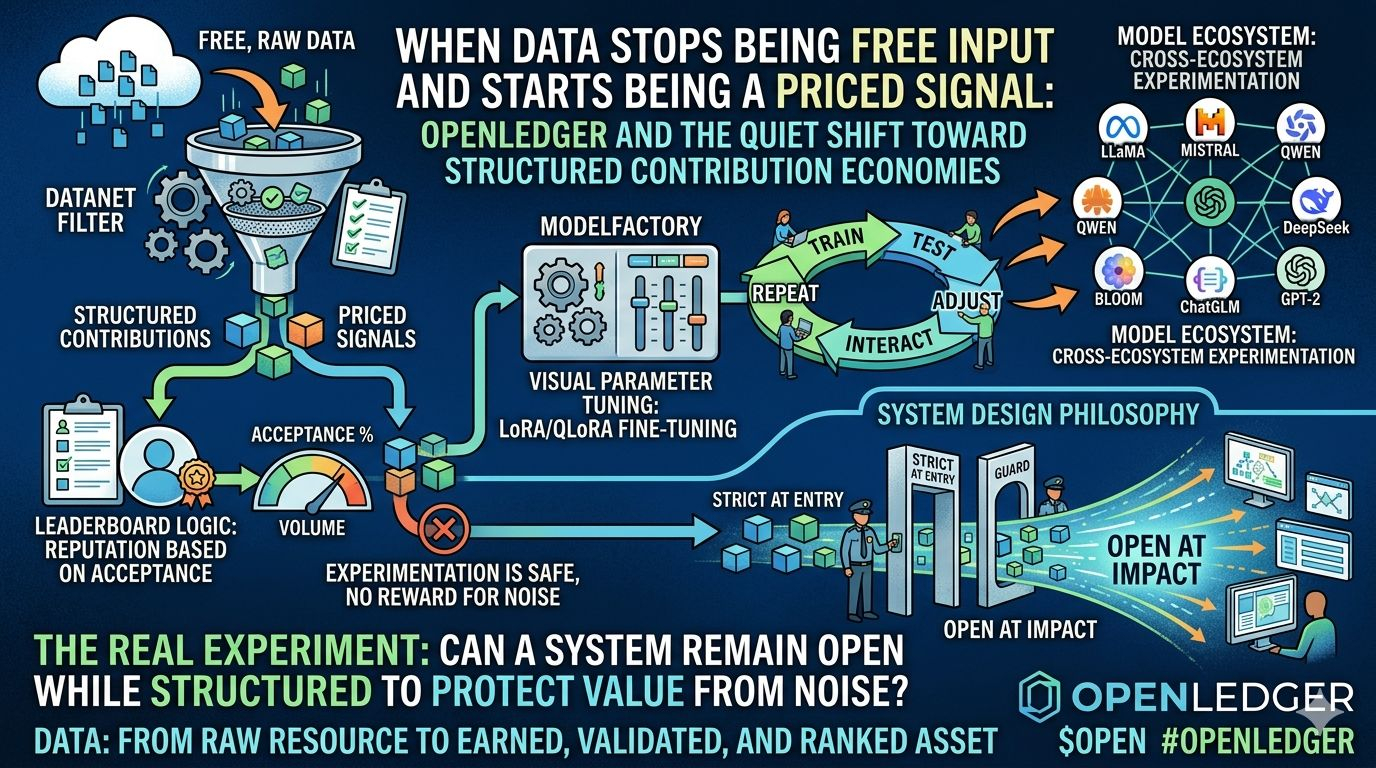
Then the system moves into model development.
But instead of exposing raw engineering complexity, it reshapes it into something more usable:
visual parameter tuning
LoRA / QLoRA-based fine-tuning
real-time training feedback
interactive refinement cycles
At surface level, it feels like simplification.
But structurally, it is doing something deeper.
It is turning model training from a one-time technical process into a continuous feedback loop system.
So the flow is no longer: build → deploy
It becomes: train → test → interact → adjust → repeat
And once that loop becomes the core unit, models stop behaving like static artifacts.
They start behaving like living systems that evolve through interaction.
Model Ecosystem: Expansion Instead of Control
Another subtle but important layer is model diversity.
Instead of locking into a single ecosystem, the system spans:
LLaMA variants
Mistral
Qwen
DeepSeek
BLOOM
ChatGLM
older open models like GPT-2
At first, this looks like broad support.
But structurally, it signals something else:
This is not a closed ecosystem.
It is a cross-ecosystem experimentation layer.
And that matters.
Because closed systems optimize consistency.
But open experimentation layers optimize discovery.
And discovery is where new architectures actually emerge.
System Design Philosophy: Controlled Input, Open Output
If you compress the design into one idea, it becomes this:
Input is tightly structured.
Output is widely observable.
That separation is intentional.
Because most open systems fail not at output — but at input noise.
So instead of cleaning chaos later, this system prevents chaos early.
But once data passes that gate, it is allowed to exist freely in evaluation, ranking, and usage layers.
So the architecture becomes:
strict at entry
open at impact
That combination creates a very specific environment — neither fully decentralized chaos nor fully centralized control.
Something in between.
The Core Shift: Data Becomes a Ranked Asset, Not Raw Material
If you strip everything down, the same idea keeps repeating:
Data is not treated as raw input anymore.
It is treated as something that must go through:
structure
validation
acceptance
ranking
Before it becomes meaningful.
And that transforms its identity completely.
Because now data is not just information.
It is a position inside a system of trust.
And positions can be measured, compared, and rewarded.
Which means the system is no longer just processing data.
It is quietly building a contribution-based economy on top of data itself.
Final Thought: The Real Experiment Is Not AI — It Is Controlled Openness at Scale
Zooming out, OpenLedger is not just another AI infrastructure narrative.
It is experimenting with a harder question:
Can a system remain open while still being structured enough to protect value from noise?
Every layer reflects that tension:
datanet restrictions
acceptance-based ranking
iterative model training loops
multi-model experimentation space
Nothing here is fully free.
Nothing here is fully closed.
And that is exactly the point.
Because the real experiment is not just building AI tools.
It is testing whether structured contribution can become an actual economic layer in AI systems.

And whether data can move from being a raw resource…
into something closer to an earned, validated, and ranked asset inside an intelligence economy.