
Beleza, deixa eu te dizer uma coisa no começo - quando você olha para esses tipos de sistemas, você pensa primeiro "tá tudo controlado, regras rígidas, restrições..." Mas se você olhar mais a fundo, dá pra entender que aqui não é bem um caos, mas sim uma tentativa de criar uma estrutura intencional - é isso mesmo.
Se eu falar a verdade do fundo do meu coração.... A forma como eu leio @OpenLedger a documentação, em uma linha - não é só uma IA ou uma plataforma de dados, mas um experimento em toda a ideia de como os dados podem ser um "ativo ganho". Agora vamos destrinchar isso porque se você juntar tudo, não vai caber na sua cabeça - não vai caber de jeito nenhum.
Primeiro vem a camada de Contribuição dos Datanets.
A coisa mais interessante aqui são as restrições. Texto, imagens, áudio - você não pode misturar tudo. Parece um pouco estranho, porque quando falamos de Web3, geralmente pensamos em tudo sem permissão. Mas aqui é o oposto - formato rigoroso, validação rigorosa. Limite de 10 MB por dia, 20 arquivos - isso também parece pequeno, mas na verdade não é controle de spam, mas sim uma tentativa de manter a relação sinal-ruído correta. Porque se for ilimitado, todo mundo vai contribuir, mas será difícil encontrar valor.
Outra coisa que parece um pouco engraçada - o sistema de leaderboard.
Você pode estar pensando "quanto mais eu faço upload, mais alto eu vou" - mas não, de jeito nenhum. Aqui, não é a quantidade que importa, mas a taxa de aceitação. Quero dizer, se você der 10 dados errados, seu ego pode ficar feliz, mas o sistema não vai se importar com você. Um pouco duro, mas justo. E a parte interessante é que arquivos rejeitados não reduzem a classificação. Este é um design estranhamente saudável. Porque a experimentação é incentivada aqui, não a contribuição movida pelo medo.
Então vem a mecânica do ModelFactory.
Esta é, na verdade, a parte mais séria do OpenLedger. Ela muda completamente a vibe aqui. Eles estão tentando transformar o ajuste fino de LLM em um fluxo de trabalho guiado por interface ao invés de apenas mantê-lo como uma ferramenta de pesquisa. Isso significa que você não precisa ser um guerreiro de terminal. Taxa de aprendizado, tamanho do lote, época - tudo pode ser ajustado visualmente. À primeira vista, parece - ok, amigável para iniciantes, mas na verdade há uma ideia mais profunda por trás disso - democratizar o desenvolvimento de IA sem perder o controle.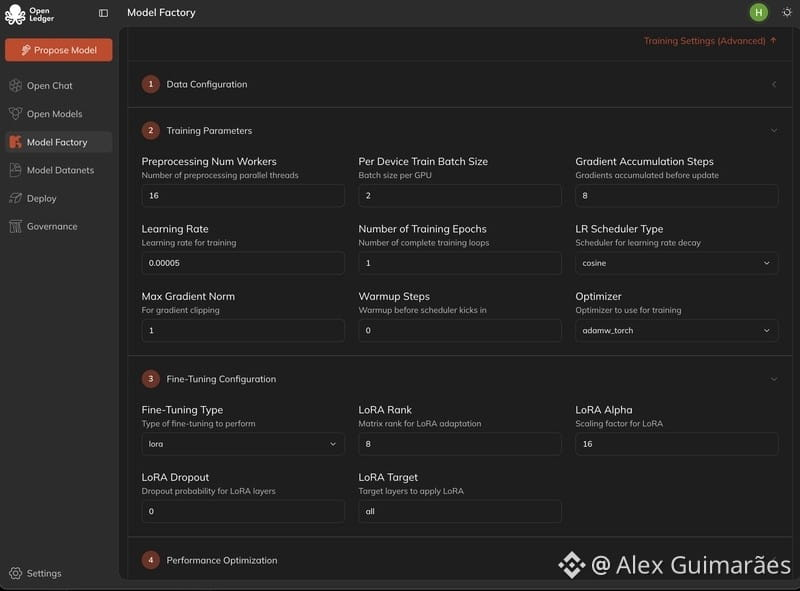
O suporte a LoRA e QLoRA é um movimento prático aqui. Porque o ajuste fino completo é caro na realidade de hoje. Então eles estão seguindo um caminho de adaptação leve. Painel em tempo real e interação pós-treinamento - essa coisa é bastante interessante, porque eles querem fazer o treinamento de modelos um loop contínuo sem deixar um ponto final. Isso significa treinar ⇨ testar ⇨ interagir ⇨ refinar.
Agora vamos falar sobre os LLMs suportados.
Deepseek, Mistral, Qwen, série LLaMA - todos os grandes ecossistemas abertos estão aqui. Até o GPT-2, BLOOM, ChatGLM são suportados. A princípio, pode parecer que eles incluíram tudo, mas na verdade é uma estratégia de cobertura de ecossistema. Porque se você mantiver apenas modelos de elite, ficará limitado. Mas um suporte amplo significa um grande espaço para experimentação.
Agora deixa eu te contar uma parte engraçada
Uma imagem vem à minha mente quando vejo todo esse sistema - uma cozinha muito disciplinada, onde ninguém pode jogar ingredientes aleatoriamente. Mas quando o cozimento termina, todos podem provar e avaliar. Isso significa que você não pode sobreviver aqui apenas com boas vibrações, mesmo que queira.
A última parte das Instruções do Agente é, na verdade, a mais subestimada.
Porque aqui se diz que, para consultas profundas, respostas dinâmicas podem ser obtidas usando a URL do GitBook. Não são basicamente documentos estáticos, mas sim um sistema de conhecimento consultável.
Agora, se você pensar sobre isso de forma geral, uma coisa fica clara..... @OpenLedger na verdade está entre duas tensões: por um lado, descentralização + contribuição aberta, por outro lado, validação rigorosa + estrutura controlada. Não é fácil manter essas duas coisas juntas. Mas se o equilíbrio estiver certo, então pode criar uma verdadeira economia de dados ao invés de ruído. E, para ser honesto, é aqui que a questão se torna interessante - os dados realmente serão um ativo do futuro, ou estamos apenas tentando resolver um antigo problema de validação com um novo nome?
Não tenho certeza se há uma resposta final agora. Mas como uma camada de experimentação, não vale a pena ignorar... Mas realmente🚀