i still remember the first time I tried to build something useful for my own trading.
Nothing complicated. Just a simple tool to track wallet movements across a few tokens I was watching, combine that with sentiment signals, and give me an alert when something unusual happened. I had the logic figured out in my head. But turning that logic into something that actually worked — connecting the data sources, handling the APIs, making sure the signals were clean and not just noise — that took longer than the trade idea itself was worth. I eventually gave up and went back to watching charts manually like everyone else.
That memory came back when I started reading about OpenLedger's trading agent and what it is actually trying to do.
Not because it sounds exciting. Because it touches a frustration I think most traders have but rarely say out loud — the gap between what we can imagine and what we can actually build and trust.
so let me think through this properly....
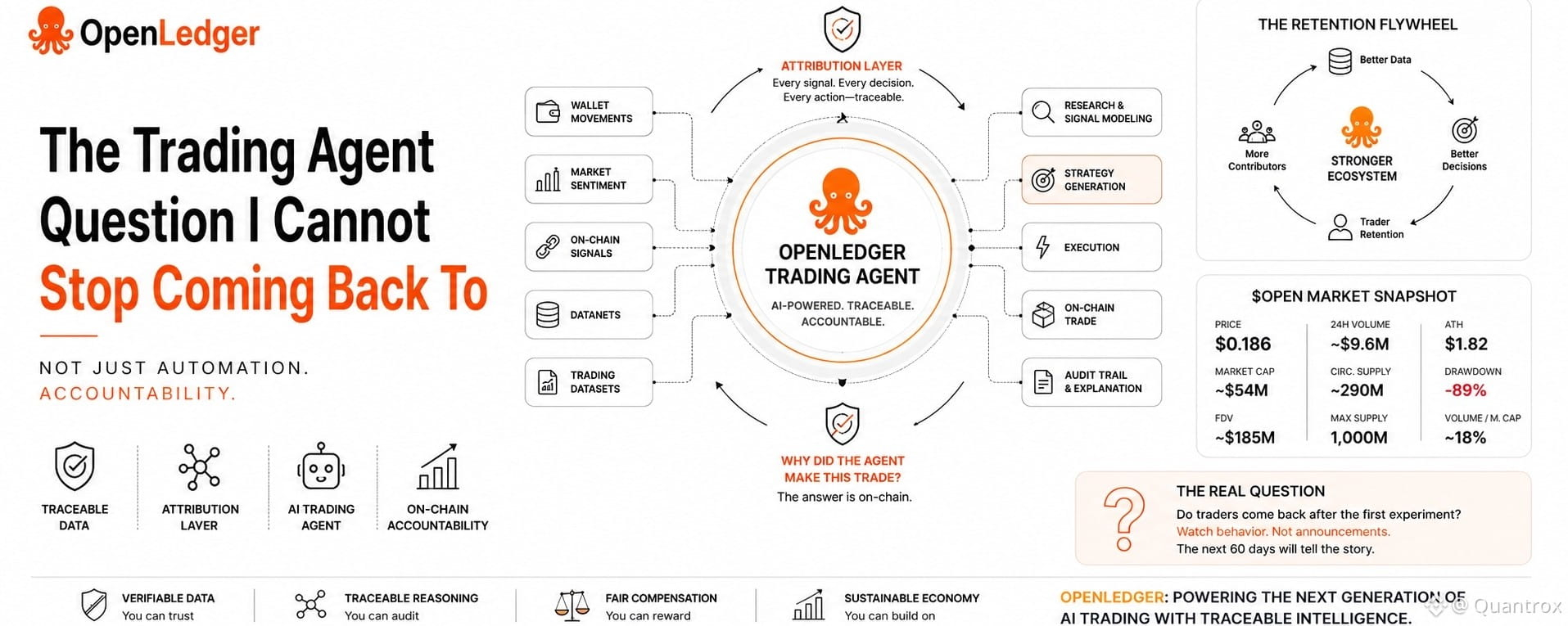
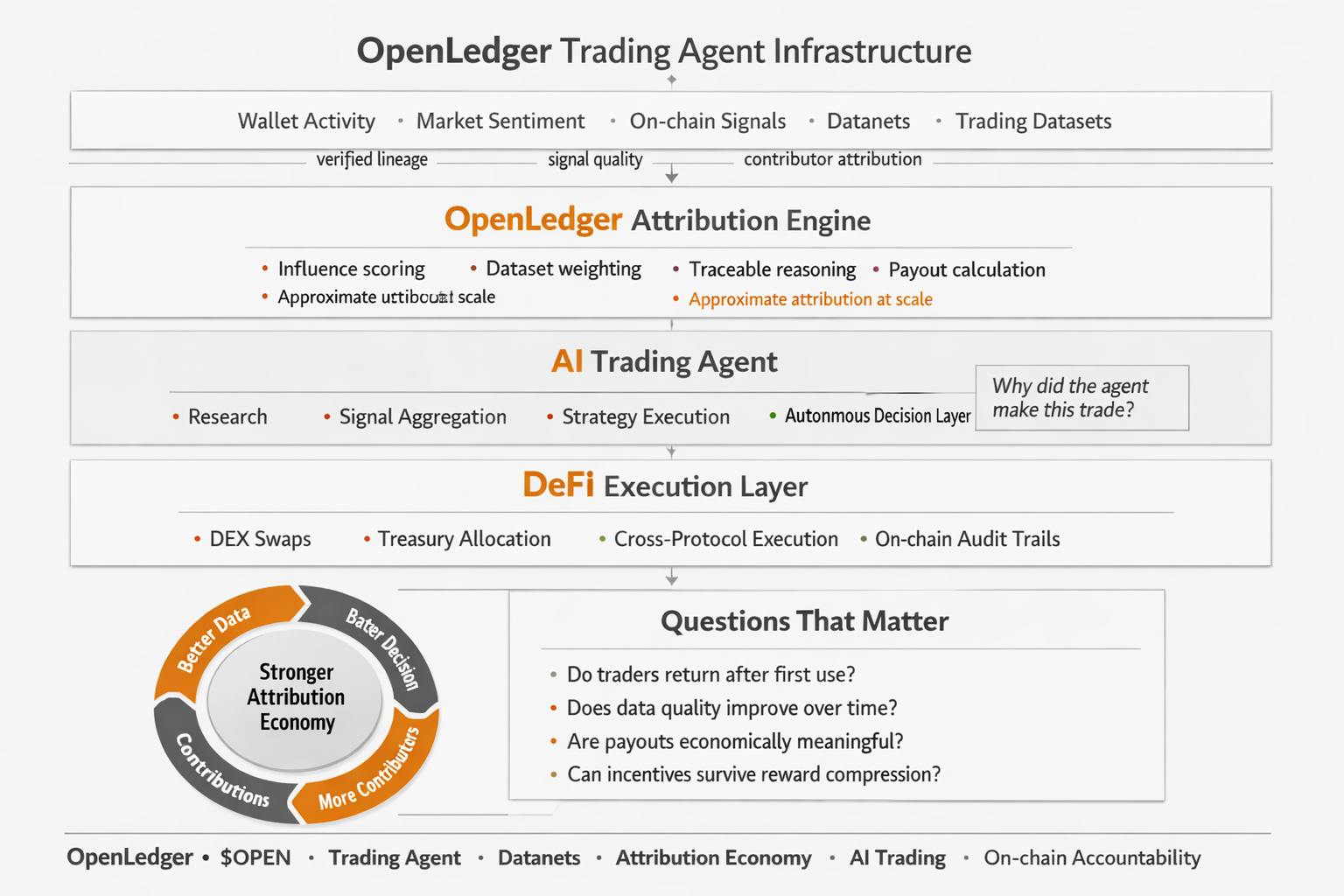
The idea behind OpenLedger's trading agent is not just automation. Lots of things automate trades. What makes this different — at least in theory — is the attribution layer sitting underneath. When a trading agent executes through OpenLedger's infrastructure, the data that informed each decision is traceable. Which datasets contributed to the model's market view. Which signals shaped the output. That chain stays intact rather than disappearing inside a black box.
For a solo trader that might sound like a nice technical detail. But for anyone deploying real capital, it changes the accountability structure entirely. If a position goes wrong you can ask why the agent made that call — and the answer is on the chain rather than in someone's approximation of what probably happened.
That is genuinely different from anything I have seen in AI-driven trading before.
but here is where I slow down and get a little uncomfortable....
The data feeding these trading models has to come from somewhere. And whoever contributed that data needs to be identifiable and compensatable for the attribution system to actually work. That requires a supply of verified, attributed datasets that are good enough to produce real alpha — not just recycled public information that any trader can already access for free.
Does OpenLedger have that supply yet ? Honestly I am not sure. The infrastructure exists. The Datanets concept exists. But the gap between infrastructure existing and high quality attributed trading data actually flowing through it — that gap is not small and I do not think it closes quickly.
and then there is the noise problem which I find even harder to dismiss.....
Making it easier to contribute data also makes it easier to contribute bad data. Anyone who has spent time in crypto incentive systems knows how fast reward hunters flood any open contribution mechanism with low effort or duplicated inputs. OpenLedger needs quality filters that are strong enough to keep the attribution economy healthy without being so restrictive they kill participation. That balance is genuinely difficult to get right.
I keep coming back to the numbers while sitting with all of this.
looking at the numbers right now, OPEN is trading at $0.1928 on the 4H chart, up 3.82% in the last 24 hours. 24h high touched $0.1939 and low was $0.1741, with volume at 11.13M OPEN and $2.06M USDT. Price is currently sitting above EMA20 at $0.1898 but still below EMA50 at $0.1944 and EMA200 at $0.2024. MACD is showing a very slight positive cross — DIF at -0.0045, DEA at -0.0048, MACD histogram at 0.0002 — suggesting early momentum shift but nothing confirmed yet. RSI at 50.91 is right at the midline, neutral. MA5 at 2.05M running above MA10 at 1.5M shows recent volume pickup. The structure looks like price is attempting to stabilize after the sharp rejection from 0.2423, but it needs to reclaim EMA50 convincingly before any recovery thesis holds technically.
The realistic bull case for me is not complicated. At $54 million market cap, if the trading agent and Datanets actually attract builders and data contributors who keep returning after incentives fade — not because rewards are available but because the platform gives them something they cannot get elsewhere — then a re-rating toward $100-150 million market cap is not a fantasy number. That would imply a price somewhere between $0.34 and $0.52 on current circulating supply.

but the bear case is simpler and I cannot ignore it.
If the trading agent becomes another tool that people test once and never return to — if data contributors show up for the token incentives and disappear when rewards compress — then the current market cap is already pricing in more adoption than actually materializes. That pattern has played out in this space many times. Infrastructure that looks compelling in architecture diagrams but never achieves sticky usage.
The retention question is where I keep landing every time I think about OpenLedger.
do traders who use the trading agent come back to it after the first experiment ? Do data contributors keep adding valuable information when token rewards are not the primary reason to click ? Does the attribution system produce payouts that feel fair and meaningful to real contributors — not just technically correct but economically motivating ?
Those questions cannot be answered from a whitepaper or a GitBook. They can only be answered by watching behavior over time.
so I am not treating OpenLedger's trading agent as a guaranteed breakthrough. I am treating it as a serious experiment at the intersection of AI, data ownership, and automated finance. That intersection is real and important. Whether this specific implementation captures it in a way that produces durable usage — that I genuinely do not know yet.
Watch whether real traders build real tools and come back. Watch whether attributed data quality improves over time. Watch volume against market cap across the next sixty days not just the next announcement.
That is where the actual answer is.