Honestly, I’ve gotten tired of most AI crypto projects.
Not because AI is fake. And not because blockchain suddenly stopped mattering. That’s not it.
I’m tired because every project keeps showing the same giant ecosystem diagrams pretending complexity automatically means progress. You’ve probably seen them too. Some glowing chart with arrows flying everywhere:
data layer,
compute layer,
agent layer,
settlement layer,
orchestration layer,
governance layer.
And somewhere in the middle there’s always a token floating around like it magically ties the whole thing together.
I’ve seen this before.
A lot of these systems look impressive for about ten minutes. Then you start asking simple questions and everything gets weird fast.
Who actually gets paid here?
Who owns the value once AI starts generating money?
Why would contributors keep feeding the system if bigger players eventually absorb all the upside anyway?
That’s the part people keep avoiding.
And honestly, that’s where OpenLedger started catching my attention.
Not because it screams “look at our AI.” Everybody does that now. AI has become the default marketing wrapper for almost every new crypto infrastructure project. Half the market feels like it’s throwing “AI agents” onto dashboards and hoping nobody asks deeper questions.
But OpenLedger seems focused on something way more important underneath all of that.
Coordination.
That’s the real bottleneck. Not intelligence alone.
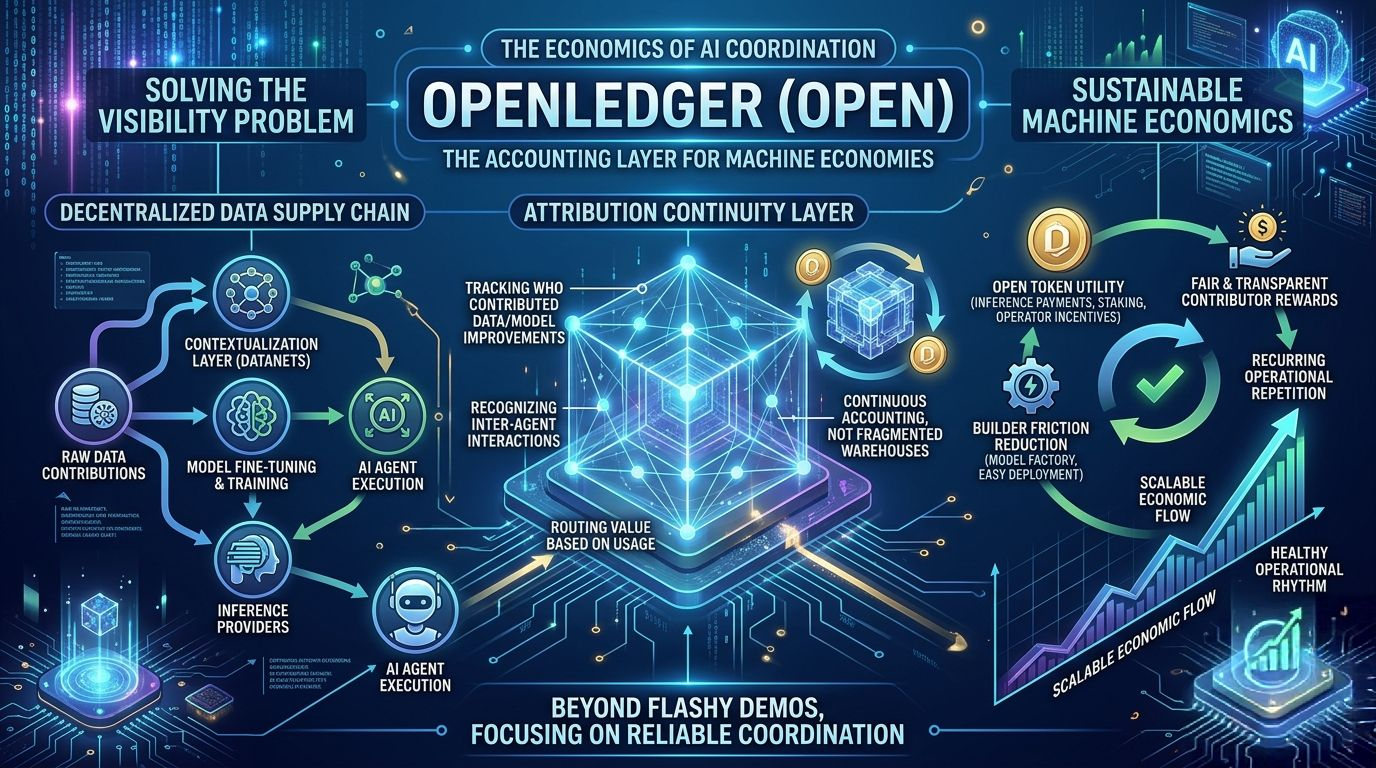
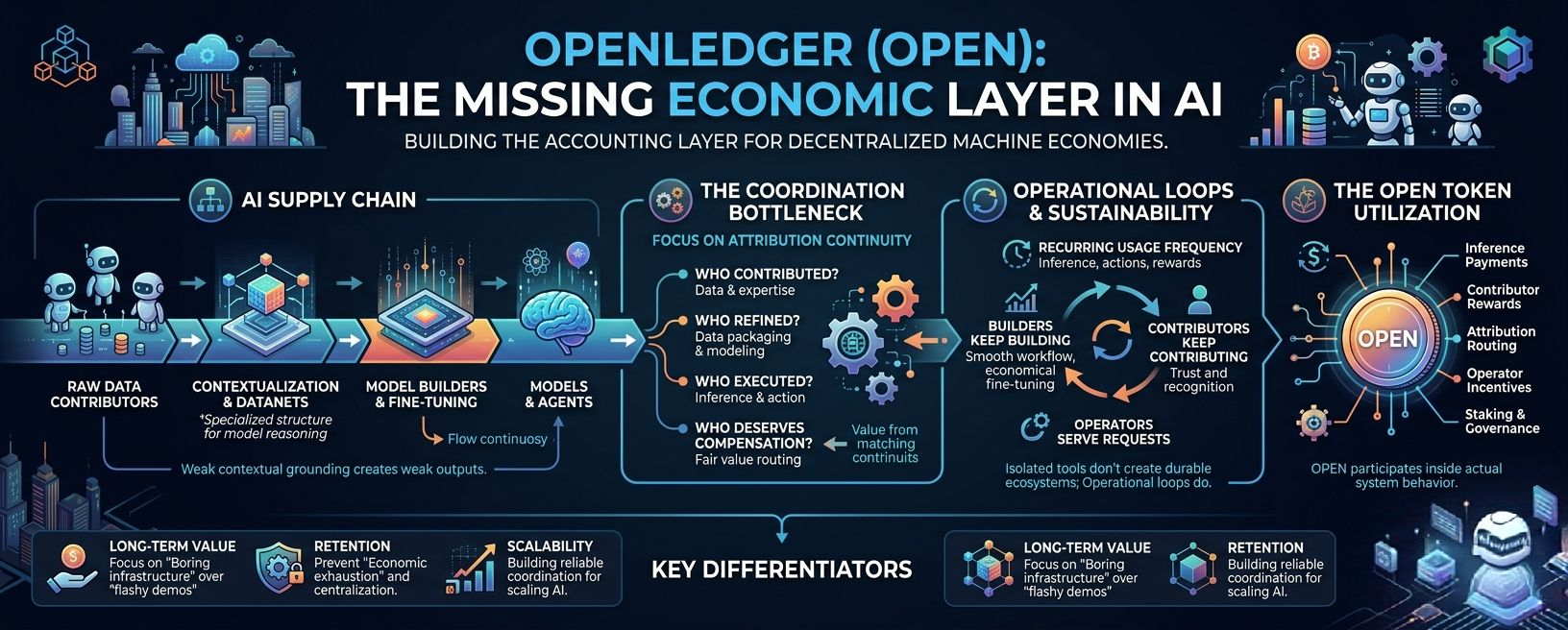
Because look… AI systems aren’t just models anymore. They’re supply chains. Huge ones.
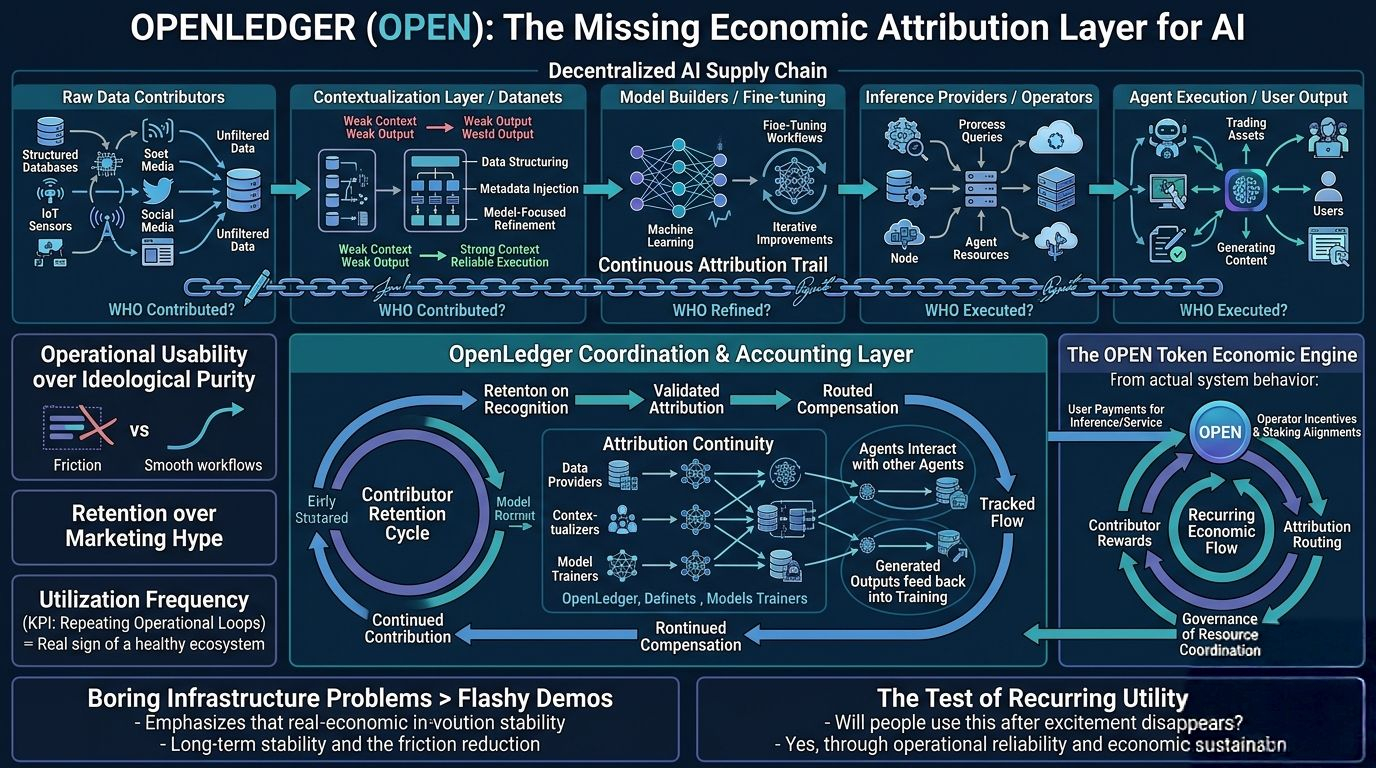
You’ve got raw data contributors. Then contextualization layers. Then model builders. Then fine-tuning workflows. Then inference providers. Then agents executing actions on top. Then users interacting with outputs. Then revenue flowing somewhere afterward.
Or at least it’s supposed to.
The problem is that most systems completely lose attribution once value starts appearing.
And people don’t talk about this enough.
The closer someone sits to the raw material layer, the easier they become to erase economically. That’s been happening in Web2 AI for years already. Companies absorb datasets, models improve, interfaces make money, and suddenly nobody remembers who actually fed the machine in the first place.
That creates a nasty long-term problem.
Because contributors eventually stop contributing.
Why wouldn’t they?
If people feel invisible inside the value chain, they leave. Then the data quality weakens. Then the outputs weaken. Then users lose trust. Then the whole system slowly starts hollowing itself out from underneath.
And the scary part? Sometimes the front-end still looks polished while the internals are dying.
That’s where OpenLedger gets interesting.
The project seems less obsessed with building another flashy AI interface and more focused on building the accounting layer underneath machine economies.
That’s a way harder problem, by the way.
And honestly? It’s also a much more boring one.
But boring infrastructure problems usually matter more long term than flashy demos. History keeps proving that over and over again.
OpenLedger’s whole direction seems built around attribution continuity. Meaning:
who contributed,
who refined,
who executed,
and who deserves compensation once value moves through the system.
That sounds simple until you realize how messy this becomes once AI agents start interacting with other agents, models start training on generated outputs, and distributed contributors all feed the same ecosystem simultaneously.
Things get complicated fast.
And here’s the thing most people miss…
The architecture only really makes sense when you stop viewing the components as separate products.
A lot of crypto infrastructure projects accidentally build fragmented warehouses instead of functioning systems. One platform stores data. Another hosts models. Another handles payments. Another launches agents. Everything technically exists, but nothing actually compounds together.
OpenLedger feels like it’s trying to connect the entire production flow instead.
That matters.
Because isolated tools don’t create durable ecosystems. Operational loops do.
The data side is a good example.
Raw data alone isn’t enough anymore. Honestly, huge amounts of raw data are becoming kind of commoditized. The internet already has endless information floating around everywhere. Most of it is noisy garbage without proper structure.
Context matters more now.
Actually, scratch that. Context is probably the entire game.
That’s why specialized contextual systems — things like Datanets and model-focused data organization — matter so much more than people realize. You’re not just dumping information into storage and hoping models figure it out magically.
You’re packaging information into environments models can actually reason through effectively.
Big difference.
Because weak contextual grounding creates weak outputs. Period.
You can build the slickest AI interface in the world, but if the underlying informational structure is messy, the system eventually starts hallucinating confidence instead of producing reliable execution.
And honestly, this is where a lot of AI products quietly fail.
They look intelligent during demos.
Then real users show up.
That’s when everything gets exposed.
OpenLedger seems to understand that models and agents are downstream behavior. They aren’t the foundation. They’re the visible surface sitting on top of invisible coordination layers.
That’s an important distinction.
The current market loves agents because they’re easy to visualize. Autonomous agents sound futuristic. People can imagine them doing tasks, making decisions, trading assets, coordinating workflows.
Cool.
But agents are only as reliable as the infrastructure feeding them.
Bad contextualization? Weak outputs.
Poor attribution? Contributor decay.
Expensive deployment? Builder fatigue.
Messy fee routing? Ecosystem distrust.
Everything connects.
That’s why I think OpenLedger’s model factory idea matters more than people think too.
Not because “model factories” sound exciting. Honestly the name itself doesn’t matter.
What matters is reducing friction.
That’s the real battle in infrastructure.
Builders tolerate complexity during early experimentation because everybody’s excited in the beginning. But once the hype cools down? Different story entirely.
Developers start asking practical questions:
How expensive is testing?
How painful is deployment?
Can I fine-tune cheaply?
Can I iterate fast?
Does this infrastructure save me time or create more overhead?
And this is where things get tricky.
A lot of decentralized systems accidentally destroy themselves chasing ideological perfection instead of operational usability. They optimize for purity while builders quietly leave for systems that simply work better.
That happens constantly.
People don’t stay loyal to infrastructure because it sounds philosophically correct. They stay because the workflow feels smooth and economically sustainable.
That’s it.
OpenLedger’s long-term survival probably depends heavily on whether it can keep onboarding lightweight while still preserving decentralized contribution incentives underneath.
Not easy.
Actually really hard.
Especially once recurring operational costs enter the picture.
And that brings us to the token side of this whole thing.
Because let’s be real… this is usually where AI crypto projects completely lose me.
Most tokens still feel decorative. They sit on top of ecosystems instead of inside them.
OpenLedger only works long term if OPEN continuously participates inside actual system behavior:
inference payments,
contributor rewards,
attribution routing,
operator incentives,
staking alignment,
governance tied to resource coordination.
Otherwise the token eventually drifts away from productive activity and becomes pure narrative fuel.
We’ve already seen that movie.
Multiple times.
What actually matters is recurring economic flow.
How often do models execute?
How often do agents trigger actions?
How often do contributors receive compensation?
How often does fee distribution happen across the network?
That repetitive behavior is the real signal.
Not social engagement metrics.
Not hype cycles.
Not ecosystem maps.
Usage frequency.
That’s the KPI that matters.
Because healthy infrastructure creates rhythm. Constant operational movement. Builders building. Contributors contributing. Operators serving requests. Users generating recurring demand.
When those loops stabilize, ecosystems start behaving like actual infrastructure instead of speculative experiments.
And honestly, OpenLedger’s attribution layer might be the most important piece in that entire machine.
Not because “fairness” sounds nice.
Because retention depends on it.
If contributors trust the system to recognize and route value properly, they keep participating. If they don’t, they leave early and the ecosystem slowly centralizes toward whoever controls distribution.
That’s the cold reality most people ignore.
Decentralization doesn’t disappear overnight. It erodes gradually through economic exhaustion.
Smaller participants leave first.
Then the network loses diversity.
Then resilience weakens.
Then the ecosystem becomes increasingly dependent on a smaller group of dominant operators.
OpenLedger seems like it’s actively trying to prevent that cycle before it fully emerges inside decentralized AI systems.
Now… does that guarantee success?
Not even close.
This market is brutal.
Technically strong systems fail all the time. Sometimes adoption comes too slowly. Sometimes operational complexity quietly kills momentum. Sometimes users simply don’t care enough to change behavior.
And honestly, AI infrastructure itself is still immature.
A lot of these systems haven’t faced real long-term usage pressure yet. They haven’t experienced sustained production-scale behavior across contributors, agents, inference layers, and economic routing simultaneously.
That pressure changes everything.
Eventually every infrastructure project reaches the same uncomfortable checkpoint:
Can this system generate enough recurring utility that people continue using it after the excitement disappears?
That’s the real test.
Not launch hype.
Not influencer threads.
Not token speculation.
Operational repetition.
And I think that’s why OpenLedger feels more interesting than most AI crypto narratives right now.
It’s not really trying to sell intelligence as magic.
It’s trying to solve the invisible coordination mess underneath machine economies.
Who contributed.
Who refined.
Who executed.
Who earned.
Honestly, that accounting layer might end up mattering more than the models themselves over time.
Because AI is getting cheaper. Models keep improving everywhere. Interfaces multiply fast. Agent frameworks show up every week.
But reliable attribution infrastructure?
Trusted economic coordination?
Continuous contributor incentives?
That stuff still looks unresolved.
And if decentralized AI ever scales seriously, those problems won’t stay optional.
They’ll become foundational.