
我最近在思考一个问题:为什么去中心化AI赛道跑了两年,至今没有一个项目真正解决了数据贡献者的持续激励问题。答案其实很简单——因为没有人做出过一套可执行的链上归因系统。直到我深入研究了@OpenLedger 的Proof of Attribution机制,我才意识到这个问题的解法已经出现了。#OpenLedger $OPEN
归因证明的本质不是确权,而是定价
市面上很多项目都在讲数据确权,但确权只是第一步,它解决的是这是谁的,解决不了这值多少钱。OpenLedger的归因证明真正的突破在于,它建立了一套基于Feature-level Influence的动态定价引擎。每一次AI推理发生时,系统会实时计算每条底层数据对该次输出的特征级贡献权重,而不是简单地按调用次数或文件大小来分配收益。
这意味着同一份数据在不同的推理场景中,价值是浮动的。当你的数据恰好是某次关键决策的核心依据时,你获得的$OPEN N分成会显著高于它仅作为背景参考时的收益。这种机制第一次让数据的市场价格由真实的使用价值决定,而非由平台单方面定价。
对比当前主流的数据激励模式:Ocean Protocol采用的是数据集整体定价+一次性交易模型,Filecoin解决的是存储层而非价值层,即便是Bittensor的激励机制,本质上也是对矿工算力贡献的奖励,而非对原始数据贡献者的归因。
OpenLedger的差异在于它把归因颗粒度下沉到了推理层。不是你的数据集被买了一次,而是你的数据集中的第47条记录在今天下午3点的第1893次推理中贡献了38%的决策权重。这个颗粒度的差距不是量变,是质变。它让数据从被消费的商品变成了持续产生收益的生产性资产。
从代币经济学角度分析这套机制的自洽性:数据贡献者质押$OPEN EN参与生态→高质量数据吸引开发者构建AI模型→模型被付费调用产生推理收入→归因引擎将收入按贡献度分配回数据贡献者→贡献者获得正向回报后持续提供更优质数据。
这个循环中每一个环节都在消耗OPEN:质押需要锁定代币、模型调用需要支付代币、归因结算需要Gas消耗。再叠加白皮书中提到的每周回购销毁机制和每笔交易1%的固定销毁率,代币的流通供给在持续收缩。当推理调用量随着生态扩张而增长时,OPEN面临的是需求扩张与供给收缩的双重挤压。
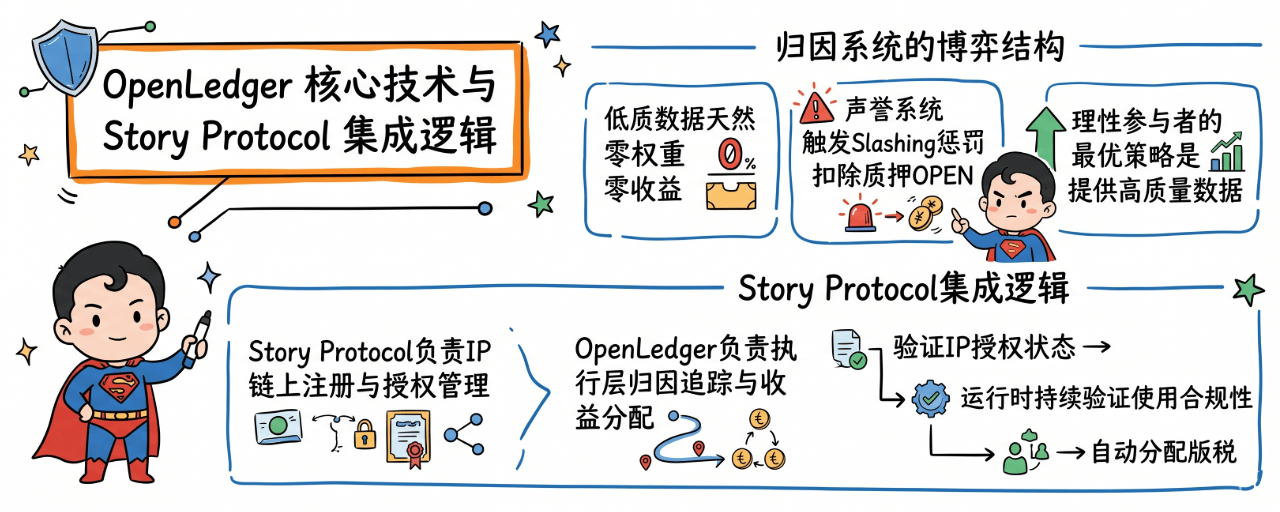
归因系统最大的潜在攻击面是数据污染——恶意参与者灌入大量低质数据试图稀释分成。OpenLedger的应对不是靠人工审核,而是靠机制本身的博弈结构:低质数据在Feature-level Influence评估中天然无法获得权重,零权重意味着零收益;同时贡献者声誉系统会对持续提供无效数据的地址触发Slashing惩罚,直接扣除其质押的OPEN。
这构成了一个纳什均衡:理性参与者的最优策略永远是提供高质量数据,因为作恶的期望收益为负。不需要中心化裁判,经济激励本身就是最好的过滤器。
值得单独分析的是OpenLedger与Story Protocol的集成逻辑。Story Protocol负责IP的链上注册与授权管理,OpenLedger负责执行层的归因追踪与收益分配。两者结合后形成的闭环是:AI系统在训练阶段必须验证数据的IP授权状态→运行时通过加密手段持续验证使用合规性→归因引擎自动向版权持有者分配版税。
据世界知识产权组织数据,全球IP市场估值超过80万亿美元。这个合作意味着OpenLedger不仅在解决Crypto原生的数据激励问题,更在切入传统IP版权这个量级远超当前DeFi总TVL的庞大市场。
Proof of Attribution对于OpenLedger的意义,类似于AMM对于Uniswap的意义。它不是一个功能,而是整个协议存在的理由。没有可执行的链上归因,去中心化AI的数据供给侧就永远是一个冷启动问题。OpenLedger是我目前看到的唯一一个把这件事从论文级概念做到了工程级实现的项目。
这个赛道最终的竞争不是比谁的叙事更好听,而是比谁的归因引擎能处理更大规模的并发推理、更细颗粒度的贡献追踪、更低延迟的实时结算。从白皮书披露的架构来看,OpenLedger在这三个维度上都做了针对性的工程优化,这是它相对于同赛道其他项目最核心的结构性优势。@OpenLedger