
作为一个习惯了对技术狂热保持距离的独立观察者,我最近看 AI 圈子的狂欢,总有一种强烈的不安感。
所有人都在为更大规模的算力池、新一代的英伟达芯片和突破性的参数量欢呼。但如果你剥开这些华丽的外衣,仔细凝视底层结构,你会发现当前 AI 发展正踩在一个极其脆弱的基石上——我称之为 AI 模型的“隐性记忆”危机。
让我用一个最通俗的例子来解释。想象你雇佣了一个拥有过目不忘能力的超级实习生。他读遍了所有的机密文件、商业机密和版权材料。当他为你工作时,他能给出完美的答案。但当你问他:“你这个结论是从哪份文件里学来的?”他却一脸茫然。如果他无意中泄露了致命的商业机密,你根本无从查证信息的源头,更别提去追责。
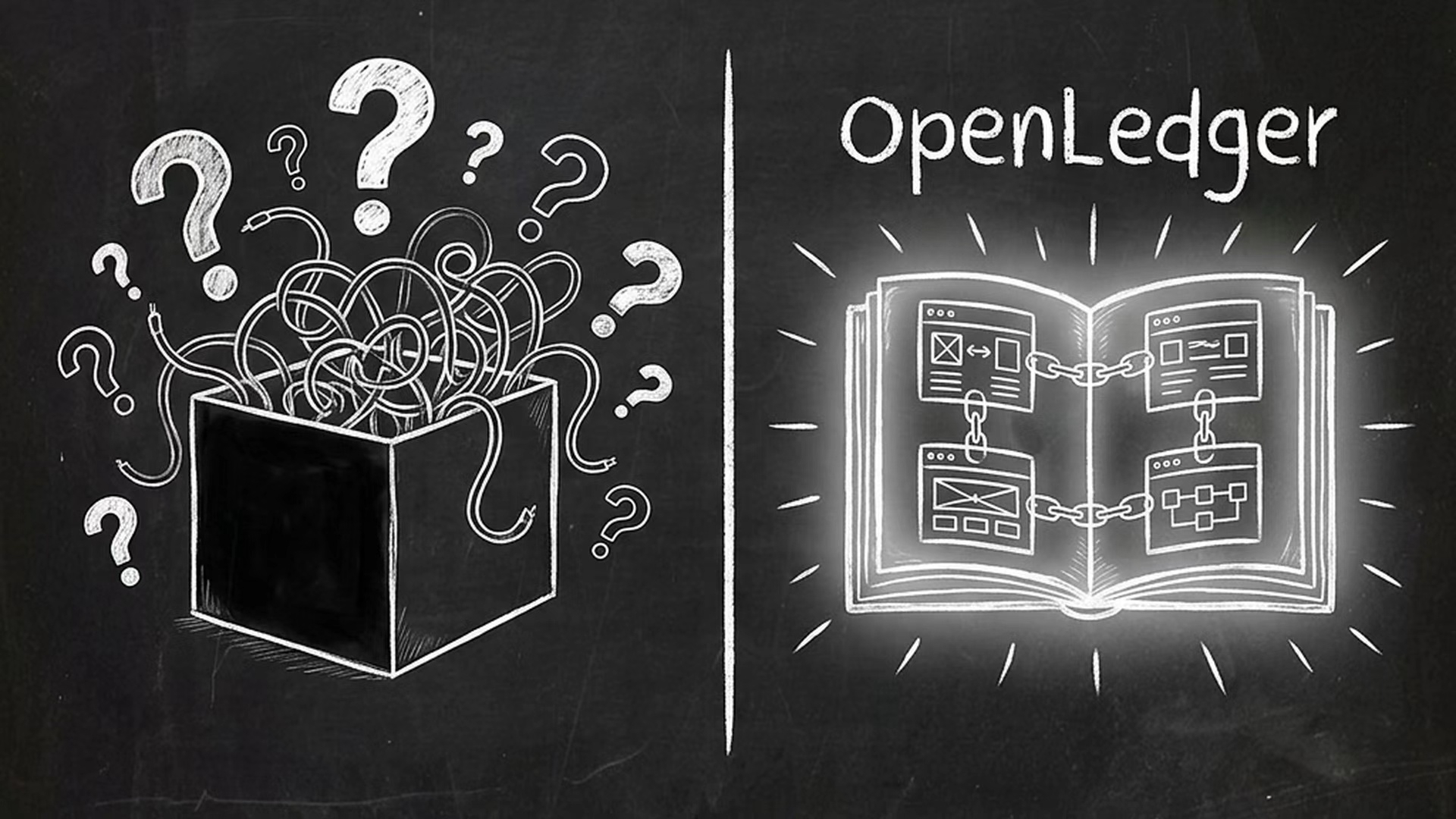
这恰恰是当前大语言模型(LLM)的现状。它们通过吞噬海量数据获得了“智能”,但这些数据是如何转化为权重分布的,完全是一个黑盒。当一个模型生成了带有偏见的内容、侵犯了某位艺术家的版权、或者输出了被恶意投毒的有害信息时,没人能说清楚到底是哪条数据出了问题。
这种“隐性记忆”正在从一个技术缺陷,演变成重大的系统性安全与合规风险。传统的 Web2 AI 巨头们(比如 OpenAI 或 Google)不仅无力解决这个问题,某种程度上,他们甚至在刻意维持这个黑盒,因为一旦数据溯源变得透明,接踵而至的将是无尽的版权诉讼和监管铁锤。

这就是为什么我最近开始深入研究 @OpenLedger 的原因。
很多人一听到 Web3+AI,第一反应就是“发个币去租算力”,这太过于表面了。OpenLedger 真正试图切入的,是 AI 产业链中最脏、最累、但也最核心的命脉:数据溯源与问责制(Data Provenance & Accountability)。
在 OpenLedger 的架构中,AI 训练不再是一个不可追溯的黑盒“炼丹炉”。他们利用区块链的不可篡改性,构建了一个去中心化的数据层。这意味着,每一批被用于训练的数据,它的来源、质量、贡献者,甚至模型权重更新的历史,都会被加密哈希并记录在链上。$SLX
这带来了一个根本性的范式转换:把 AI 的“隐性记忆”变成了“显性账本”。
当未来一个由 OpenLedger 支持的 AI 模型输出内容时,理论上你可以通过链上记录,实现逆向的“推理归因(Inference Attribution)”。你能追溯到这个答案背后依赖了哪些高质量的数据源。这不仅解决了模型问责的安全问题,还顺带跑通了 Web3 最擅长的经济模型——为数据提供者进行精准的代币激励(Tokenized Incentives)。
然而,作为一个见证过无数概念死亡的老玩家,我必须泼一盆冷水。
OpenLedger 描绘的愿景非常完美,但它的落地阻力并不来自技术,而是来自利益博弈。现有的 AI 寡头们绝对不会主动接入这种透明的问责网络,因为他们的护城河就是建立在“免费白嫖全人类数据且不用负责”的基础上的。$ETH
所以,OpenLedger 的真正爆发点不在于它现在能抢走多少 OpenAI 的份额,而在于未来的宏观监管。随着全球对 AI 数据版权和安全合规的立法收紧,不可篡改的数据溯源将不再是“可选项”,而是强制的“合规门槛”。
未来的 AI 战争,算力和智能只是入场券;谁能证明自己的模型没有“被污染”,谁能建立起一套干净、可溯源的数据账本,谁才能活到最后。OpenLedger ($OPEN ) 正在赌的,就是这个残酷但必然的未来。