OpenLedger ist eines dieser Projekte, das dich für einen Moment innehalten lässt, nicht weil das Pitch völlig neu ist, sondern weil das zugrunde liegende Problem echt genug ist, dass du es nicht sofort abhaken kannst.
Und ehrlich gesagt, das ist heutzutage im Crypto-Bereich selten.
Nach ein paar Zyklen entwickelt man eine Art Allergie gegen große Narrative. DeFi sollte die Finanzen neu aufbauen. GameFi sollte die nächsten Milliarden Nutzer an Bord holen. Metaverse-Land sollte irgendwie die Immobilien ersetzen. Modulare Chains sollten Scaling lösen. AI-Crypto ist jetzt die neueste Phase, in der jedes Projekt plötzlich entdeckt, dass es schon immer um künstliche Intelligenz ging.
Wenn sich also etwas „AI-Blockchain“ nennt, ist der erste Instinkt nicht Aufregung. Es ist Misstrauen.
Du liest die Phrase einmal und dein Gehirn bereitet sich sofort auf den üblichen Stapel von Schlagwörtern vor: dezentrale Intelligenz, offene Agenten, Datensouveränität, skalierbare Infrastruktur, gemeinschaftliches Eigentum, Anreizausrichtung. Alle vertrauten Zutaten. Alle Wörter, die wichtig klingen, bis du fragst, was tatsächlich darunter passiert.
Aber OpenLedger weist zumindest auf ein Problem hin, das wirklich wichtig ist.
KI hat ein Beitragsproblem.
Kein Branding-Problem. Kein Token-Problem. Ein Beitragsproblem.
Jedes nützliche KI-System basiert auf den Daten, dem Wissen, den Beispielen, dem Feedback, den Dokumenten, den Workflows, den Labels, den Korrekturen und der Erfahrung in dem Bereich von jemand anderem. Das ist der Teil, den die Leute gerne überspringen. Das Modell wird als das Produkt präsentiert, aber das Modell ist wirklich das Endergebnis einer langen Kette unsichtbarer Eingaben.
Jemand hat die Daten erstellt. Jemand hat sie bereinigt. Jemand hat sie organisiert. Jemand wusste genug über das Thema, um die Informationen nützlich zu machen. Dann wird das Ganze in ein Modell absorbiert, und sobald es drin ist, wird der ursprüngliche Beitrag fast unmöglich zu sehen.
Das ist der seltsame Handel der modernen KI. Jeder trägt zur Intelligenzschicht bei, aber nur einige Plattformen erfassen den Großteil des Wertes.
OpenLedger versucht, um diese Lücke herum zu bauen.
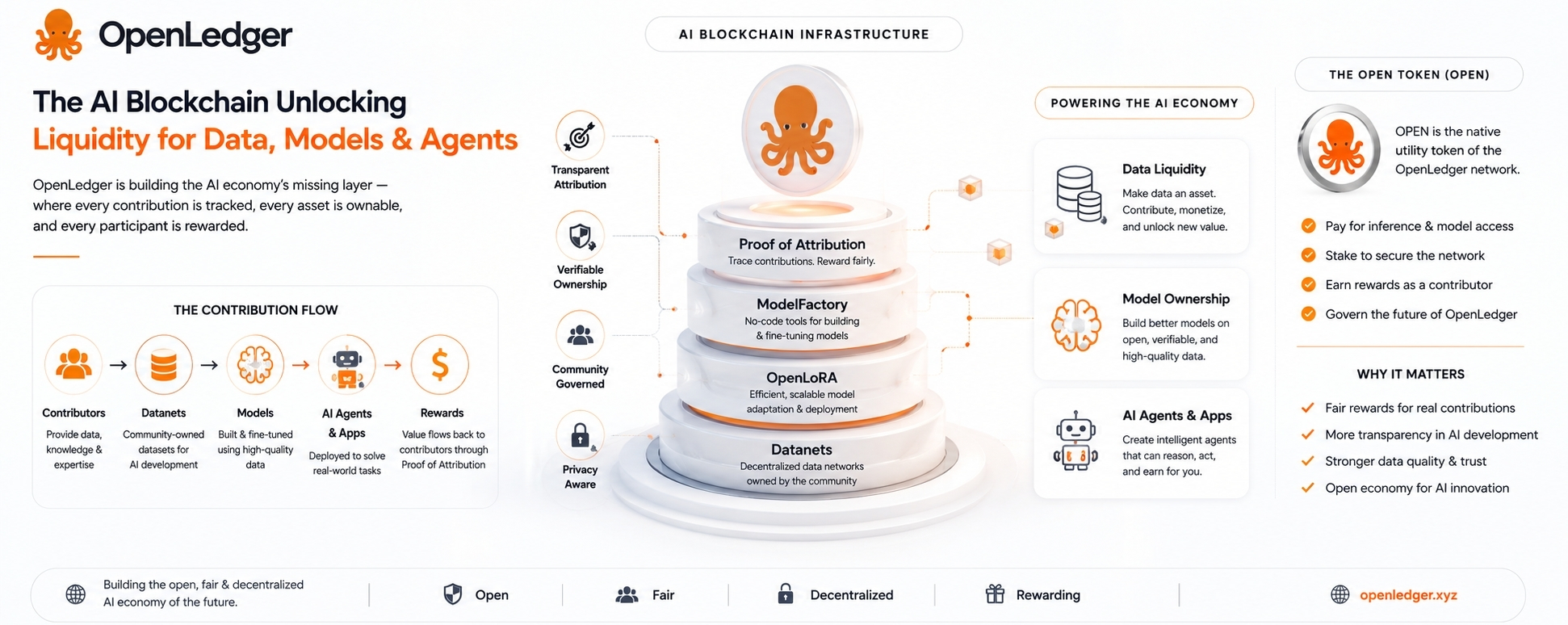
Die Grundidee ist, dass Daten, Modelle und KI-Agenten nicht nur als vage digitale Objekte umherwandern sollten. Sie sollten nachvollziehbar sein. Sie sollten Herkunft haben. Sie sollten mit den Leuten oder Gemeinschaften verbunden sein, die sie geschaffen haben. Und wenn sie später Wert generieren, sollte es einen Mechanismus geben, um die Mitwirkenden dahinter zu belohnen.
Das klingt offensichtlich, wenn du es langsam sagst. Es klingt auch extrem schwierig, wenn du darüber nachdenkst, wie KI tatsächlich funktioniert.
Weil die KI-Zuordnung chaotisch ist.
Ein Modell beantwortet eine Frage nicht einfach, indem es eine Datei von einem Regal zieht. Es sagt nicht: „Diese Antwort kam zu 12 % aus Alis Datensatz, zu 8 % aus diesem Prüfbericht und zu 3 % aus diesem Forum-Beitrag.“ Zumindest nicht auf natürliche Weise. Outputs werden durch Trainingsdaten, Feintuning, Gewichte, Eingabeaufforderungen, Einbettungen, Abrufsysteme, Adapter und alles andere, was auf den Stack geschraubt wurde, geformt.
Wenn OpenLedger also über Proof of Attribution spricht, ist das der Teil, auf den es sich zu achten lohnt, aber auch der Teil, der am meisten Skepsis verdient.
Die Idee ist, zu identifizieren, welche Daten einen KI-Output beeinflusst haben und die Mitwirkenden basierend auf diesem Einfluss zu belohnen. Wenn es funktioniert, ist es sinnvoll. Wenn es vage wird, ist es nur ein weiteres tokenisiertes Punktesystem mit besserer Sprache.
Das ist die Linie, die OpenLedger gehen muss.
Dennoch ist das Framing nicht leer. KI benötigt eine bessere Buchhaltungsschicht. Im Moment ist das Internet voll von Werten, die KI-Systeme konsumieren, komprimieren und monetarisieren. Der Output fühlt sich sauber an, aber die Eingabevergangenheit ist verschwommen. Und während KI-Agenten häufiger werden, wird diese Unschärfe zu einem größeren Problem.
Wenn ein KI-Agent hilft, einen Smart Contract zu überprüfen, woher kam sein Sicherheitswissen?
Wenn ein KI-Handelsassistent ein Muster erkennt, wessen Daten haben ihm dabei geholfen?
Wenn ein rechtliches KI-Tool einen Vertrag überprüft, welche Dokumente haben sein Denken geprägt?
Wenn ein medizinischer Assistent einen Vorschlag macht, welches Wissen lag diesem Antwort zugrunde?
Das sind keine philosophischen Fragen mehr. Sie werden wirtschaftliche Fragen in dem Moment, in dem die Leute anfangen, für die Ergebnisse zu zahlen.
Deshalb sind die Datanets von OpenLedger interessant.
Ein Datanet ist im Grunde ein gemeinschaftlich besessenes Datennetzwerk, das sich um ein bestimmtes Thema oder Anwendungsfall dreht. Anstatt dass Daten stillschweigend von einem zentralisierten Unternehmen gesammelt werden, können Mitwirkende nützliche Informationen in eine gemeinsame Datenschicht einfügen. Diese Daten können dann verwendet werden, um Modelle zu trainieren oder zu verfeinern.
Theoretisch könntest du ein Datanet für Smart Contract-Exploits, ein weiteres für rechtliche Dokumente, ein weiteres für Gesundheitsworkflows, ein weiteres für Datenmapping, ein weiteres für DeFi-Risikoanalysen usw. haben.
Die Idee ist nicht nur, Daten zu sammeln. Jeder sammelt Daten. Die Idee ist, eine Aufzeichnung darüber zu führen, wer was beigetragen hat, und diesen Beitrag dann mit zukünftiger Modellnutzung zu verknüpfen.
Das ist der Teil, der ernster erscheint als das übliche „KI plus Token“-Gespräch.
Denn wenn spezialisierte KI wirklich dort ist, wo der Markt hingeht, dann werden spezialisierte Daten extrem wertvoll. Allgemeine Modelle sind bereits gut genug für breite Aufgaben. Der nächste Kampf geht nicht darum, wer einen Chatbot dazu bringen kann, nette Dinge zu sagen. Es geht darum, wer Modelle bauen kann, die spezifische Bereiche tief verstehen.
Eine allgemeine KI kann das Risiko von Smart Contracts erklären. Ein spezialisiertes Modell, das auf echten Exploit-Daten trainiert wurde, könnte tatsächlich helfen, es zu erkennen.
Eine allgemeine KI kann über Finanzen sprechen. Ein spezialisiertes Modell, das auf strukturierten Marktverhalten und Risikodaten trainiert wurde, könnte nützlicher werden.
Eine allgemeine KI kann Inhalte im Gesundheitswesen zusammenfassen. Ein spezialisiertes klinisches Modell, vorausgesetzt, Datenschutz und Compliance werden ordnungsgemäß gehandhabt, könnte etwas weit Wertvolleres tun.
Also zielt OpenLedger auf einen echten Trend ab: den Übergang von allgemeiner KI zu domänenspezifischer Intelligenz.
Aber nochmal, die Ausführung ist wichtig.
Krypto hat die Angewohnheit, jedes gültige Problem in eine überdesignte Token-Ökonomie zu verwandeln. Manchmal ist das Token entscheidend. Manchmal ist es einfach Klebeband über einem Marktplatz, der ohne eines hätte funktionieren können.
OPEN, der native Token, soll innerhalb der OpenLedger-Ökonomie sitzen. Er kann für Netzwerkgebühren, Modellzugang, Inferenzzahlungen, Staking, Governance und Mitwirkendenbelohnungen verwendet werden. Das macht strukturell Sinn. Wenn das Netzwerk tatsächlich genutzt wird, hat das Token eine Rolle.
Aber die Phrase „wenn das Netzwerk tatsächlich genutzt wird“ leistet hier viel Arbeit.
Ein Token schafft keine Nachfrage, indem es existiert. Ein Marktplatz wird nicht wertvoll, weil ein Dashboard sagt, dass Mitwirkende verdienen können. Der schwierige Teil besteht darin, die Menschen dazu zu bringen, qualitativ hochwertige Daten beizutragen, Entwickler dazu zu bringen, Modelle aus diesen Daten zu erstellen, Benutzer dazu zu bringen, für diese Modelle zu bezahlen, und sicherzustellen, dass die Belohnungen auf eine Weise fließen, die fair und nicht willkürlich erscheint.
Das ist der Punkt, an dem viele Krypto-Projekte scheitern.
Sie können Anreize für die erste Welle gestalten. Sie können frühe Mitwirkende anziehen. Sie können die Charts lebendig aussehen lassen. Aber langfristiger Wert kommt nur, wenn das System etwas produziert, das Menschen außerhalb des Anreizloops tatsächlich wollen.
Die Zukunft von OpenLedger hängt davon ab, ob es nützliche KI-Systeme produzieren kann, nicht nur gut gekennzeichnete Datensätze.
ModelFactory ist Teil dieses Versuchs. Es soll das Feintuning erleichtern, insbesondere für Menschen, die sich nicht mit schwerer Maschinenlernen-Infrastruktur auseinandersetzen möchten. Das ist eine gute Richtung, denn die meisten Fachleute sind keine ML-Ingenieure.
Die Person, die rechtliche Verträge versteht, weiß vielleicht nicht, wie man ein Modell optimiert.
Der Trader, der die Marktstruktur versteht, weiß vielleicht nicht, wie man Inferenzinfrastruktur bereitstellt.
Der Sicherheitsforscher, der Exploits versteht, möchte vielleicht keine Adapter und GPUs verwalten.
Wenn OpenLedger es diesen Menschen erleichtern kann, Wissen in nutzbare KI-Vermögenswerte zu verwandeln, ist das wichtig.
OpenLoRA ist ein weiteres praktisches Stück. Spezialmodelle sind nützlich, aber deren Betrieb kann teuer werden. LoRA-basiertes Feintuning ist bereits einer der realistischeren Wege, um viele leichte Modellvariationen zu erstellen. Wenn OpenLedger die effiziente Bereitstellung vieler feinabgestimmter Modelle unterstützen kann, gibt das dem Ökosystem eine praktischere Grundlage.
Hier beginnt das Projekt, weniger wie ein reines Narrative-Play auszusehen und mehr wie ein Versuch, einen vollständigen KI-Produktionsstack aufzubauen.
Daten kommen über Datanets herein.
Modelle werden durch Werkzeuge wie ModelFactory erstellt oder feinabgestimmt.
OpenLoRA hilft bei der Bereitstellung.
KI-Agenten und Anwendungen sitzen darüber.
Die Kette zeichnet Beiträge, Nutzung und Belohnungen auf.
Das ist die Karte, zumindest.
Ob das Gebiet so aussieht, ist eine andere Frage.
Der schwierigste Teil bleibt die Zuordnung. Es ist einfach, „Proof of Attribution“ in ein Whitepaper zu schreiben. Es ist viel schwieriger, die Mitwirkenden dazu zu bringen, dem System zu vertrauen, dass es den Einfluss genau misst. Wenn die Belohnungen zu vage sind, verlieren die Leute das Interesse. Wenn das System manipulierbar ist, wird minderwertige Daten fluten. Wenn nur große Mitwirkende profitieren, schwächt sich der Gemeinschaftsaspekt. Wenn die Zuordnung zu teuer oder zu langsam ist, könnten Entwickler sie meiden.
Es gibt auch das Datenschutzproblem. Einige der wertvollsten KI-Daten sind sensibel. Gesundheitsdaten, Finanzunterlagen, rechtliche Materialien, Unternehmensworkflows — das sind keine Dinge, die Menschen lässig in ein offenes Netzwerk werfen. OpenLedger wird starke Genehmigungen, Datenschutz und Compliance-Pfade benötigen, wenn es ernsthafte Akzeptanz über krypto-nativen Datensätze hinaus anstrebt.
Dann gibt es das Marktproblem. AI-Krypto ist überfüllt. Jede Woche gibt es eine neue Agentenplattform, einen Datenmarktplatz, ein Inferenznetzwerk, eine dezentrale Berechnungsschicht oder ein Modellbesitzprotokoll. Einige sind durchdacht. Viele sind narrative Hüllen. Investoren und Nutzer sind müde, auch wenn sie immer noch der nächsten Rotation hinterherjagen.
OpenLedger muss also beweisen, dass sein Kernmechanismus tatsächlich von Bedeutung ist.
Nicht theoretisch.
In der Nutzung.
Kann jemand ein besseres Modell wegen OpenLedger bauen?
Kann ein Mitwirkender verdienen, weil seine Daten tatsächlich einen Output verbessert haben?
Kann ein Entwickler einen KI-Agenten schneller oder günstiger starten?
Kann ein Benutzer der Herkunft von dem, womit er interagiert, vertrauen?
Kann das System Daten anziehen, die sonst nirgendwo erschienen wären?
Das sind die Fragen, die wichtig sind.
Und vielleicht ist das der Grund, warum OpenLedger es wert ist, beobachtet zu werden, ohne sich mitreißen zu lassen.
Es ist nicht automatisch revolutionär. Es ist nicht garantiert, dass es die Basisschicht des KI-Eigentums wird. Es ist nicht immun gegen die üblichen Krypto-Probleme von Spekulation, übermäßig incentivierter Aktivität und narrativer Inflation.
Aber es umkreist ein echtes Problem.
KI schafft enormen Wert aus unsichtbaren Eingaben. Das aktuelle System hat keinen fairen oder transparenten Weg, um diese Eingaben zu verfolgen. OpenLedger versucht, diese fehlende Schicht mit Blockchain-Rails, Zuordnungslogik und Tokenanreizen aufzubauen.
Das könnte funktionieren. Das könnte nicht funktionieren.
Aber das Problem ist echt genug, dass der Versuch mehr als eine schnelle Abweisung verdient.
Der klarste Weg, über OpenLedger nachzudenken, ist dieser: Es möchte der KI ein wirtschaftliches Gedächtnis geben.
Nicht nur Gedächtnis im Sinne des Modells, sondern Gedächtnis des Beitrags. Wer hat die Daten hinzugefügt? Wer hat das Modell gestaltet? Wer hat den Agenten gebaut? Wer verdient einen Anteil, wenn das System nützlich wird?
Das ist eine überzeugende Idee, besonders in einer Welt, in der KI gleichzeitig mächtiger und zentralisierter wird.
Der Skeptiker in mir will immer noch Beweise. Echte Nutzung. Echte Mitwirkende. Echte Modelle. Echte Nachfrage. Nicht nur Kampagnen, Punkte, Tokenemissionen und Screenshots von Ökosystempartnern.
Aber die Forscherin in mir versteht, warum diese Kategorie wichtig ist.
Wenn die nächste Phase der KI auf spezialisierten Daten und autonomen Agenten basiert, dann sind Eigentum und Zuordnung keine Nebenmerkmale. Sie werden zur Infrastruktur.
OpenLedger setzt darauf.
Und nachdem ich genug Whitepapers gelesen habe, um zu wissen, wie oft diese Dinge in Lärm kollabieren, hinterlässt dieses hier zumindest eine Frage, die bleibt: