
I’ve seen this movie before.A new tech stack shows up wearing a shiny jacket. The demos are smooth. The pitch is clean. The money is supposed to be in the model, the platform, the network, the future. Meanwhile the ugly stuff gets stuffed into a closet and left there. With AI, that ugly stuff is data. Who made it. Who cleaned it. Who labeled it. Who paid for it. Who gets left out when the model starts cashing checks. OpenLedger is trying to mess with that arrangement by building around community-owned datasets, onchain attribution, and reward mechanics tied to data contribution. That is the core of its own pitch, straight from the docs.
Here’s the thing. That sounds noble until you remember how much of the AI industry runs on vague credit and cleaner-than-reality accounting.
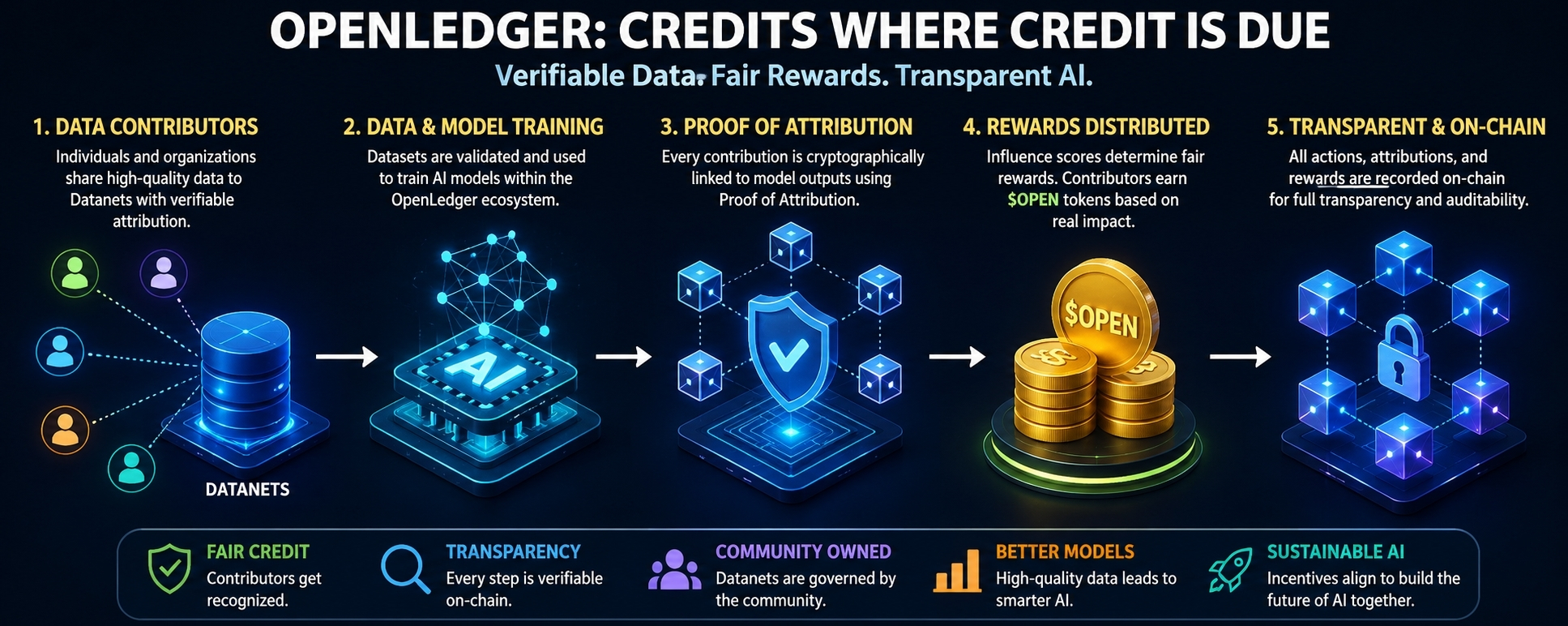
OpenLedger says it is an AI-blockchain infrastructure for training and deploying specialized models using Datanets, with dataset uploads, model training, reward credits, and governance participation all executed on-chain. It also says Proof of Attribution is a cryptographic mechanism that links data contributions to model outputs and records those contributions immutably so contributors can get credit and rewards based on impact. That is the promise. The trade-off is obvious and very human: once you start promising fair accounting, you also invite arguments about who deserves what, and those fights never stay polite for long.
I’m skeptical of almost anything that claims to fix an incentive problem with a new layer of infrastructure.
But I’m more skeptical of the status quo. The current AI stack has a habit of acting like data is vapor. It isn’t. OpenLedger’s own docs frame specialized data as essential for domain-specific models because targeted, high-fidelity datasets improve accuracy, interpretability, and efficiency. They also say specialized models need data that is credible and transparent, and that decentralized participation can keep the system alive longer than a one-way extraction machine. That is not crazy. It is just inconvenient for people who want to keep the old margins intact.
The Datanet idea is the interesting bit.
Not the token gloss. Not the blockchain perfume. The Datanet. OpenLedger describes Datanets as decentralized data networks that aggregate, validate, and distribute domain-specific datasets needed for model training. Contributors provide high-quality data with verifiable attribution, and the network is supposed to make access trustless and transparent. That is a real design goal, not a buzzword pile. But here’s the kicker: once you make data visible and governed, you also make it political. Every dataset becomes a small border dispute. Every contribution becomes a question. Every reward table becomes a fight over value.
I’ve seen that turn before.
A system starts by promising fairness. Then it discovers that fairness has a cost, and the cost lives in edge cases. Who validates the data? Who decides the contribution was meaningful? What happens when one contributor is noisy, another is strategic, and a third is just plain sloppy? OpenLedger’s attribution pipeline says data sources are cryptographically linked to model outputs, that influence scores are calculated, and that token-based rewards flow proportionally to impact. Fine. But proportional to what, exactly? That is where systems like this either grow up or get gamed.
The model factory piece is where the project gets a little more grounded.
OpenLedger’s ModelFactory is pitched as a GUI-only fine-tuning platform for large language models, with support for common models like LLaMA, Mistral, and DeepSeek, plus LoRA and QLoRA methods. It is designed to let users fine-tune models on permissioned or approved datasets without living in a terminal all day. That is practical. Also, very revealing. Because the second you make the workflow easier, you invite more people into the room. And more people means more mistakes, more edge cases, more governance noise, more pressure on the attribution layer to work when things get messy.
That friction matters more than the marketing people want to admit.
A lot of “AI infrastructure” projects are built by folks who love the idea of distributed participation right up until they have to support actual users. OpenLedger’s docs suggest it wants builders to create, contribute, and publish models inside a broader ecosystem where the chain records the important parts. That may help with accountability. It may also create a system that feels heavy the first time a team needs to ship something fast. The point is not that the trade-off kills the idea. The point is that the trade-off is the idea.
What I keep coming back to is this: AI is not just a model problem. It is an ownership problem.
Who owns the training inputs. Who owns the derived output. Who owns the right to reuse the thing. Who gets paid when the model performs. OpenLedger’s whole thesis is that those questions should not be handled as side chatter after the launch party. They should be built into the stack. Its docs even say governance happens through a hybrid on-chain system and that OPEN token holders participate in protocol direction and upgrades. That sounds tidy on paper. In the wild, governance is where ideals go to get mugged.
There’s a reason this kind of project attracts both believers and people with their hand already on the exit.
It smells like a trap to one crowd and like overdue housekeeping to another. I land closer to the second camp, but with both eyes open. OpenLedger’s blog and product pages frame the company as an AI blockchain meant to monetize data, models, and agents, and its ecosystem pages keep pushing the idea of verifiable intelligence and specialized AI systems. That tells me the team is betting on a world where provenance is not a nice-to-have. It is the product. Maybe even the moat.
Now for the uncomfortable bit.
If OpenLedger works, it will not just be because the tech is clever. It will be because the market is tired. Tired of opaque data sourcing. Tired of models built on anonymous scraps. Tired of watching a few platforms capture the upside while everybody else gets a pat on the head. OpenLedger’s own wording about verifiable attribution, immutable records, and contributor rewards is aimed squarely at that fatigue. That doesn’t make it a sure thing. It makes it a timely thing.
I think the most realistic use case is not some grand public AI utopia.
It is specialized, high-friction, high-value settings where data is scarce and trust matters. Health. Finance. Legal. Industrial systems. Places where people already know the difference between a toy model and something that can get you sued, fired, or buried in compliance work. OpenLedger’s own materials point toward specialized data collection and domain-specific model training as the reason the system exists in the first place. That is not sexy. Good. Sexy usually means somebody is hiding the bill.
And yet I’m not ready to hand out applause.
Because provenance systems can turn into bureaucratic fan fiction fast. They can become elaborate ledgers that look serious and still fail the only test that matters: do they change behavior in the real world? Do contributors actually get paid? Do builders actually trust the attribution? Do users care enough to choose this stack over the easier one? Those are the questions. Everything else is set dressing.
Let’s be real. The AI industry has a long record of admiring the problem while dodging the bill.
OpenLedger is interesting because it is aiming at the bill. Not perfectly. Not cleanly. Not in a way that guarantees victory. But it is aiming there. It treats data as something more than fuel. It treats contribution as something more than background noise. It treats provenance as infrastructure instead of a legal footnote. That is a better instinct than most of the field’s polished nonsense. It still has to survive contact with users, incentives, and human opportunism. That part never goes away.
So my read is simple.
OpenLedger is not selling magic. It is selling receipts. That is less glamorous. Also more useful. Maybe the whole thing works. Maybe it gets buried under its own complexity. Maybe it ends up as one more smart idea that the market half-understood and then ignored. I’ve seen that too.
But the problem it is pointing at is real. And the AI crowd can keep pretending otherwise only so long.