
Etwas stört mich an der Art, wie Leute in letzter Zeit über KI-Infrastruktur sprechen.
Jede Diskussion endet irgendwie am selben Punkt. Berechnung. Chips. Inferenzkosten. Modellgröße. Geschwindigkeit. Fein. Das zählt. Offensichtlich. Aber die Märkte haben eine seltsame Angewohnheit, sich obsessiv auf das zu konzentrieren, was am einfachsten zu messen ist, während sie das ignorieren, was später wirtschaftlich schmerzhaft wird.
Das hab ich schon mal in Krypto gesehen.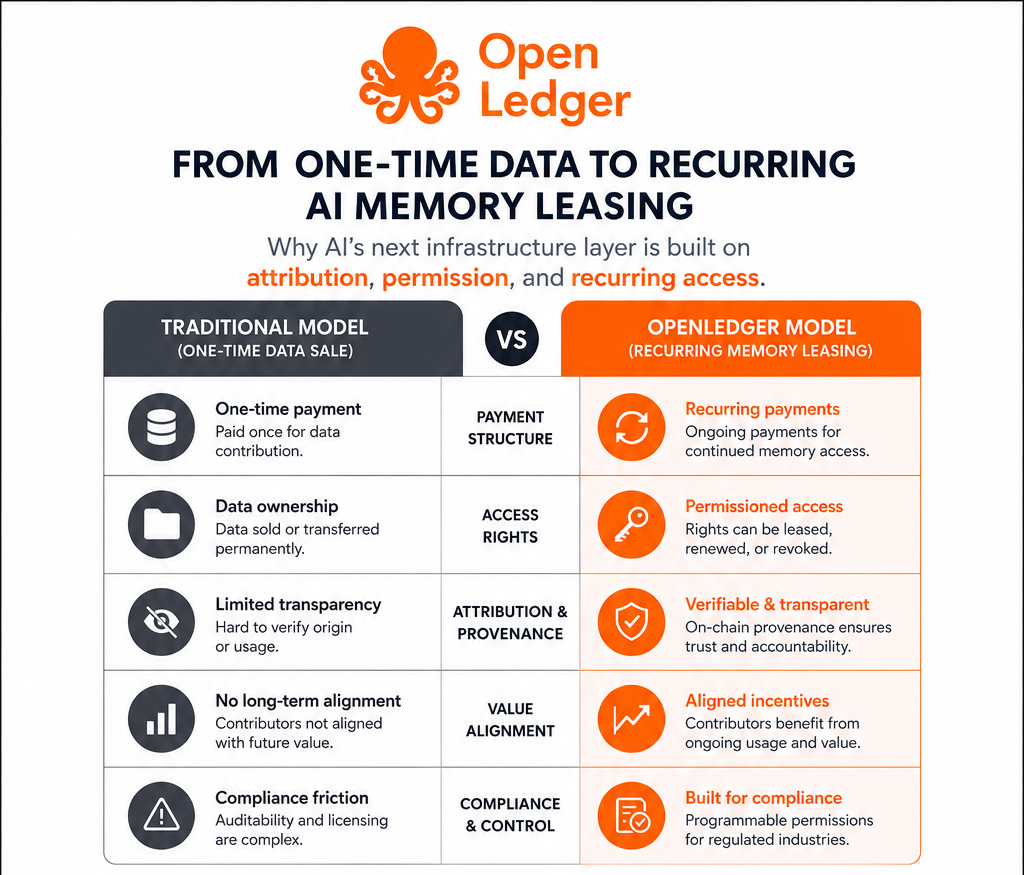
Früher, als die Leute Blockspace wie die einzige Geschichte behandelt haben, die zählt, hat fast niemand genug Zeit damit verbracht zu fragen, wer tatsächlich kontinuierlich für die Vertrauenskoordination bezahlen würde. Alle liebten die Durchsatz-Candlesticks. Viel weniger interessierten sich für wiederkehrendes Abrechnungsverhalten. Irgendwann reifte dann das Gespräch.
KI fühlt sich im Moment ähnlich an.
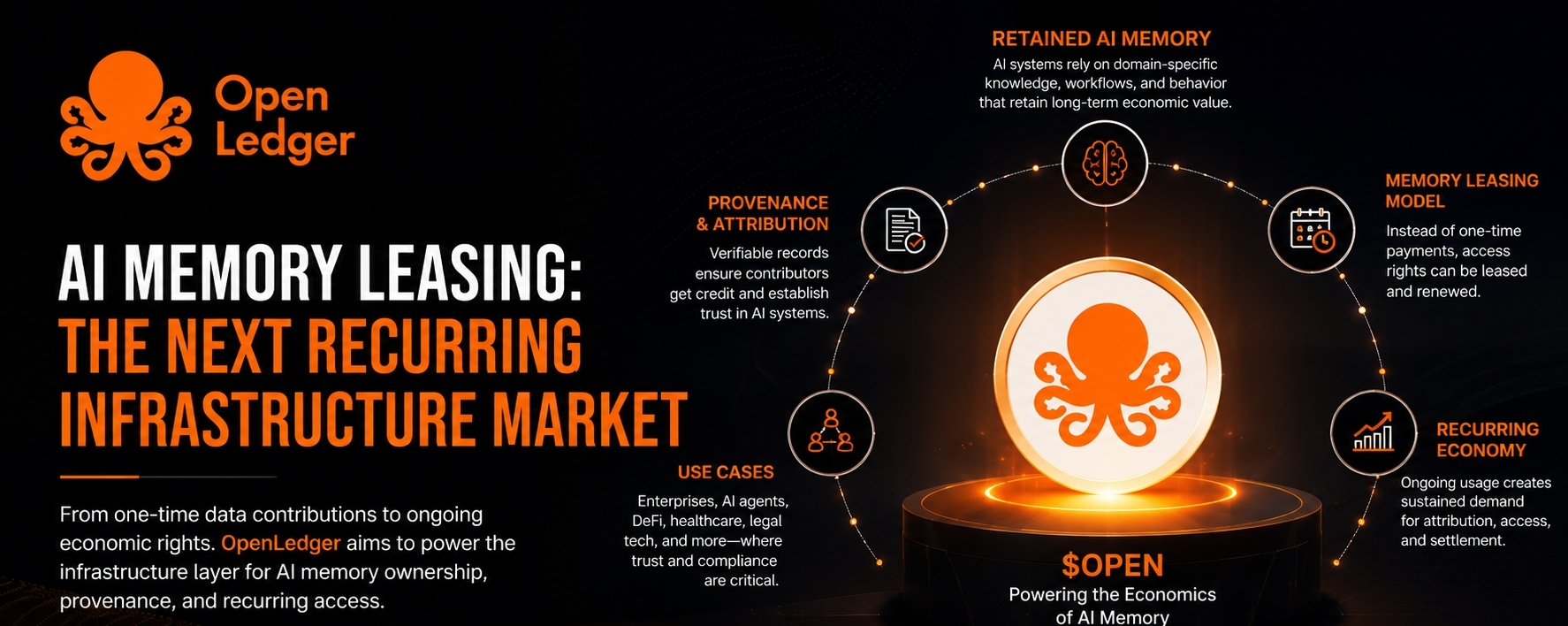
Der seltsame Teil ist, dass die meisten Menschen immer noch über KI-Daten nachdenken, als wären sie eine einmalige Energiequelle. Modell füttern. Modell trainieren. Beitragenden belohnen. Weitermachen. Saubere Geschichte. Inhalt kommt rein, Intelligenz kommt raus.
Aber je mehr ich darüber nachdenke, desto unrealistischer fühlt sich dieses Modell an.
Weil nützliche KI sich nicht mehr wie Wegwerfsoftware verhält.
Wenn ein Unternehmensmodell interne Compliance-Workflows, proprietäre Forschungsmethoden, Verhandlungslogik, Entscheidungsbäume von Kunden oder domänenspezifische Betriebsgewohnheiten erlernt, was genau ist dann wirtschaftlich passiert? Hat das Unternehmen Informationen gekauft? Eine Fähigkeit lizenziert? Verhalten gemietet?
Diese Unterscheidung klingt semantisch, bis Geld im Spiel ist.
Ein einfaches Beispiel macht das einfacher.
Stell dir vor, ein Krankenhaus lizenziert strukturierte klinische Protokolle in einen KI-Workflow-Assistenten. Keine öffentlichen medizinischen Fakten. Ihre interne Entscheidungslogik. Eskalationsmuster. Entscheidungsregeln für Grenzfälle, die über Jahre entwickelt wurden.
Jetzt, sechs Monate später, ist dieser Assistent tief in die Abläufe integriert.
Frage: Wurde dieses Wissen einmal verkauft?
Oder vermietet das Krankenhaus effektiv wirtschaftlich nützlichen Speicher?
Ich denke, hier wird das Gespräch unangenehm.
Denn KI verhält sich nicht wie ein PDF-Archiv.
Sobald Wissen in maschinelles Verhalten eingebettet wird, wird es schwieriger, in klaren Eigentumsbegriffen zu denken. Das System "greift nicht auf eine Datei zu" im traditionellen Sinne. Es drückt erlerntes Verhalten aus, das durch frühere Informationsaussetzung geprägt ist.
Das ist chaotischer.
Das Recht wird hier auch seltsam.
Urheberrecht funktioniert recht gut, wenn Kopien sichtbar sind. Lizenzen funktionieren, wenn Zugangsgrenzen klar sind. SaaS-Verträge machen Sinn, wenn Anbieter und Kunden identifizierbar sind. KI bricht diese Annahmen auf lästige Weise.
Und wenn autonome Agenten echte wirtschaftliche Teilnehmer werden, wird es ehrlich gesagt noch seltsamer.
Denn dann ist Speicher nicht nur passive Lagerung.
Es wird zu operativer Infrastruktur.
Ein Handelsagent erinnert sich an Ausführungspräferenzen. Ein juristischer Agent erinnert sich an Prüfheuristiken für Verträge. Ein Lieferkettenagent erinnert sich an Logik zur Risikobewertung von Anbietern. Ein Compliance-Agent erinnert sich an Eskalationsauslöser.
Dass Speicher wiederholt Wert produziert.
Das bringt mich immer wieder zu einer sehr einfachen Frage zurück.
Warum sollte wiederkehrende wirtschaftliche Leistung als einmaliges Ereignis bepreist werden?
Diese Logik fühlt sich gebrochen an.
Hier begann OpenLedger, anders für mich auszusehen.
Die meisten Kommentare zu OpenLedger konzentrieren sich auf Attribution. Herkunft. Datenbeiträge. KI-Verantwortung. Das sind faire Beschreibungen, aber sie fühlen sich für mich immer noch oberflächlich an.
Attribution allein ist nicht das Geschäftsmodell.
Zahlreiche Systeme können aufzeichnen, wer etwas beigetragen hat. Eine Datenbank kann das tun. Papierkram kann das tun. Sogar ein mittelmäßiges Unternehmens-Dashboard kann genug davon fälschen, um interne Compliance zu gewährleisten.
Die schwierigere Frage ist, ob Attribution das wirtschaftliche Verhalten verändert.
Das ist die echte Trennlinie.
Denn wenn Attribution Teil der Permission-Durchsetzung wird, passiert etwas Interessanteres. Jetzt ist das Problem nicht einfach "Wer hat dieses Modell trainiert?" Es wird zu "Welche wirtschaftlichen Rechte bleiben aktiv, weil dieser Beitrag immer noch wichtig ist?"
Ganz andere Frage.
Und ehrlich gesagt, viel größer.
Ich denke ständig an Musiklizenzen, weil die Leute das instinktiv verstehen. Ein Lied, das einmal in deinen Kopfhörern gespielt wird, ist eine Sache. Ein Lied, das wiederholt kommerziell ausgestrahlt wird, schafft eine andere wirtschaftliche Beziehung.
KI-Speicher könnte näher daran arbeiten, als die Leute erwarten.
Nicht identisch. Definitiv nicht rechtlich identisch. Aber wirtschaftlich? Ähnliche Spannungen.
Persistente Nutzung verändert die Preislogik.
Wenn OpenLedger helfen kann, eine Infrastruktur zu schaffen, in der maschineller Speicher eine verifizierbare wirtschaftliche Herkunft behält, dann könnte c-122 mit einem wiederkehrenden Permission-Markt verbunden sein, anstatt mit einer einmaligen Belohnungserzählung für Mitwirkende.
Das würde zählen.
Krypto-Infrastruktur wird tendenziell am stärksten, wenn sie Abhängigkeiten monetarisiert, nicht Aktivitäts-Spikes.
Validatoren werden bezahlt, weil Vertrauen Pflege benötigt. Orakel werden bezahlt, weil Datenfrische wiederholt wichtig ist. Abrechnungsebenen funktionieren, weil Endgültigkeit kein einmaliges Ereignis ist.
Wiederkehrende Abhängigkeiten schaffen dauerhafte Ökonomien.
Aber ich bin noch nicht ganz überzeugt.
Das größte Problem ist die Durchsetzung.
Hier treffen elegante Infrastrukturideen immer auf die Realität.
Was hindert Entwickler daran, Attribution-Rails einfach zu ignorieren, wenn Integration Kosten verursacht und Wettbewerber schneller ohne sie sind?
Das ist kein theoretisches Anliegen. Märkte umgehen Reibungen die ganze Zeit.
Dann gibt es die hässlichere technische Frage.
Kann man maschinellen Speicher wirklich sauber genug isolieren, um ihn zu vermieten?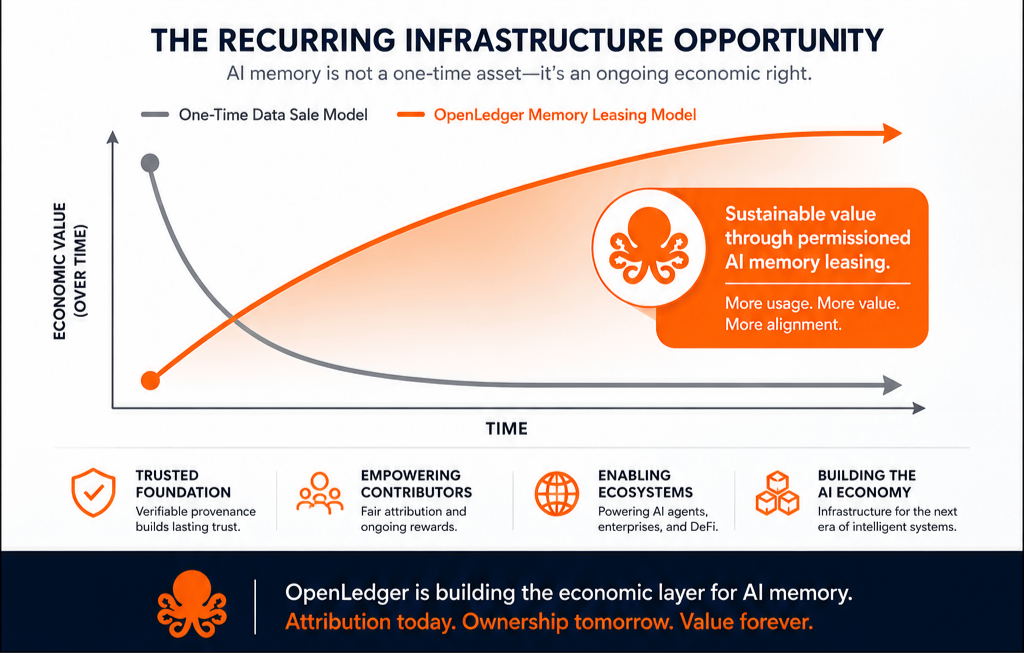
Die menschliche Sprache lässt das einfacher erscheinen, als es ist. Modelle speichern Wissen nicht in ordentlichen Ordnern mit Aufschriften wie "lizenziertes Protokoll" und "nicht lizenziertes Verhalten". Gelernte Muster verschwimmen. Gewichtungen ändern sich. Attribution wird probabilistisch.
Das macht wiederkehrende Durchsetzung schwierig.
Und trotzdem.
Selbst mit all dieser Unsicherheit kann ich das Gefühl nicht abschütteln, dass die Leute leicht in die falsche Richtung schauen.
Vielleicht geht es bei der KI-Infrastruktur letztendlich gar nicht um Rechenleistungseffizienz.
Vielleicht ist das härtere wirtschaftliche Problem das erhaltene Permission.
Wer wird erinnert. Für wie lange. Unter welchen wirtschaftlichen Bedingungen.
Das klingt jetzt abstrakt.
Andererseits tat es auch die Blockspace-Ökonomie, bevor die Märkte herausfanden, dass wiederkehrende Abrechnungen das tatsächliche Geschäftsmodell waren.
OpenLedger könnte komplett daran scheitern, dies zu lösen.
Sehr möglich.
Aber die Frage, die es aufwirft, fühlt sich real an.
Und manchmal ist die bessere Investmentthese nicht die Antwort, die ein Projekt gibt.
Es ist das Problem, das der Markt noch nicht gelernt hat zu bepreisen.