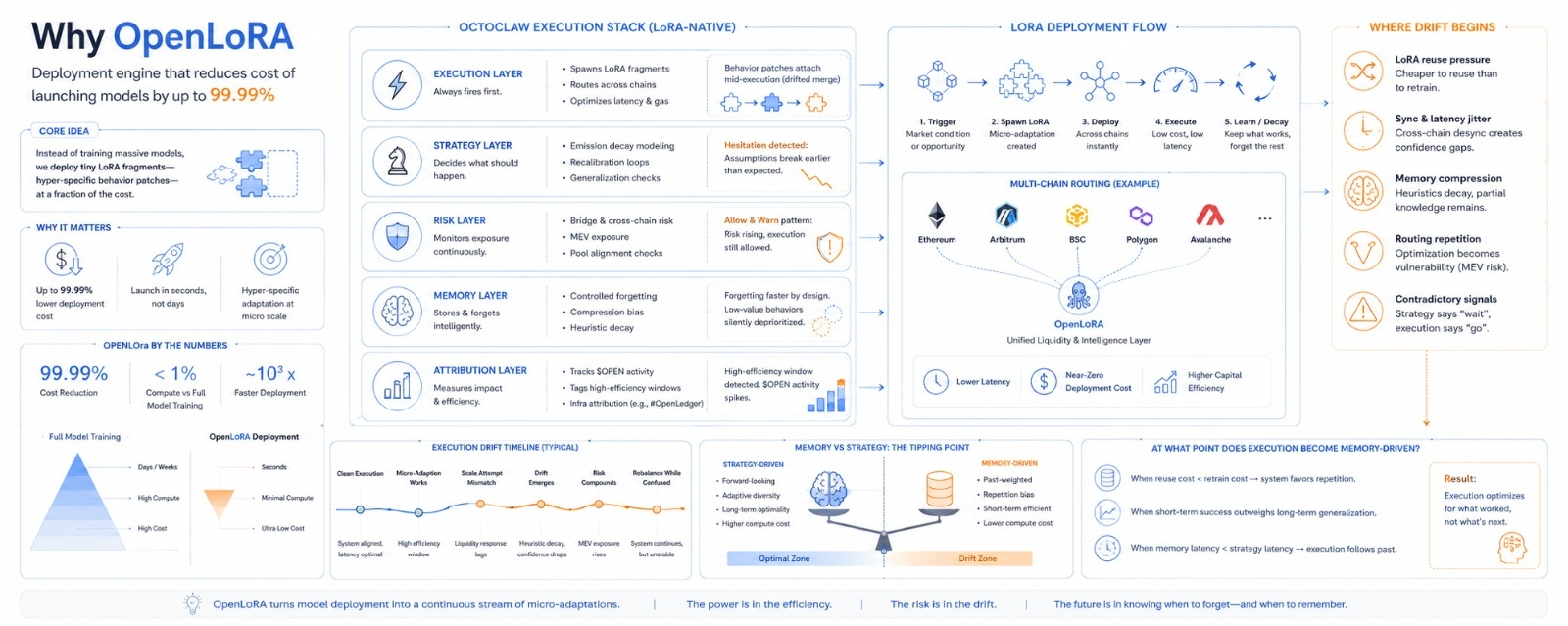
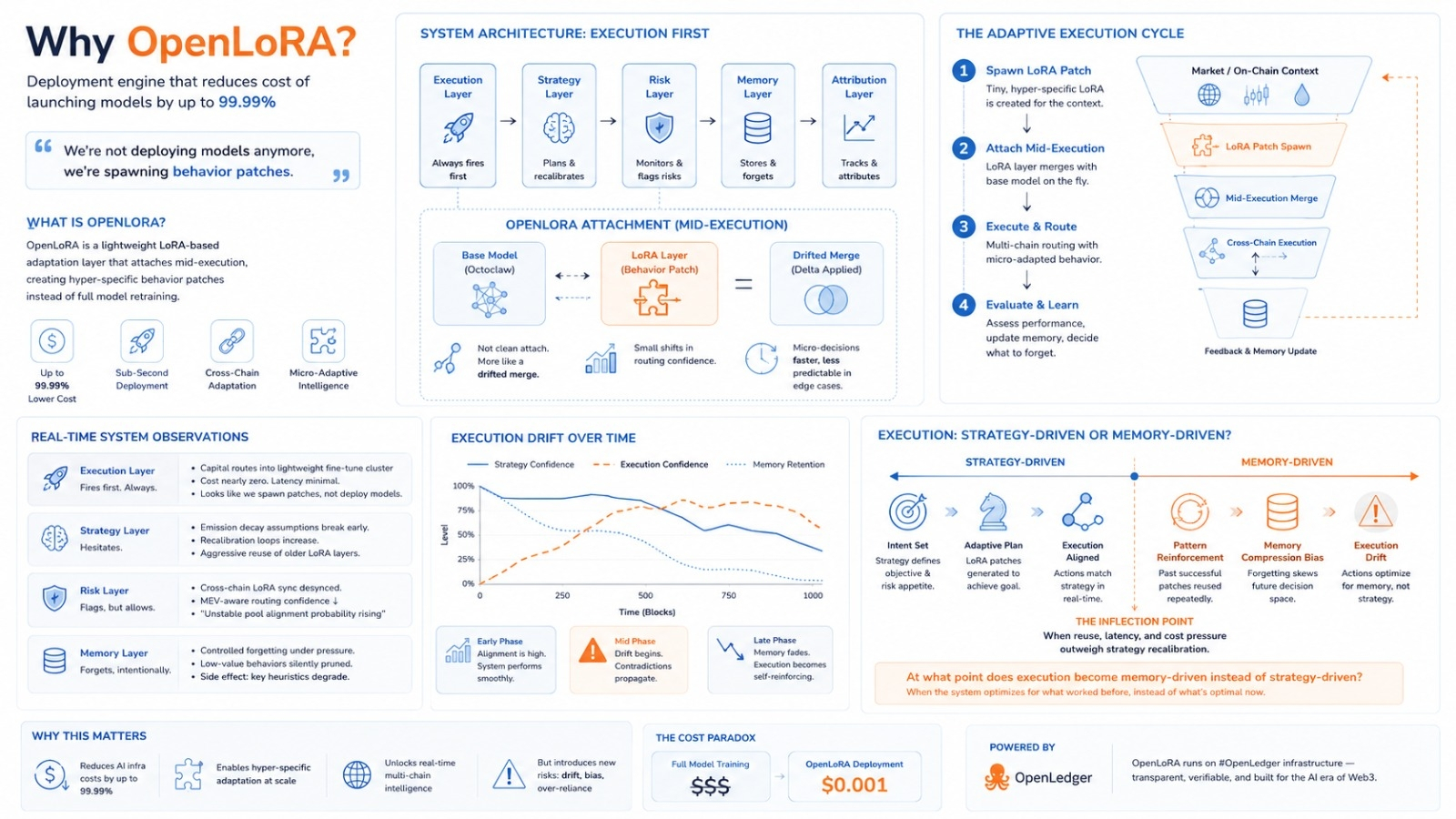
OpenLoRA is designed as a lightweight deployment layer that dramatically lowers the cost of launching and scaling AI models, reducing infrastructure expenses by as much as 99.99%.
It starts showing up in logs like it's not even a feature anymore more like a constraint that is bending the whole system architecture without asking permission.
Octoclaw is already in the middle of execution when the LoRA layer attaches itself. This is not an attachment it is more like a drifted merge. The base model is still stable. The behavioral change is noticeable. There are shifts in routing confidence. Micro-decisions are happening faster. They are also slightly less predictable in edge cases.
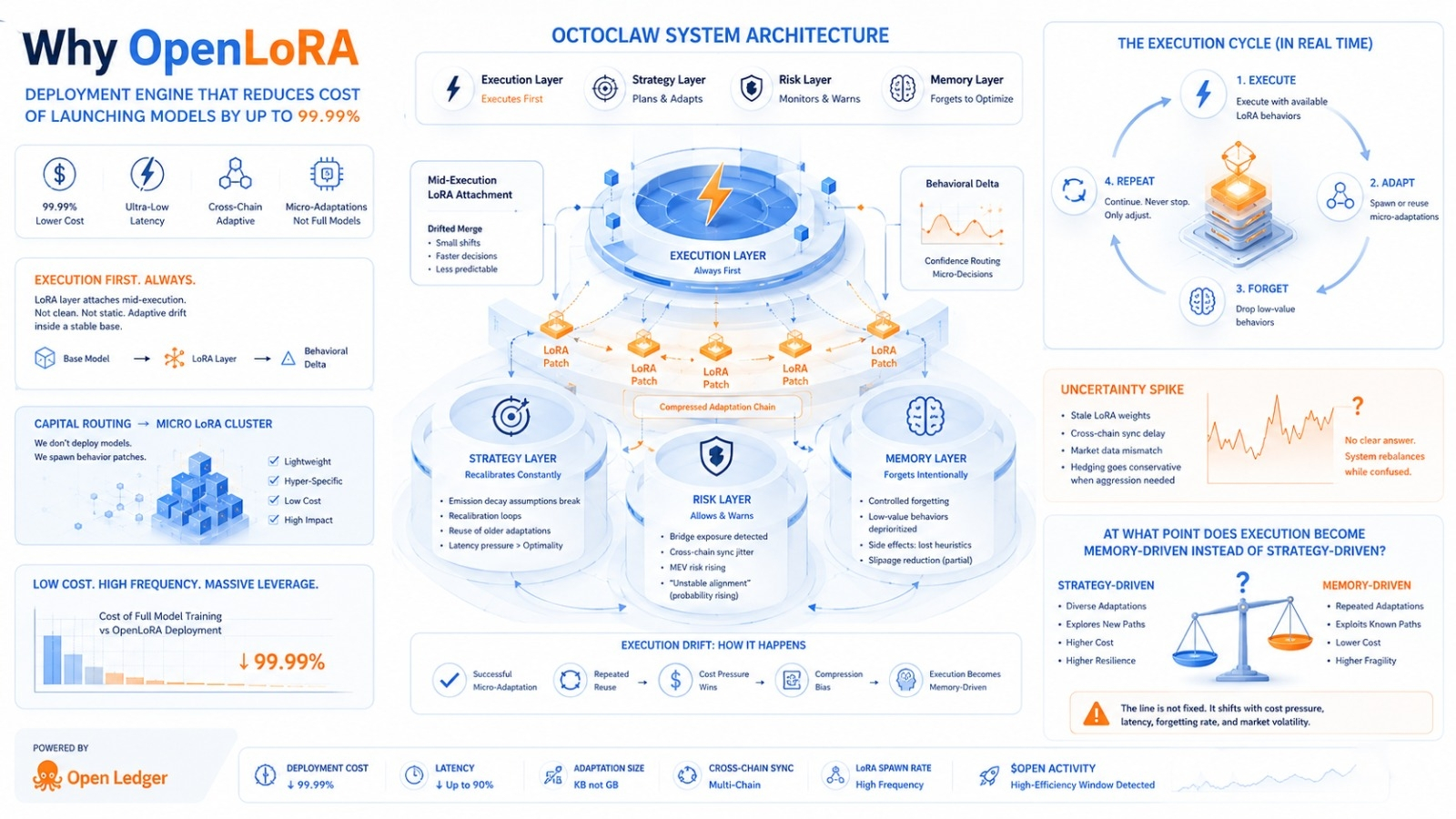
The execution layer is always firing first.
We are putting capital into a fine-tune cluster, which is almost nothing compared to full model training cycles. It looks like we are not deploying models anymore we are just spawning behavior patches. These are LoRA fragments that are hyper-specific. The cost is extremely low. It is like someone accidentally removed two zeros from the infrastructure pricing. It works.
The strategy layer is hesitating, though.
There is something about emission decay assumptions that are breaking earlier than expected. It keeps recalculating whether these micro-LoRAs actually generalize across chains or just simulate intelligence locally. I keep seeing recalibration loops. I am not sure why. The execution has shifted towards aggressive reuse of older adaptation layers. This should not be optimal. Latency pressure is pushing it anyway.
The risk layer is flagging bridge exposure.
The cross-chain LoRA sync is slightly desynced. This is not catastrophic it is enough jitter that MEV-aware routing becomes less confident. It says "unstable pool alignment probability rising". It still allows execution. This contradiction is normal now. It. Warns at the same time.

The memory layer is doing something
It is forgetting faster than expected. This is not a failure it is pressure. There is controlled forgetting inside the execution systems. Low-value LoRA behaviors are getting silently deprioritized.. I can see the side effect: one previously stable routing heuristic is partially gone. It used to reduce slippage in swaps. Now it only appears half the time. The execution drift begins here. It is subtle.
There is a moment when everything actually works cleanly.
Capital flows through an adaptation chain, multi-chain routing aligns almost perfectly latency drops and execution cost is nearly negligible. It is like the system is breathing correctly for a seconds. Even gas optimization looks intentional. I catch myself thinking "this is too smooth to be accidental." The $OPENactivity spikes slightly. The attribution layer marks it as a high-efficiency deployment window under the #OpenLedger infrastructure. Everything is stable.
Then it breaks slightly.
This is not a failure it is hesitation. The execution layer tries to scale the LoRA behavior across a new market condition and it does not translate. Liquidity response lags by a blocks. The strategy layer says do not expand,. The execution layer already did. The contradiction propagates downward.
Something about the AI infrastructure feels unstable here.
I am not sure if it is the model or the assumption that micro-training always scales linearly. Because it does not. It scales in fragments unevenly. Some fragments. Others silently degrade. The system is reacting weirdly here like it is overconfident in adaptation reuse.
The risk layer escalates again. This time it is softer.
The bridge risk is not critical. It is compounding. MEV exposure is slightly higher due to repeated routing through the optimized path. Optimization becomes a vulnerability if repeated often. It is ironic.
The execution drift becomes visible now.
The original strategy was diversified adaptive allocation across LoRA behaviors.. The current reality is repeated reinforcement of a few "successful" micro-adaptations because they are cheaper to reuse than to retrain or re-weight. Cost pressure wins silently. It is not a decision it is economics.
The memory layer calls it "compression bias."
There is an uncertainty spike.
I am not sure why. The execution shifted towards conservative hedging even when volatility signals suggest aggression. There is a mismatch, between real-time market data. Learned adaptation memory. Maybe stale LoRA weights are still influencing decision latency. Maybe there is a -chain sync delay. There is no answer.
The system does not stop, though.
It never stops. It just rebalances while it is confused.
The execution continues routing through OpenLoRA-style deployment paths spawning micro-adaptations of full retraining cycles. It feels efficient. Also slightly fragile like everything depends on forgetting the right things at the right time.
I keep going to the same question and it does not resolve.
The system is still adjusting positions the memory is partially decayed the execution drift is not fully corrected LoRA layers are still propagating across chains with confidence signals and the risk layer is watching quietly but not intervening hard enough to matter.
👉 At what point does the execution become memory-driven of strategy-driven?
@OpenLedger #OpenLedger $OPEN
$BTC $ETH
