Why does data become valuable only after someone else has already used it?
That question keeps bothering me inside OpenLedger.
Not because the model layer is unimportant. It is important. ModelFactory, inference demand, agents, OPEN rewards, that whole route matters. But I keep getting pulled backward, before the model answers, before an agent acts, before anyone can point to a clean usage event and say, yes, this contribution created value.
The strange part starts earlier.
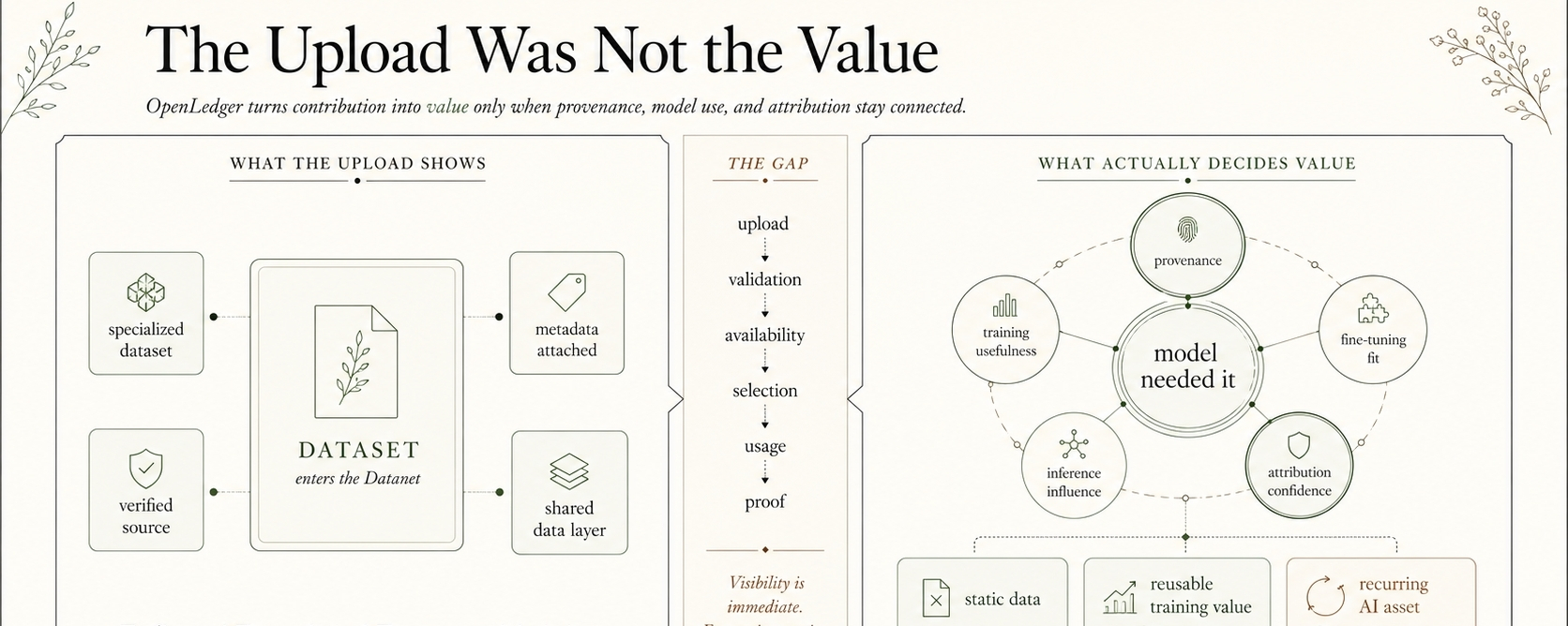
Raw data usually enters AI markets with almost no economic shape. A contributor may have rare domain knowledge, local records, niche behavior data, market observations, research notes, or some ugly but useful dataset nobody else bothered to structure. But before it reaches a model, it sits in a dead zone. Valuable maybe. Liquid, not really.
That is where OpenLedger’s Datanets become more interesting than they first look.
A Datanet is not just a place to drop files. It turns data entry into an origination moment. The contributor is not only uploading material; they are creating a traceable starting point for future AI demand. That difference feels small until rewards begin moving.
Because once OPEN-linked rewards enter the route, the question changes.
It is no longer: did someone submit data?
It becomes: did this specific data deserve to become part of the economic path?
That is harder.
Datanets can make origin visible, but visibility is not the same as value. Contributor records can show who entered what, but a record alone cannot prove the data mattered. Maybe the dataset becomes useful in ModelFactory training. Maybe it improves a narrow model. Maybe an agent later depends on that model during execution. Maybe inference demand finally reaches it.
Or maybe nothing happens.
That uncertainty is the whole point.
OpenLedger is trying to create liquidity around data, models, and agents, but data liquidity cannot begin at the final answer only. If value is discovered only after the model becomes useful, the contributor is already late to their own upside. The system needs a way to remember the origin before usefulness becomes obvious.
That is what Datanet origination pressures.
But I’m not sure the hard part is simply “tracking data.” Tracking is the easier story. The uncomfortable part is ranking usefulness before everyone agrees usefulness exists.
What happens when two contributors submit overlapping data? Does the earlier contributor deserve more because they originated the route first? Or does the cleaner, more structured version deserve more because the model can actually use it? If a small dataset improves a specific agent workflow more than a large generic dataset, does the reward system recognize signal density, or only visible volume?
That already tells me something.
In OpenLedger, raw data does not become an AI-native asset just because it enters a Datanet. It becomes one only when the system can connect origin, reuse, and demand without erasing the contributor in between.
And that connection is fragile.
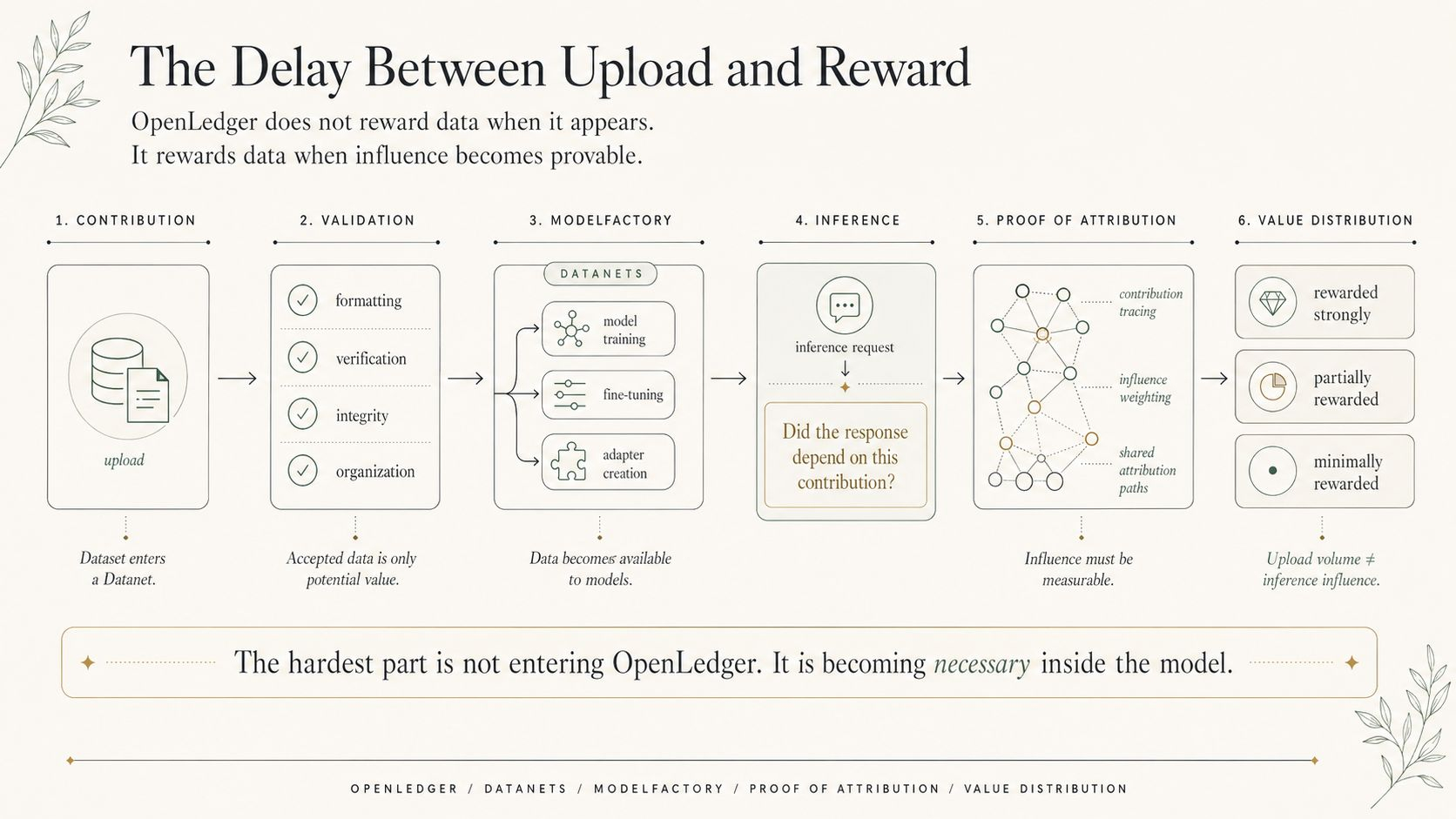
Proof of Attribution can help decide whether data influenced a model, but influence itself is messy. A dataset may shape training indirectly. It may become useful only after being combined with other Datanets. It may support an OpenLoRA adapter that later serves a specialized agent. By the time an inference event produces economic value, the original contribution may be several layers behind the visible output.
That is where data origination becomes more than a storage problem.
It becomes a market design problem.
If OpenLedger rewards only obvious usage, contributors may optimize for data that looks immediately measurable. If it rewards raw submission too easily, low-quality or duplicated data can flood the system. If attribution becomes too strict, hidden but important data gets underpaid. If it becomes too loose, reward claims start drifting away from real influence.
There is no clean setting here.
The boundary feels unstable because OpenLedger is not only asking whether data exists. It is asking whether data can enter an AI Blockchain with enough identity to later become liquid, useful, and economically accountable.
That is a much harder thing to prove.
Maybe Datanets are the first place where raw data stops being passive. Not because every dataset suddenly has value, but because the system gives it a route into model demand before a centralized lab absorbs the upside. The contributor record becomes the first economic handle. OPEN rewards become the later test. ModelFactory and agents become the demand surface.
Still, I keep circling back to the same problem.
Origination can record where data came from.
But can OpenLedger prove which data deserved liquidity before the rewards begin moving?