Die Schnittstelle zwischen Web3 und Künstlicher Intelligenz hatte in den letzten Jahren einen rauen Ruf. Lange Zeit fühlte sich der Raum wie eine endlose Schleife aus Marketing-Hype an, in der Projekte einfach eine grundlegende Hülle um eine generische Chatbot-API schnallten, ein Token darauf klebten und es als revolutionären Durchbruch bezeichneten. Aber während der Markt reift, erkennen ernsthafte Entwickler, dass man eine nachhaltige, dezentrale Maschinenwirtschaft nicht nur auf Hype aufbauen kann.
Hier draußen in der echten Welt rast das tatsächliche KI-Ökosystem auf eine multi-trillionenschwere Wand zu. Es ist eine Branche, die von strukturellen Problemen geplagt wird: Tech-Konglomerate schlucken die Daten des Internets kostenlos, Urheberrechtsklagen häufen sich wie die sprichwörtlichen Fliegen, und die enormen Kosten für Computerhardware lassen unabhängige Entwickler aussterben.
Wenn dezentrale KI überleben soll, benötigt sie keine weiteren spekulativen Anwendungen. Sie braucht robuste, kosteneffiziente Infrastruktur. Genau deshalb ist OpenLedger ($OPEN ) zu einem der strukturell wichtigsten Infrastruktur-Breakouts geworden, die man beobachten sollte. Sie versuchen nicht, mit monolithischen Web2-Tech-Giganten zu konkurrieren, um die nächste massive, allgemeine Chat-Engine zu bauen. Stattdessen bauen sie leise ein Ethereum Layer 2-Ökosystem, das speziell für verifizierbare KI-Modelle maßgeschneidert ist.
Vom allgemeinen LLM zu spezialisierter Intelligenz
Um zu verstehen, warum OpenLedger so viel Traction unter der Haube gewinnt, musst du zunächst einen wichtigen Wandel im breiteren Technologiebereich verstehen. Die Ära, in der versucht wurde, massive, omnipotente Modelle zu bauen, die alles wissen, wird unglaublich ineffizient. Stattdessen suchen Unternehmen nach spezialisierten Sprachmodellen (SLMs) – engen, domänenspezifischen KI-Motoren, die auf hochspezialisierten, sauberen und begrenzten Datensätzen trainiert werden.
Ob es sich um eine KI handelt, die ausschließlich darauf ausgelegt ist, lokale Gerichtsdokumente zu lesen, spezifische medizinische Aufzeichnungen zu analysieren oder Smart Contracts zu prüfen, spezialisierte KI ist der Ort, an dem die reale Welt-Nutzbarkeit lebt. Die Architektur von OpenLedger ist ausdrücklich darauf ausgelegt, diesen genauen Wandel zu unterstützen.
Durch die Nutzung von Hochleistungs-Transaktions-Rollups über Frameworks wie Base, Optimism und Polygon erreicht das Netzwerk schnelle Ausführungsgeschwindigkeiten und minimale Latenz. Dies schafft eine vollständig liquide, Open-Source-Umgebung, in der Daten, fein abgestimmte Modelle und automatisierte KI-Agenten interagieren, einzigartige on-chain Identitäten aufrechterhalten und komplexe Workflows nahtlos ausführen können.
Die drei Säulen: Datanets, ModelFactory und OpenLoRA
Der praktische, alltägliche Nutzen des Netzwerks reduziert sich auf einen kohärenten Loop von drei nativen Entwickler-Tools, die drastisch verändern, wie KI-Modelle gebaut und bereitgestellt werden:
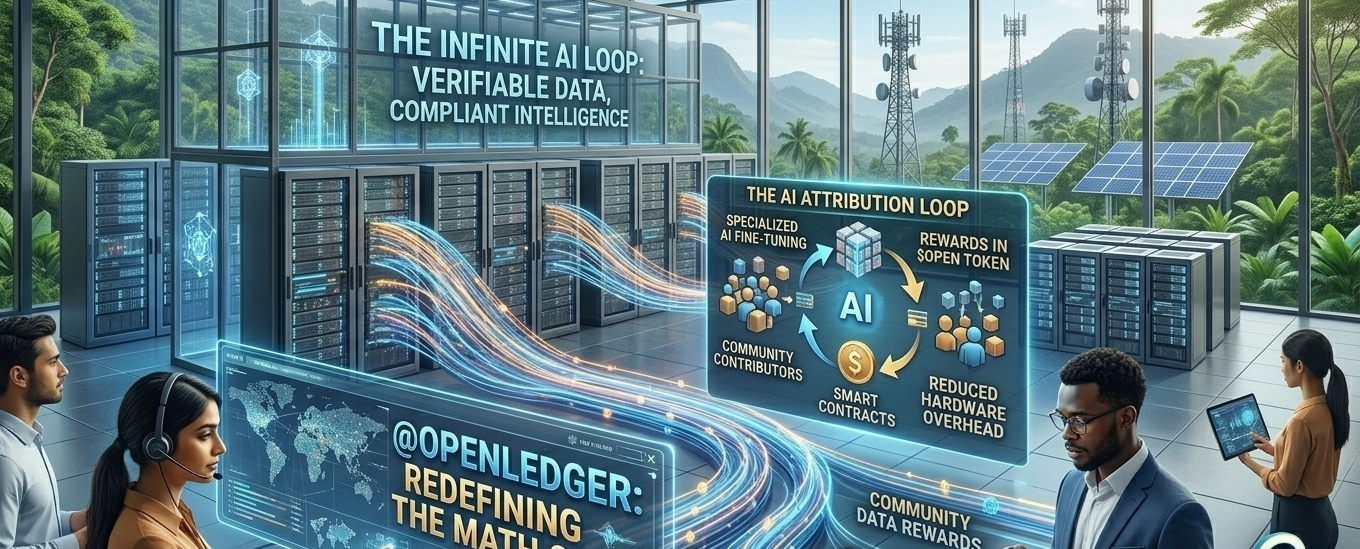
1. Datanets & Proof of Attribution (PoA)
In der Web2-Welt ist die Datensammlung eine Black Box. Große Tech-Konzerne scrapen öffentliche Foren, kreative Plattformen und Nutzerdaten und integrieren sie in ihre Modelle, ohne den ursprünglichen Schöpfern einen einzigen Cent Entschädigung oder Anerkennung zu geben.
OpenLedger löst dies durch Datanets – dezentrale, gemeinschaftlich besessene Daten-Kollaborationsnetzwerke. Jeder kann hochwertige, verifizierte Datensätze zu diesen Bibliotheken beitragen.
Kritisch ist, dass alles durch einen unveränderlichen, on-chain Buchhaltungsmechanismus namens Proof of Attribution (PoA) verankert ist. Mit fortgeschrittenen, einflussbasierten mathematischen Modellen berechnet das Netzwerk genau, wie viel ein einzelner Trainingsdatensatz die Ausgabe eines endgültigen KI-Modells beeinflusst hat. Es fungiert als unzerbrechlicher Prüfpfad. Wenn ein KI-Agent mit diesem speziellen Modell Wert generiert, kümmern sich Smart Contracts um automatisierte Mikrozahlungen direkt zurück an die ursprünglichen Datenbeiträger. Es bringt der KI buchstäblich bei, wie sie für den Kraftstoff, den sie verbraucht, zu bezahlen.
2. ModelFactory
Historisch gesehen erforderte die Feinabstimmung eines KI-Modells spezielles Ingenieurwissen, Meisterschaft der Kommandozeile und chaotische API-Konfigurationen. OpenLedger senkt diese Eintrittsbarriere über ModelFactory, ein vollständig grafisches Dashboard nur für die GUI.
Durch ModelFactory kann ein unabhängiger Entwickler oder ein Unternehmen ein Open-Source-Basismodell (wie LLaMA, Mistral oder DeepSeek) auswählen, genehmigte Datensätze direkt aus dem dezentralen Datanets-Repository anfordern, ihre Feinabstimmungsparameter konfigurieren und Bewertungen über ein einziges Dashboard durchführen. Diese Demokratisierung stellt sicher, dass Fachexperten – wie Ärzte, Anwälte oder Buchhalter – spezialisierte KI-Tools bauen können, ohne Maschinenbau-Ingenieure sein zu müssen.
3. Das OpenLoRA Serving Framework
Selbst wenn du die perfekten Daten und ein fein abgestimmtes Modell hast, ist das Hosting ein wirtschaftlicher Albtraum. Normalerweise erfordert die Bereitstellung eines KI-Modells das Hochfahren dedizierter, unglaublich teurer Cloud-Server, die mit seltenen GPUs ausgestattet sind. Wenn ein Unternehmen tausende von spezialisierten, Nischenmodellen für verschiedene Kunden oder Produkte benötigt, werden die Hardwareüberkopfkosten völlig untragbar.
Das OpenLoRA-Framework von OpenLedger führt eine Multi-Tenant-GPU-Infrastruktur ein, die diese Mathematik radikal verändert. Anstatt tausende von einzelnen Modellen separat zu hosten, hostet das Netzwerk ein einziges, vortrainiertes Kernmodell. Tausende von kleinen, hochspezialisierten Anpassungen (genannt LoRA-Adapter) "teilen" dann gleichzeitig dieselbe Kerninfrastruktur. Dies senkt die Serverüberkopfkosten, optimiert den GPU-Durchsatz und ermöglicht es dem System, vorhersehbar zu skalieren, ohne die Verarbeitungsgeschwindigkeiten zu opfern.
Echte Marktrelevanz und rechtliche Konformität
Was ein tatsächliches Utility-Projekt von einem spekulativen unterscheidet, ist die reale Weltadoption. OpenLedger hat bereits seine Skalierbarkeit bewiesen, indem es über 6 Millionen registrierte Knoten, 25 Millionen on-chain Transaktionen und über 27 aktive Ökosystemprodukte während seiner Testnet- und frühen Betriebsphasen aufgezeichnet hat.
Darüber hinaus geht das Protokoll die rechtlichen Realitäten von KI direkt an. Durch den Aufbau tiefer, strategischer Partnerschaften mit Netzwerken für geistiges Eigentum wie Story Protocol hat OpenLedger einen automatischen, KI-gesteuerten Mechanismus zur Zahlung von Tantiemen integriert. Wenn die globalen Vorschriften strenger werden und die Datenherkunft eine strenge rechtliche Anforderung wird, wird die Fähigkeit, mathematisch zu beweisen, dass dein KI-Modell vollständig auf sauberen, rechtlich lizenzierten Daten trainiert wurde, einen massiven Wettbewerbsvorteil darstellen.
Tokenomics: Der $OPEN Fuel Tank
Das gesamte wirtschaftliche Leben dieses Maschinen-Netzwerks ist sicher verankert durch den nativen Utility-Token, $OPEN, der eine mathematisch festgelegte Gesamtmenge von 1 Milliarde Tokens aufweist.
Statt sich auf spekulative Marktmanipulation zu verlassen, fungiert Open als primärer wirtschaftlicher Gas-Token und Utility-Clearing-Schicht für das Netzwerk:
Der Angebotsloop: Entwickler und Unternehmen müssen $OPEN kaufen und ausgeben, um auf die spezialisierten Datanets-Bibliotheken zuzugreifen oder um die benötigte gemeinsame GPU-Rechenleistung zu bezahlen, um ihre Modelle auszuführen.
Der Nachfrage-Loop: Diese Gebühren fließen direkt zurück in das Ökosystem und belohnen die dezentralen Hardware-Knotenbetreiber, die die Modelle hosten, und die Datenanbieter, die das Netzwerk speisen.
Community-Ausrichtung: Um langfristige Stabilität zu gewährleisten und die Dynamik des zirkulierenden Angebots auszugleichen, sind 61,71 % der gesamten Token-Zuteilung strikt gesperrt und für Community-Belohnungen und Ecosystem-Wachstum reserviert. Darüber hinaus wird das Netzwerk durch ein strukturiertes Ecosystem-Rückkauf-Framework unterstützt, das direkt durch Protokoll-Einnahmen finanziert wird.
Fazit: Der Wandel zu verantwortungsbewusster KI
Da der breitere Kryptowährungsmarkt beginnt, sich von den meme-lastigen Zyklen zu lösen und echte, messbare on-chain Nutzbarkeit verlangt, sind Infrastrukturprojekte, die reale industrielle Engpässe lösen, natürlich in der Position, den Raum zu führen.
Durch den Aufbau eines transparenten, gemeinschaftsgetriebenen und hyper-effizienten Datenbuchs löst OpenLedger genau die Datenbesitz- und Kostenprobleme, mit denen der traditionelle Technologiesektor aktiv zu kämpfen hat. Wenn du über den üblichen kurzfristigen Lärm auf Binance hinausblickst und den tatsächlichen Rohren folgst, die für die Zukunft der künstlichen Intelligenz gelegt werden, ist es eine äußerst logische Entscheidung, ein sehr genaues Auge auf die Entwicklung des Open-Ökosystems zu haben.
Was haltet ihr davon? Glaubt ihr, dass dezentrale Infrastruktur wie OpenLoRA realistisch den Monopol von Big Tech auf KI-Hardware und Daten brechen kann? Lasst uns in den Kommentaren unten diskutieren! 👇
#OpenLedger #DecentralizedAI #DePIN #BinanceSquare #CryptoInfrastructure @OpenLedger