There is a structural contradiction sitting at the center of the modern AI industry, and very few people are talking about it seriously.
The largest AI systems in the world the ones powering enterprise tools, consumer products, and automated workflows were built on data contributed by millions of individuals. Researchers, writers, developers, and domain specialists produced that knowledge over years. It was scraped, labeled, filtered, and fed into training pipelines. The companies that controlled those pipelines captured the value. The people who created the underlying data did not.
This is not a philosophical complaint. It is becoming a legal and regulatory reality. Europe's AI Act is already pushing for provenance documentation on training data. Questions about consent, commercial usage rights, and data ownership are moving from academic debate into courtrooms and compliance departments.
The question is: what does a genuine infrastructure-level solution to this problem actually look like?
The attribution problem
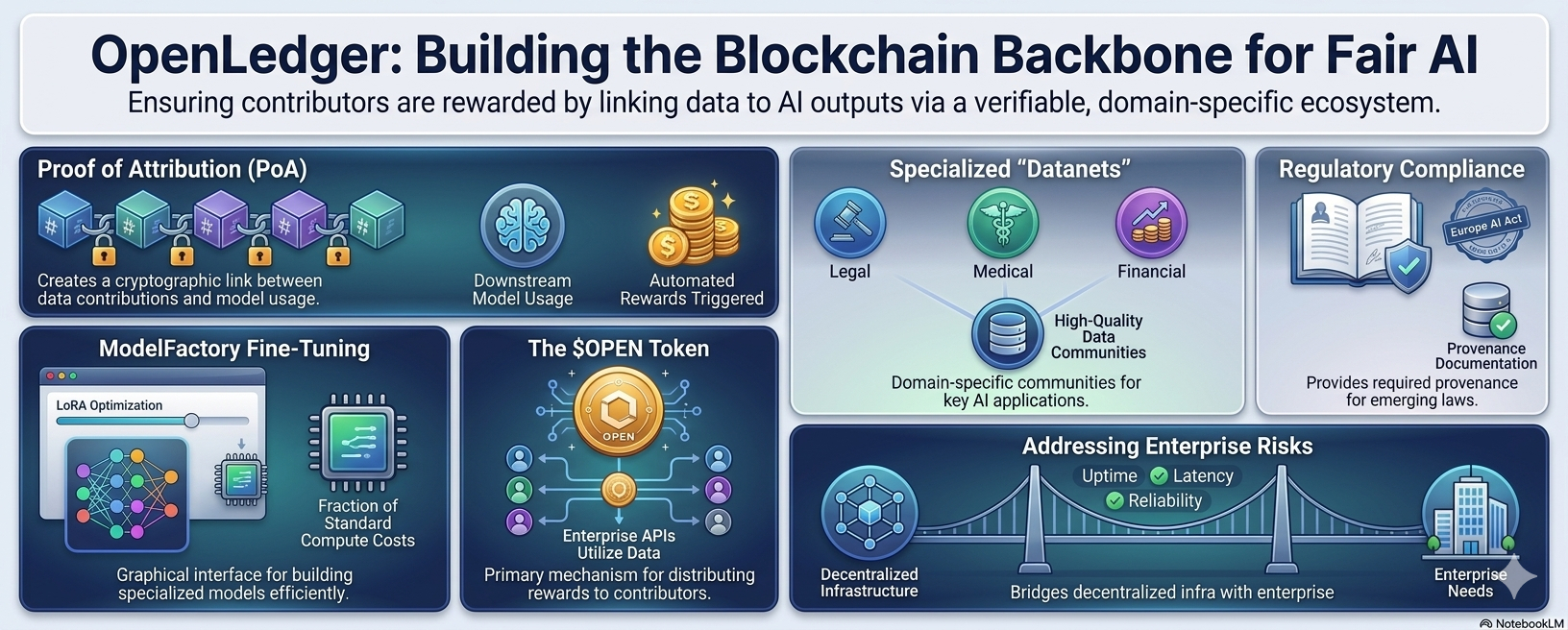
Saying "we will track data ownership on-chain" is easy. Delivering it at scale is an entirely different challenge. The difficulty is not in recording a transaction blockchain handles that efficiently. The difficulty is in tracing which data influenced which model output at inference time, then distributing rewards proportionally and automatically across potentially thousands of contributors.
This is the problem @OpenLedger is attempting to solve with their Proof of Attribution mechanism. The system aims to create a cryptographic link between a data contribution and its downstream usage inside AI models — so that when an enterprise calls an API, the system can trace back the data lineage and trigger an automated reward distribution to the relevant contributors in $OPEN tokens.
If this works at scale, it fundamentally changes the incentive structure of AI development. Contributors would have a financial reason to provide high-quality, domain-specific data rather than generic content. Model builders would have access to a verified, attribution-tracked data ecosystem rather than unverifiable scraped datasets. Enterprise clients would have the provenance documentation that regulators are beginning to demand.
Datanets niche intelligence as a community asset
The broader context for this attribution layer is OpenLedger's Datanets concept. Rather than building one large general-purpose dataset, the project is structured around domain-specific data communities clusters of contributors focused on areas like legal documentation, medical records, financial data, and technical research.
The reasoning behind this is sound. The future of AI is not a single large model that handles everything. It is a network of specialized models that handle specific domains with precision. A healthcare AI needs verified clinical data. A legal AI needs structured case documentation. A trading AI needs clean, timestamped financial records. General-purpose datasets are not adequate for these applications and enterprises know it.
Tokenizing this niche data economy, if executed properly, creates a marketplace where specialized knowledge has genuine commercial value rather than being extracted for free.
ModelFactory and the question of accessibility
Alongside the data layer, OpenLedger has built ModelFactory a graphical interface for fine-tuning large language models using data sourced from Datanets. The platform supports models including LLaMA, Mistral, DeepSeek, and Qwen, with LoRA and QLoRA optimization for cost-efficient fine-tuning.
The practical significance of LoRA-based fine-tuning should not be underestimated. Full model training requires infrastructure that only well-funded organizations can access. Lightweight adaptation methods have changed that calculus. Running a specialized model on a fraction of the original compute cost is now realistic and OpenLedger is building its developer tooling around this reality.
Whether ModelFactory succeeds will depend on how clean the developer experience actually is in production, not in a demo environment. GUI-driven workflows can reduce barriers significantly, but the underlying complexity of model training does not disappear it gets abstracted. The quality of that abstraction will determine adoption.
Where the genuine risks sit
Intellectual honesty requires acknowledging the challenges that any decentralized AI infrastructure project faces, and OpenLedger is not exempt from them.
Enterprise adoption is the hardest problem. Large organizations evaluating AI infrastructure prioritize uptime, latency, compliance guarantees, and support contracts. Decentralized networks, by design, do not offer the same centralized accountability that enterprises are accustomed to. Bridging that gap requires more than a well-designed protocol it requires a sustained go-to-market effort and a track record of reliability that takes time to build.
Token sustainability is the second challenge. Buyback mechanisms and reward pools can generate short-term activity, but long-term protocol health depends on real revenue from real usage. Until the enterprise pipeline is generating consistent demand, the token economics will remain speculative.
Governance complexity is the third. Decentralized governance sounds democratic in principle. In practice, protocol-level decisions require technical literacy that the average token holder does not have. How OpenLedger navigates this tension between community ownership and effective decision-making will matter more over time.
The honest assessment
OpenLedger is not a finished product. It is an early-stage infrastructure bet on a thesis that has strong logical foundations: if AI is built on human data, the revenue flow should eventually reach the people who created that data. The Proof of Attribution system, Datanets, and ModelFactory are all components of an architecture designed to make that thesis operational.
The risks are real. Enterprise adoption is slow. Token economics are difficult to sustain in the short term. And decentralized AI infrastructure is a category that has not yet proven itself at production scale.
But the problem being addressed is real. The regulatory pressure supporting it is growing. And the technical approach attribution-tracked data, specialized model ecosystems, lightweight fine-tuning is grounded in where AI development is actually heading.
That combination makes it worth following seriously.