There's a specific kind of cognitive dissonance that hits me every time I read OpenLedger's documentation about data ownership. The architecture is built on a premise that sounds self-evident: data contributors own their contributions and should be compensated for them. On-chain Datanets track every data point back to its source. Attribution is cryptographic, immutable, and auditable. From a technical standpoint, this is as clean a provenance system as anyone has built for AI training data. From a legal standpoint, it is sitting on top of one of the most fractured and contested areas of intellectual property law in human history, and OpenLedger's documentation behaves as though that layer of the problem has already been solved by someone else. It hasn't.
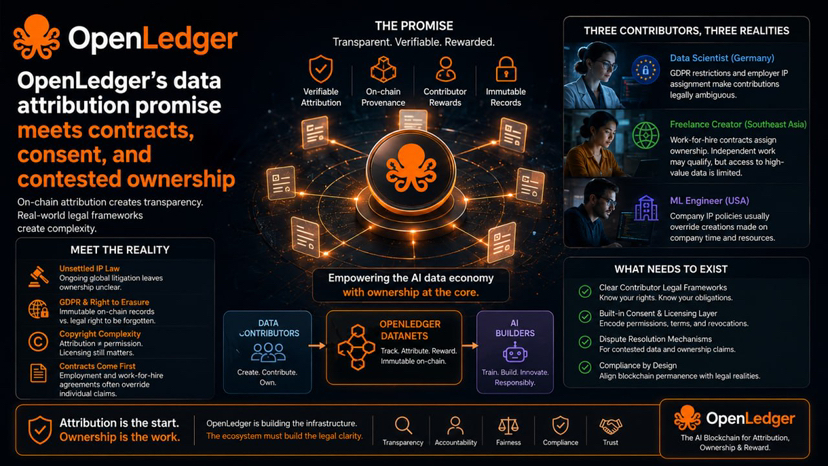
I spent time thinking through what OpenLedger's Datanet model would mean for three different people in different professional contexts. Not as a thought experiment, but as a genuine attempt to understand where the attribution architecture works and where it bumps into a wall that no amount of technical elegance can climb over. The first person I thought about is a data scientist at a healthcare company in Germany. The second is a freelance content creator in Southeast Asia who generates annotated datasets for AI companies on contract. The third is a machine learning engineer at a US tech firm who builds internal proprietary datasets on company time. All three contribute to the AI training data economy in real ways. None of them can use OpenLedger's Datanet structure with the same clarity, because the legal reality of who owns their data contributions is entirely different in each case, and OpenLedger has not published a clear framework for any of them.
The German data scientist works with patient-adjacent datasets under GDPR constraints and employment contracts that typically assign intellectual property created during employment to the employer. Even if OpenLedger's on-chain attribution system correctly records her contribution and issues her OPEN tokens, those tokens might represent a payment for something she doesn't legally own the right to contribute. The OpenLedger architecture is technically correct and legally ambiguous in the same breath. The on-chain record exists. The legal ownership question doesn't care about the on-chain record, and it won't until a court or regulator says otherwise. The documentation OpenLedger provides assumes data ownership is settled before the contribution happens. In practice, data ownership is one of the most actively litigated questions in IP law right now, with ongoing cases involving some of the largest AI companies in the world, and OpenLedger hasn't acknowledged this in any way that tells contributors what they should do before clicking "contribute."
The freelance creator faces a different structural problem. She produces annotated training datasets under work-for-hire agreements, which typically assign all output to the contracting company. If she contributes her own independent work to an OpenLedger Datanet, the legal picture is cleaner, but she also may not have the specialized domain knowledge to produce the kind of data that OpenLedger's SLM thesis actually requires. OpenLedger's influence score rewards high-quality, high-impact contributions. The people most capable of producing that kind of data, domain experts with years of specialized knowledge, are often the people whose employment and contractual arrangements most complicate their ability to contribute it freely and unambiguously. OpenLedger's incentive mechanism is well-designed. The population it needs to attract is the one it has the least legal access to.
The machine learning engineer at the US tech firm appears to be the cleanest case, and even he's not that clean. He builds internal datasets on company time with company resources. His employment agreement almost certainly includes an IP assignment clause covering anything he creates that relates to his employer's business. If he takes related knowledge and creates genuinely original datasets in his own time, outside the scope of his employment, for an OpenLedger Datanet, that might be fine, but it requires deliberate legal navigation that OpenLedger's interface does not acknowledge or support. The Datanet contribution flow is smooth. The legal homework a contributor needs to do before that contribution is something OpenLedger hasn't built into its user experience or documentation in any visible way.
The GDPR issue alone deserves serious attention. European data protection regulation gives individuals the right to erasure of their personal data under specific conditions. This right is not optional and not waivable by contract with a third party. But OpenLedger's on-chain architecture is immutable by design. Once data is contributed to a Datanet and attributed on-chain, that record is permanent. If that data contains or was derived from personal data about identifiable individuals, a right-to-erasure request creates a direct collision between OpenLedger's core architectural property and a mandatory legal requirement. OpenLedger has not published a clear answer to this conflict. The documentation doesn't mention GDPR at all as far as I can find. This isn't an edge case for a European market expansion. It's a fundamental tension between the protocol's design and the legal framework governing data creation in one of the world's largest economies, and OpenLedger is currently hoping the question doesn't come up rather than answering it.
The copyright dimension is equally uncomfortable. The current wave of litigation against AI companies for training on copyrighted material without licensing has not resolved. Multiple ongoing cases are working through court systems in the United States and Europe with genuinely uncertain outcomes. OpenLedger's attribution architecture adds a layer of transparency that could, in theory, help clarify exactly which copyrighted material influenced a model, which cuts both ways. It might support fair use arguments by providing a detailed audit trail. It might equally make infringement arguments easier to prove by demonstrating precisely which protected content was used and how much it contributed to model behavior. OpenLedger's on-chain attribution could become a plaintiff's best evidence tool in future AI copyright cases. The project has not published any guidance on how Datanet contributors should think about the copyright status of what they're contributing.
What I think OpenLedger actually is, underneath the broad framing, is a technically excellent transparency layer for data contributions where contributors have clear, uncontested ownership of what they're contributing. For open-source data, community-generated original content, and contributions by independent creators working cleanly outside employment IP agreements, OpenLedger's Datanet system creates genuine value. It converts anonymous contribution into attributed, compensated, auditable contribution. That's meaningful progress. But the $500 billion data problem includes enormous quantities of data where ownership is contested, regulated, or contractually encumbered, and OpenLedger's architecture has no mechanism for navigating any of that complexity. The attribution system records what flows through it. It cannot transform disputed data ownership into settled data ownership by recording the transaction on a chain.
None of this changes the quality of OpenLedger's engineering. The Datanet mechanism is genuinely thoughtful. The incentive design is more sophisticated than most data market attempts that came before it. But the framing around what OpenLedger "solves" continues to outrun what the legal and institutional environment will actually allow the architecture to touch, and that gap isn't going to be closed by a protocol upgrade. OpenLedger needs legal partnerships, regulatory engagement, and jurisdiction-specific guidance for contributors before the $500 billion claim becomes credible outside the community data context. What it has built right now is a powerful system for the subset of the data problem where ownership is already clear. How large that subset actually is, measured in training data value rather than enthusiasm, is the question I'd most like OpenLedger to answer.