Ich habe die Architektur von Openledger durchforstet, besonders wie sie die Datenattribution und die Belohnungen für Mitwirkende handhabt. Ehrlich gesagt, der interessante Teil ist nicht nur "KI plus Blockchain". Es geht darum, ob das Netzwerk chaotische KI-Beiträge in etwas wirtschaftlich Messbares umwandeln kann.
Die meisten Leute denken, Openledger ist nur ein weiteres KI + Krypto-Token. Das ist die einfache Sicht. Aber was meine Aufmerksamkeit erregte, ist der Versuch, mehrere Rollen gleichzeitig zu koordinieren: Datenbeitragsleistende, Validatoren, Modellbauer und Nutzer, die Nachfrage schaffen.
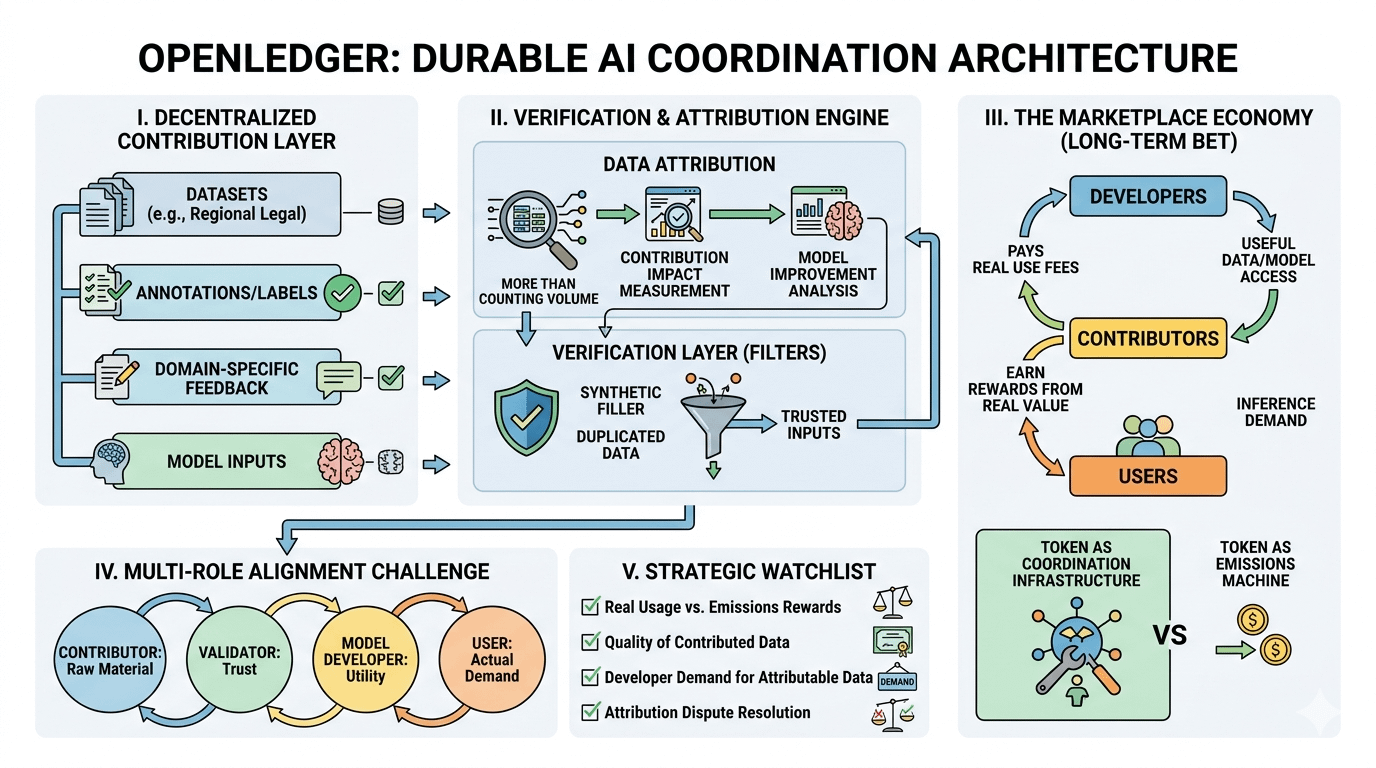
Die dezentrale Beitragschicht ist das erste Stück. Beitragende können Datensätze, Annotationen, Feedback oder domänenspezifische Eingaben in das Netzwerk einbringen. Das könnte für Nischendaten von Bedeutung sein - sagen wir regionale Rechtsdokumente, medizinische Notizen oder branchenspezifische Labels, die große zentralisierte Systeme möglicherweise nicht sauber sammeln.
Dann gibt es die Attribution. Und das ist der Teil, über den ich ständig nachdenke. Wenn ein Modell sich verbessert, nachdem es beigetragene Daten verwendet hat, wie weiß das Protokoll, welche Eingaben tatsächlich wichtig waren? KI-Modelle erstellen keine sauberen Quittungen. Ein kleiner Datensatz könnte einen Edge-Case mehr verbessern als ein riesiger generischer Upload. Daher muss Attribution mehr sein als nur Volumen zählen.
Die Marktplatzseite ist die langfristige Wette. Idealerweise zahlen Entwickler für nützliche Daten oder Modellzugang, Nutzer schaffen Inferenznachfrage, und Beitragende verdienen an echtem nachgelagertem Wert. Der Token wird dann zur Koordinationsinfrastruktur, nicht nur zu einer Emissionsmaschine.
Aber das ist auch die Spannung.
Wenn Belohnungen hauptsächlich aus Tokenemissionen stammen, bevor echte Nachfrage existiert, werden die Leute das System farmen. Duplizierte Datensätze, synthetische Füller, wenig Aufwand bei den Labels - all das wird zu rationalem Verhalten. Die Verifizierungsschicht muss also stark genug sein, um Spam zu filtern, ohne sich in einen zentralisierten Torwächter zu verwandeln.
Wer schafft hier eigentlich Wert? Der Beitragende liefert Rohmaterial. Der Validator schafft Vertrauen. Der Modellentwickler verwandelt Eingaben in etwas Nutzbares. Der Nutzer schafft tatsächliche Nachfrage. Openledger muss alle zusammenbringen, und das ist schwierig.
Die größere Annahme ist, dass sich die KI-Entwicklung im Laufe der Zeit modularer gestaltet. Wenn kleinere spezialisierte Modelle externe Datenmärkte und transparente Herkunft benötigen, macht Openledger mehr Sinn. Wenn geschlossene Plattformen weiterhin den gesamten Stack kontrollieren, könnte das Netzwerk nützlich, aber eng bleiben.
beobachten:
* Belohnungen aus echtem Gebrauch versus Emissionen
* Qualität der beigetragenen Datensätze im Laufe der Zeit
* Entwicklernachfrage nach zuordenbaren Daten
* Wie Attributionsstreitigkeiten gehandhabt werden
Noch kein sauberes Fazit. Openledger könnte eine echte KI-Koordinationsschicht aufbauen. Oder es könnte testen, ob Tokenanreize Nachfrage schaffen können, bevor der Markt klar danach gefragt hat.@OpenLedger $OPEN #openledger