Most people still talk about AI like it’s just a model problem.
Bigger models. Better benchmarks. More GPUs. Faster inference.
That’s the surface-level conversation.
But honestly, something way more important is happening underneath all of that. AI tooling is slowly merging with economic infrastructure. And once you notice it, you can’t really unsee it.
That’s why the connection between OpenLedger and ModelFactory actually matters.
Not because somebody slapped “AI + blockchain” into a pitch deck. We’ve all seen that movie already. Usually ends badly.
What’s interesting here is the shift from “here’s a tool that helps you fine-tune models” into “here’s a system that tracks, measures, coordinates, and potentially monetizes the entire AI lifecycle.”
That’s a very different thing.
And yeah, the technical side matters too.
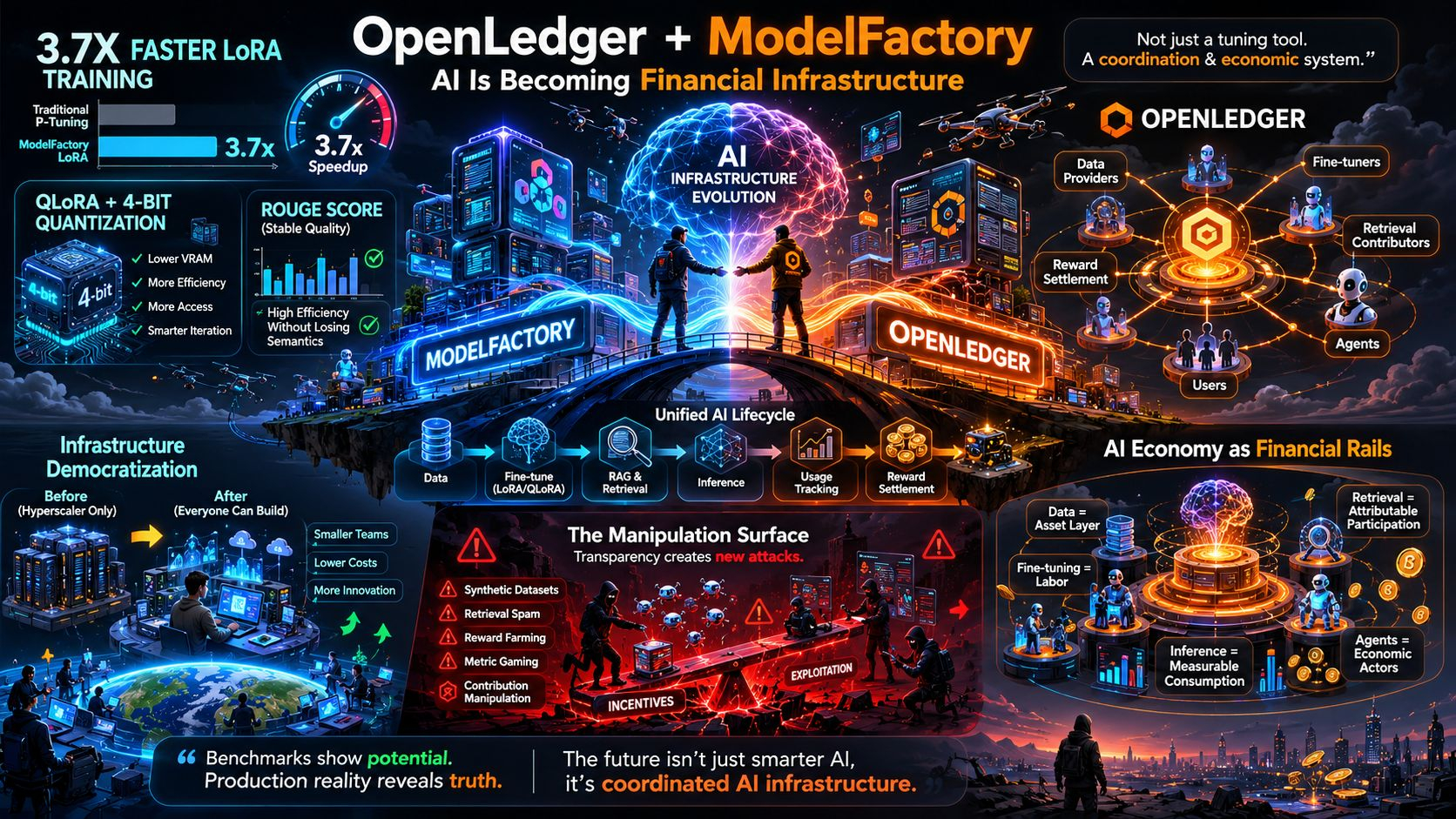
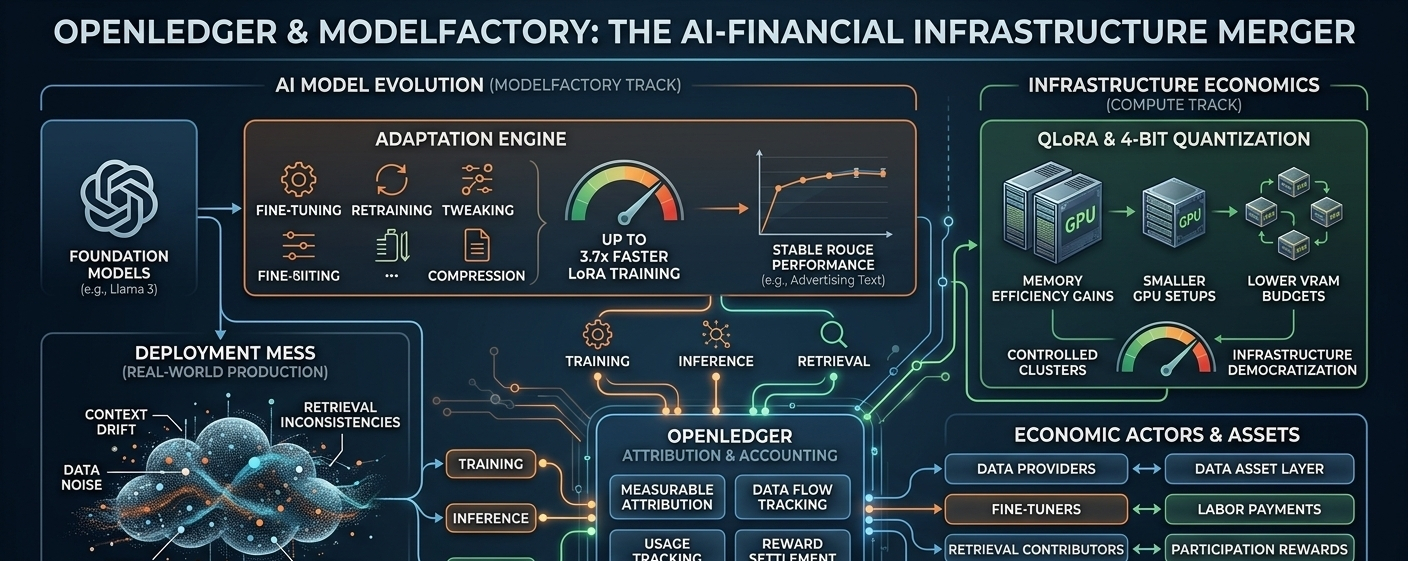
The ModelFactory stack reportedly pushes LoRA training speeds up to 3.7x faster compared to traditional p-tuning approaches. That’s not a tiny optimization. That’s the kind of jump that changes operational behavior.
Because here’s the thing people don’t talk about enough: most AI teams don’t build foundation models from scratch anymore. They adapt them. Constantly.
They fine-tune. They retrain. They tweak. They compress. They ship. Then they retrain again because production data always turns messy.
Always.
So if you suddenly cut tuning time down that aggressively, you’re not just saving compute. You’re changing iteration speed. And iteration speed matters more than people admit.
A lot more.
Shorter cycles mean smaller teams can experiment faster. Developers can test domain-specific models without burning insane GPU budgets. Companies can run more adaptation passes before deployment.
It sounds boring on paper.
It isn’t.
Speed changes behavior.
But let’s be real for a second. Benchmark numbers by themselves don’t mean much anymore. Everybody has benchmark slides now. Every project has some chart showing “faster training” or “lower latency” or “better efficiency.”
Cool.
What matters is whether the model still holds together once real-world chaos hits it.
That’s where the ROUGE score discussion gets important.
ModelFactory claims the system keeps ROUGE performance stable during practical workloads like advertising text generation while still hitting those efficiency gains. That’s actually meaningful because optimization systems usually trade something away. You rarely get free wins forever.
And ROUGE consistency at least suggests the tuning pipeline preserves semantic quality well enough for production usage.
But honestly? I’d still be cautious.
ROUGE is useful. I’m not dismissing it. But production environments are ugly. They’re noisy. Data pipelines break constantly. Labels drift. User behavior changes every week. Half the retrieval data in enterprise systems looks like somebody exported it from a dying spreadsheet in 2017.
Benchmarks don’t capture that mess.
I’ve seen systems perform beautifully in controlled evaluations and then slowly degrade once they interact with real users for six months.
That’s where things get tricky.
Because subtle failures don’t show up immediately. They creep in quietly:
Context drift
Retrieval inconsistencies
Long-chain reasoning instability
Weird multilingual edge cases
Hallucination spikes under sparse prompts
And once you stack RAG systems on top of compressed fine-tuning pipelines? Things get even fuzzier.
People love clean AI narratives. Real deployments are never clean.
Ever.
Now let’s talk about the part that actually changes infrastructure economics: QLoRA and 4-bit quantization.
This is where the conversation stops being “AI optimization” and starts becoming “compute redistribution.”
Big difference.
For years, serious AI work basically belonged to whoever controlled massive GPU clusters. If you didn’t have huge VRAM budgets or hyperscaler access, good luck.
Then QLoRA showed up and changed the equation a bit.
Not completely. But enough.
By combining low-rank adaptation with aggressive quantization, developers suddenly gained ways to fine-tune large models without needing absurd hardware setups. And 4-bit quantization matters here because memory efficiency changes accessibility.
A lot.
Stuff that once demanded enterprise-grade infrastructure can now run on smaller GPU setups, lighter cloud instances, even distributed environments people previously considered underpowered.
That’s not hype. That’s operational reality.
And honestly, this might be one of the most underrated structural shifts happening in AI right now.
Infrastructure democratization sounds like a buzzword until you realize what it actually means:
More people can build.
More people can experiment.
More people can participate in the AI layer without needing millions in compute funding.
That changes market structure over time.
But and this is the part nobody marketing these systems likes emphasizing quantization always comes with trade-offs.
Always.
You compress aggressively enough, and eventually something bends.
Maybe reasoning consistency weakens slightly. Maybe retrieval sensitivity increases. Maybe edge-case failures become harder to predict. Maybe long-term adaptation cycles slowly introduce instability.
And honestly, the industry still doesn’t fully understand the long-horizon effects of heavily quantized systems operating continuously in production.
People act more confident about this than they should.
Especially once autonomous agents enter the picture.
A slightly weaker chatbot? Fine. Most users won’t notice.
An AI agent participating in financial coordination systems while running on compressed reasoning layers?
Yeah. Different story.
Tiny inaccuracies scale into very expensive problems surprisingly fast.
What makes this more interesting is that ModelFactory doesn’t seem content staying “just a tuning tool.”
That’s obvious from the architecture direction.
You can see the transition happening already:
Modular infrastructure
GUI-based workflows
Integrated chat interfaces
End-to-end lifecycle management
Unified tuning and deployment coordination
At first glance, that sounds like standard product evolution. Every platform eventually wants an all-in-one stack.
But I think something deeper is happening here.
Historically, AI systems lived in disconnected silos.
One tool handled training. Another handled deployment. Another monitored inference. Another tracked retrieval. Another handled usage analytics. Another tried monetization afterward like some awkward afterthought.
Messy stack. Constant fragmentation.
Now these layers are collapsing into unified coordination systems where training, inference, attribution, usage tracking, and economic settlement all connect together.
And that’s where OpenLedger enters the conversation in a serious way.
Because OpenLedger isn’t really treating AI as just a model problem.
It’s treating AI as a coordination problem.
That’s a much bigger idea.
Coordination means accounting. Accounting means attribution. Attribution means incentives. And incentives change behavior immediately.
That’s the rabbit hole.
The integration between ModelFactory and OpenLedger starts pointing toward something larger than “AI tooling.”
It starts looking like financial rails for AI participation itself.
And honestly, the industry hasn’t figured out how weird this gets yet.
Because once you build systems around RAG attribution, transparent data flows, usage tracking, and reward settlement, you immediately run into three uncomfortable questions:
Whose data?
How do you track contribution accurately?
Where does the value actually settle?
AI companies have mostly avoided these questions so far because current systems are wildly opaque.
Data gets scraped. Models get trained. Outputs get monetized. Nobody really knows who contributed what anymore.
OpenLedger seems to push toward measurable attribution layers where data providers, fine-tuners, retrieval contributors, and possibly even autonomous agents become economically visible participants.
Conceptually, that’s fascinating.
Practically? It gets messy fast.
Because the second rewards become measurable, people start optimizing against the system.
Every time.
You don’t need to guess. We’ve watched this happen across literally every incentive-driven platform on the internet.
Spam follows incentives. Gaming follows rewards. Manipulation follows visibility.
Always.
So now imagine an AI economy where:
Retrieval paths generate payouts
Data contributions receive rewards
Agent interactions trigger settlements
Usage tracking determines compensation
You know what happens next?
People build systems specifically designed to exploit attribution logic.
Synthetic datasets flood the network. Low-quality retrieval spam explodes. Agent swarms farm rewards. Contribution metrics get manipulated. Coordination layers become attack surfaces.
That’s where things get really interesting.
Because transparency solves some problems while simultaneously creating entirely new ones.
And I don’t think enough people appreciate that tension yet.
Honestly, the biggest takeaway here isn’t the 3.7x LoRA speedup. It’s not even the QLoRA memory efficiency gains.
Those matter. Obviously.
But the deeper shift is structural.
AI infrastructure is slowly evolving into an economic system where:
Data becomes an asset layer
Fine-tuning becomes labor
Inference becomes measurable consumption
Retrieval becomes attributable participation
Agents become economic actors
That changes the entire shape of the stack.
And once AI systems start coordinating value flows directly, infrastructure design suddenly matters as much as model intelligence itself.
Maybe more.
But here’s the uncomfortable part: the more automated and transparent these systems become, the larger the manipulation surface grows too.
Benchmarks won’t tell you that. ROUGE scores won’t tell you that. Quantization charts definitely won’t tell you that.
Production reality will.
Because the real stress test starts when millions of participants begin optimizing for rewards inside the system itself.
That’s the moment where elegant infrastructure diagrams collide with human behavior.
And human behavior breaks clean systems faster than bad code ever will.