The history of machine learning is, in large part, a history of data quality problems masquerading as model problems. A model that performs poorly on a specific task is usually blamed first for insufficient parameters, insufficient training compute, or insufficient fine-tuning. In most cases, the actual cause is that the training data for that task was low quality, incorrectly labeled, domain-incomplete, or silently biased in ways that didn't surface until deployment. The model learned what it was taught. It was taught the wrong thing.
This is not a solved problem in 2026. The emergence of large language models has made it more acute, not less. The bigger the model, the more training data it ingests, and the more thoroughly any systematic bias or labeling error in that data gets encoded into the model's behavior. Getting the data right matters more as models get bigger, not less. And getting domain-specific data right is the hardest version of this problem because it requires domain expertise to recognize errors that a general-purpose evaluator cannot see.
OpenLedger's Datanets are positioned as the infrastructure layer for exactly this problem. Specialized training data for domain-specific models, community-validated, influence-attributed, and compensated through on-chain mechanics. The ambition is right. The architecture is coherent. The question is whether the community validation model, as currently designed, can actually deliver domain-accurate data for the domains that matter most.
Let me walk through where the challenge actually sits.
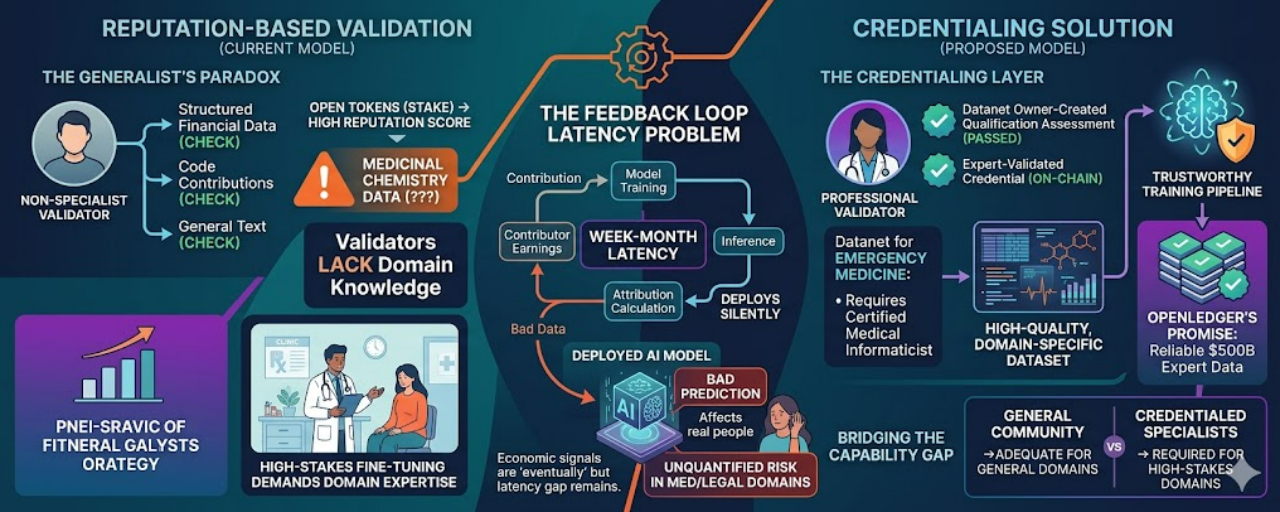
The Datanet validator role is the quality gate. Validators review contributed data, assess whether it meets the Datanet's quality standards, and approve or reject submissions. Their reputation on-chain, combined with the staking amount, determines their weight in the validation process. High-reputation, high-stake validators have more influence over which data enters the training pipeline.
This model works reasonably well for data domains where quality is objective and assessable by a reasonably informed community member. Structured financial data with verifiable fields, publicly available scientific data with published benchmarks, code contributions that can be syntax-checked and tested: these are domains where community validation is credible.
But consider the domains where training data has the most economic and social value. Clinical decision support models need training data validated by clinicians. Legal reasoning models need data validated by practicing attorneys. Financial modeling systems need data validated by quantitative analysts. Drug discovery models need data validated by medicinal chemists. In every one of these domains, quality assessment requires not just domain familiarity but active professional practice. These are not skills that transfer from staking OPEN tokens.
The comparison to Ocean Protocol's experience is instructive here. Ocean Protocol was one of the earliest crypto-native attempts to build a data marketplace, and its core challenge was not the blockchain mechanics or the tokenomics. Its core challenge was that the data listed in its marketplace was of uncertain quality because there was no credible validation layer for domain-specific datasets. Buyers couldn't trust what they were purchasing. The marketplace filled with low-value, easily available data rather than the high-value, domain-specific datasets that would justify a decentralized marketplace's existence.
OpenLedger's influence attribution system addresses part of this problem in an interesting way. If bad data enters the training pipeline and doesn't improve model performance, its influence score is low and its contributor earns little. The economic signal eventually discourages bad contributions. This is a meaningful improvement over Ocean Protocol's model, where there was no post-contribution accountability mechanism.
But 'eventually' is doing a lot of work in that sentence. 🤔
The feedback loop from contribution to influence score runs through model training, which takes time. It then runs through inference, which takes more time. And then it runs through attribution calculation, which requires enough inference calls to produce statistically meaningful influence signals. In a domain where models are being fine-tuned and evaluated carefully, this feedback loop might run in weeks to months. In a domain where models are deployed quickly to production, the feedback loop might run for months before bad data's contribution to bad outputs is quantified.
During that window, the bad data has trained and deployed into a model that's making real predictions. In medical or legal domains, those predictions might inform real decisions. The economic accountability of OpenLedger's attribution system is real. The latency of that accountability is a gap between the claim and the protection it provides.
OpenLedger's documentation doesn't address this latency problem explicitly. It doesn't describe how high-stakes Datanets should handle the period between contribution and attribution feedback. It doesn't recommend that Datanet creators in medical or legal domains require validator credentials before those validators can participate.
The proposed solution, or at least the most natural extension of the current design, would be a credential layer for Datanet-specific validation. A Datanet for emergency medicine clinical notes could require validators to pass a domain qualification assessment before they can evaluate contributions. That assessment could be created by the Datanet owner, reviewed by the community, and its results stored on-chain as part of the validator's reputation profile. A validator who has passed a medical domain assessment earns more weight when validating medical Datanet contributions. A validator who has passed a legal domain assessment earns more weight in legal Datanets.
This is more complex than the current model. It requires Datanet owners to create qualification assessments, which is non-trivial work. It requires a mechanism to prevent gaming of those assessments. It requires the community to trust the assessment content, which is itself a governance question.
But it's the kind of complexity that the problem actually requires. The shortcut, which is to assume that economic incentives will produce domain expertise without domain qualification, is not supported by the history of data quality problems in machine learning or by the experience of comparable platforms that tried the same shortcut. 😬
What this means practically: OpenLedger's current Datanets will likely fill first with domains where community validation is adequate. Financial data with verifiable fields. Code data with testable outputs. General-purpose text data with measurable performance benchmarks. These are real and valuable. They're just not the domains that justify the $500 billion framing.
The $500 billion estimate, to the extent it's meaningful at all, is anchored in the value of specialized, expert-validated, domain-specific training data that currently flows through centralized, expensive, slow pipelines. Capturing that value requires solving the validator expertise problem. And the documentation, at its current level of detail, hasn't shown how that problem gets solved.
That's the unsolved problem inside the architecture. Not the attribution math. Not the tokenomics. The human expertise problem that no blockchain mechanic alone can address.
@OpenLedger $OPEN #OpenLedger $BSB
