Ich habe vor ein paar Tagen das Whitepaper zur Attributionsbewertung durchgesehen und war auf der Suche nach der üblichen, hochrangigen technischen Darstellung, die die meisten KI-Blockchain-Projekte verwenden, um Mechanismen zu beschreiben, die sie nicht vollständig implementiert haben. Das ist der Standard. Veröffentliche ein Whitepaper, das auf eine Methodik hinweist, bringe ein Produkt heraus, das dem entspricht, und hoffe, dass niemand die Lücke zwischen beiden nachverfolgt. Das Whitepaper von Openledger ist tatsächlich nicht so. Es beschreibt zwei spezifische Attributionsansätze mit echtem technischen Tiefgang: Einflussfunktion-Näherungen für kleinere Modelle und suffix-array-basierte Tokenattribution für größere. Die Methodik ist real. Jemand hat sorgfältig darüber nachgedacht.
Dann habe ich den Suffix-Array-Ansatz genauer gelesen.
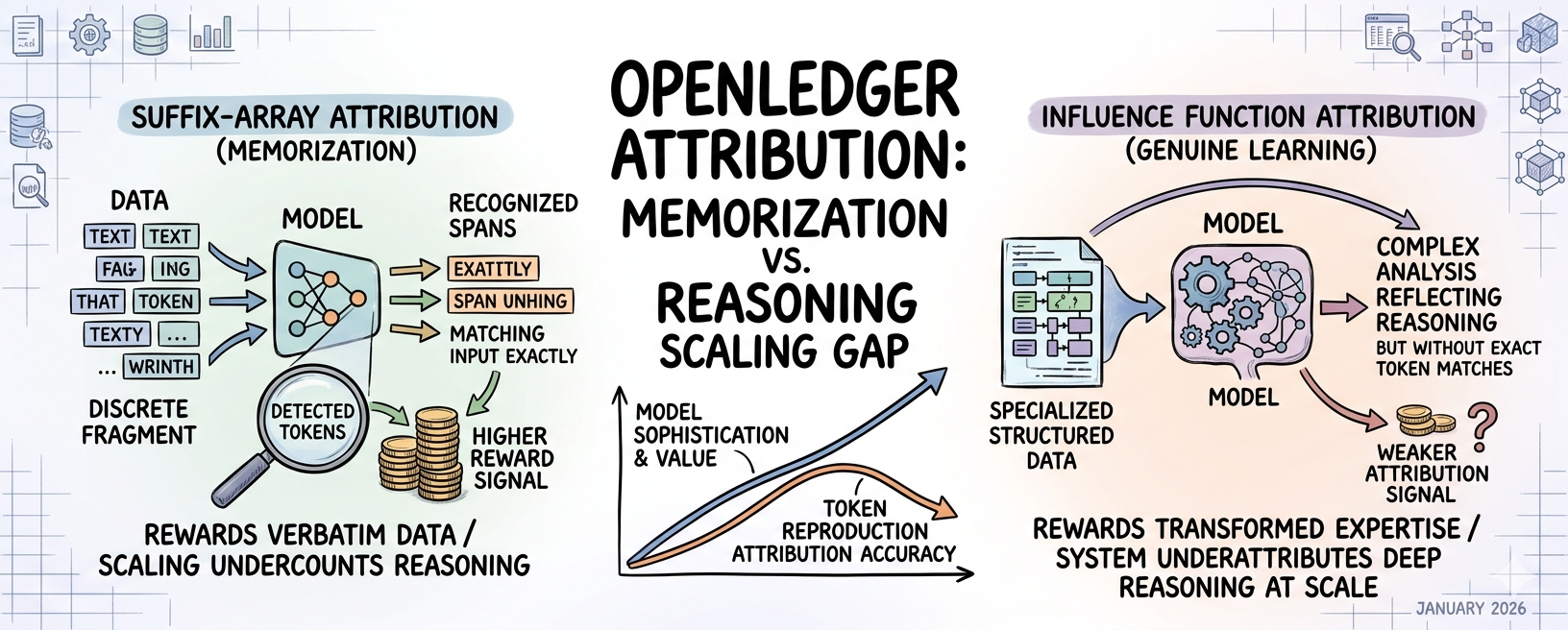
Die Suffix-Array-Attribution funktioniert, indem sie das Trainingskorpus komprimiert und überprüft, ob Ausgabetokens in memorierten Spannen aus diesem Korpus erscheinen. Die Idee ist, dass, wenn die Ausgabe eines Modells Token-Sequenzen enthält, die mit komprimierten Trainingsdaten übereinstimmen, man diesen Einfluss bestimmten Mitwirkenden zuordnen kann. Es ist eine legitime Technik. Aber sie hat eine spezifische Skalierungseigenschaft, die im Whitepaper anerkannt wird, auf eine Weise, die die meisten Leser ohne innehalten übersehen würden: Der Ansatz identifiziert memorierte Spannen, nicht beeinflusstes Reasoning. Ein Modell, das wirklich aus Domänenexpertise gelernt hat, wird Ausgaben produzieren, die diese Expertise widerspiegeln, ohne notwendigerweise memorierte Token-Sequenzen zu reproduzieren. Der Attributionsmechanismus belohnt den Einfluss, der durch Memorierung nachweisbar ist. Er könnte systematisch die Beiträge von Daten unterbewerten, die dem Modell beigebracht haben, zu reasoning, anstatt die Daten, die das Modell gelernt hat zu reproduzieren. 🔍
Diese Unterscheidung ist enorm wichtig für das, was Openledger zu bauen versucht. Das gesamte Wertversprechen spezialisierter Sprachmodelle – der Grund, warum Datanets existieren, der Grund, warum Mitwirkende domänenrelevante Daten bereitstellen sollten statt gescraptem Text – ist, dass echte Domänenexpertise besseres Reasoning produziert, nicht nur bessere Memorierung. Ein juristisches Modell, das auf sorgfältig strukturierten Vertragsanalysen trainiert wurde, sollte Ausgaben produzieren, die juristisches Reasoning widerspiegeln, nicht Ausgaben, die juristische Sprache wörtlich reproduzieren. Aber die Suffix-Array-Attribution misst den zweiten Einfluss-Typ zuverlässiger als den ersten. Während die Modelle skalieren und ihre Ausgaben weniger reproduktiv ähnlich zu den Trainingsdaten werden und mehr wirklich transformiert sind, könnte der Attributionsmechanismus progressiv ungenauer werden, genau in dem Moment, in dem die Modelle am anspruchsvollsten und wertvollsten werden.
Ich sitze mit einer spezifischen Implikation, die ich nicht vollständig auflösen kann. Die Mitwirkenden, die die wertvollsten Daten bereitstellen – Domain-Experten, die strukturierte Analysen und sorgfältig begründete Beispiele beitragen, anstatt nur Rohtexte – könnten systematisch weniger gewürdigt werden im Vergleich zu Mitwirkenden, die große Mengen an textlastigen Daten mit einprägsamen Token-Sequenzen liefern. Beide Mitwirkenden-Profile würden Attributionsevents sehen. Aber der Einfluss des Expertenbeitrags, der durch reasoning Transformation und nicht durch Token-Reproduktion funktioniert, würde schwächere Attributionssignale unter Suffix-Array-Matching erzeugen. Die Belohnungsstruktur scheint zu funktionieren. Die Verteilung der Belohnungen innerhalb dieser Struktur könnte jedoch nicht mit der Verteilung des tatsächlich geleisteten Wertes übereinstimmen.
Ich habe etwas strukturell Ähnliches mit Ranking-Algorithmen von Suchmaschinen in den frühen 2010er Jahren beobachtet. Die Algorithmen maßen, was sie messen konnten: Linkdichte, Schlüsselworthäufigkeit, Textwiederholung, weil diese Signale technisch greifbar waren. Was sie nicht direkt messen konnten, war das, was sie tatsächlich messen wollten: echte Expertise und autoritatives Wissen. Das Ergebnis war, dass Inhalte, die für messbare Signale optimiert waren, Inhalte mit echter Expertise übertrumpften, bis die Algorithmen genug entwickelt waren, um diese Lücke zu schließen. Die Optimierung geschah nicht, weil die Inhaltsersteller böswillig waren, sondern weil die Messung systematisch von dem zugrunde liegenden Wert abwich. Openledgers Attributionsmechanismus könnte sich genau in derselben frühen Algorithmus-Phase befinden und ein greifbares Proxy für Einfluss messen, anstatt den Einfluss selbst, und das Proxy belohnen statt den Wert.
Das wirklich starke Element hier ist, dass das Whitepaper die Einschränkungen der Methodik anerkennt, anstatt sie zu verbergen. Diese Transparenz ist mehr als die meisten KI-Blockchain-Projekte bieten, und sie signalisiert, dass das Team versteht, dass die Messung eine Annäherung ist. Das Update der Attributionsmaschine von Januar 2026 wurde speziell entwickelt, um Daten-Ausgangslinks aufrechtzuerhalten, während sich die Modelle weiterentwickeln, was darauf hindeutet, dass das Team das Skalierungsproblem als etwas identifiziert hat, das aktive Ingenieurarbeit erfordert, anstatt ein theoretisches Anliegen zu sein, das als Fußnote abgetan und vergessen wird.
Es gibt eine Version davon, wo ich falsch liege. Openledger könnte einen hybriden Attributionsansatz in der Produktion implementiert haben, der das Suffix-Array-Matching mit Einfluss-Funktionsgewichtung für größere Modelle ergänzt, wobei die teurere, aber genauere Methode genau dort eingesetzt wird, wo die billigere Methode unzuverlässig wird. Wenn dieser Hybrid existiert und läuft, verschlechtert sich die Attributionsgenauigkeit nicht im großen Maßstab und Expertenmitwirkende werden angemessen gewürdigt. Was ich in der öffentlichen Dokumentation nicht finden konnte, war eine Bestätigung, dass das Produktionssystem einen anderen Ansatz als die primäre Beschreibung des Whitepapers für große Modelle verwendet.
Was ich sehen möchte, ist kein technisches Update des Whitepapers. Ein tatsächlicher öffentlicher Überblick über die Attributionsmethodik nach Modellgröße, speziell, welcher Attributionsansatz derzeit auf welchen Modellen im Mainnet läuft, und ob ein hybrider oder ergänzender Ansatz für Modelle über einem bestimmten Parameterthreshold betrieben wird. Diese Offenlegung, die aus einem Dokumentationsupdate seit dem Update der Attributionsmaschine im Januar erscheinen würde, würde mir sagen, ob die Skalierungsbeschränkung eine bekannte Annäherung ist, die das Team aktiv angeht, oder eine nicht anerkannt Lücke zwischen dem, was das Whitepaper beschreibt und dem, was das Produktionssystem derzeit misst. Ihre Abwesenheit bedeutet, dass Openledgers präziseste Mitwirkenden – die, deren Expertise das Modell-Reasoning anstatt den Wortschatz des Modells transformiert – möglicherweise diejenigen sind, die das System am wenigsten ausstatten kann, um sie zu würdigen. Das ist ein seltsamer Ort für ein Protokoll, dessen gesamtes Wertversprechen darin besteht, dass es den Einfluss von Beiträgen verifizierbar macht, statt angenommen.
