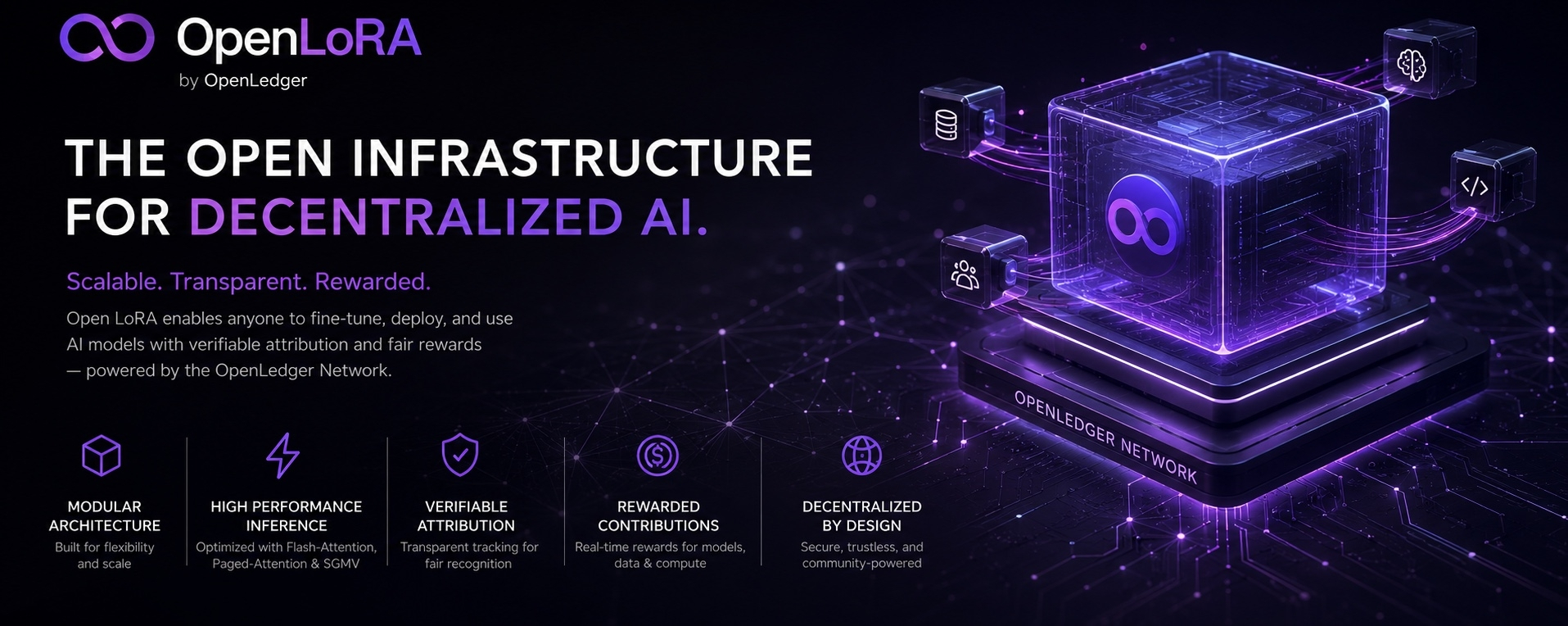
Kernkomponenten
Das Open LoRA Framework ist rund um eine modulare, skalierbare Architektur konzipiert, die eine effiziente Modellbereitstellung, dynamische Inferenz und transparente Zuordnung im OpenLedger-Ökosystem ermöglicht.
LoRA Adapter Speicher
Feinabgestimmte LoRA-Adapter werden sicher innerhalb der dezentralen Infrastruktur von OpenLedger gespeichert. Anstatt jeden Adapter gleichzeitig in den Arbeitsspeicher zu laden, werden Adapter dynamisch basierend auf den Inferenzanforderungen abgerufen und aktiviert, was die Skalierbarkeit und Ressourceneffizienz erheblich verbessert.
Modell-Hosting & Dynamisches Adapter-Merging
Das System arbeitet auf einer gemeinsamen grundlegenden Modellarchitektur, bei der LoRA-Adapter in Echtzeit während der Inferenz zusammengeführt werden. Dieser Ansatz minimiert redundantes Modell-Hosting und ermöglicht eine schnelle Anpassung an verschiedene Aufgaben und Domänen.
Open LoRA unterstützt auch das Zusammenführen mehrerer Adapter im Ensemble-Stil, was es ermöglicht, kombinierte Wissensschichten zu nutzen, um die Inferenzqualität und die Gesamtleistung des Modells zu verbessern.
Hochleistungs-Inferenz-Engine
Die Inferenzschicht wird mit fortschrittlichen CUDA-basierten Beschleunigungstechniken optimiert, einschließlich:
Flash Attention — reduziert den Speicheraufwand und verbessert die Effizienz von Transformern.
Paged Attention — ermöglicht eine effiziente Verarbeitung von langen Kontextsequenzen.
SGMV-Optimierung (Sparse General Matrix Vector Multiplication) — beschleunigt den Inferenzdurchsatz und senkt die Rechenkosten.
Diese Optimierungen bieten zusammen eine latenzarme, produktionsreife Inferenzleistung.
Anfrageweiterleitung & Token-Streaming
Eine dedizierte Anfrageweiterleitungsschicht leitet API-Aufrufe dynamisch an die entsprechenden Adapterkonfigurationen während der Laufzeit weiter. Generierte Ausgaben werden effizient mit optimierten Token-Übertragungskernen gestreamt, um reaktionsschnelle und nahtlose Echtzeitanwendungen zu gewährleisten.
Attributions-Engine
Die Attributionsschicht verfolgt und protokolliert automatisch jede Komponente, die an einem Inferenzprozess beteiligt ist — einschließlich Modelle, Adapter, Datensätze, Rechenressourcen und Mitwirkende.
Das erstellt ein transparentes und überprüfbares Attributionsframework, das:
Stellt faire Anerkennung der Mitwirkenden sicher
Ermöglicht eine genaue Belohnungsverteilung
Hält unveränderliche Nutzungsaufzeichnungen in Echtzeit
OpenLedger Netzwerk
Das OpenLedger Netzwerk fungiert als dezentrale Koordinationsschicht, die Speicher-, Inferenz-, Attributions- und Ausführungssysteme zu einer einheitlichen KI-Infrastruktur verbindet.
Smart Contracts verwalten:
Zugriffsberechtigungen
Attributionsprotokollierung
Nutzungsüberprüfung
Tokenisierte Anreizverteilung
Diese Architektur ermöglicht sichere, skalierbare und vertrauenslose Koordination über den gesamten KI-Lebenszyklus.
#OpenLedger #TradersShiftBTCToStablecoins #Jefferies$1TCryptoIPOMarket
#CashAppUSDCFor60MUsers
@OpenLedger $OPEN $BTC $ETH

