Tôi từng ăn ở một nhà hàng nhượng quyền khá nổi.
Biển hiệu quen. Menu quen. Cách bài trí cũng quen. Dù đó không phải chi nhánh tôi hay đến, tôi vẫn có cảm giác mình biết trước trải nghiệm sẽ diễn ra thế nào.
Đó là điểm hay của franchise: nó làm một mô hình có thể được nhân bản ở rất nhiều nơi mà không cần công ty mẹ tự vận hành từng cửa hàng.
Lúc đọc về OpenLedger, tôi bất ngờ vì cảm giác đó quay lại.
Không phải vì OpenLedger giống nhà hàng. Mà vì dự án này cũng đang cố làm một việc khá giống ở tầng AI: xây một mặt bằng chung để nhiều nhóm khác có thể tự mở “cửa hàng AI” của mình.
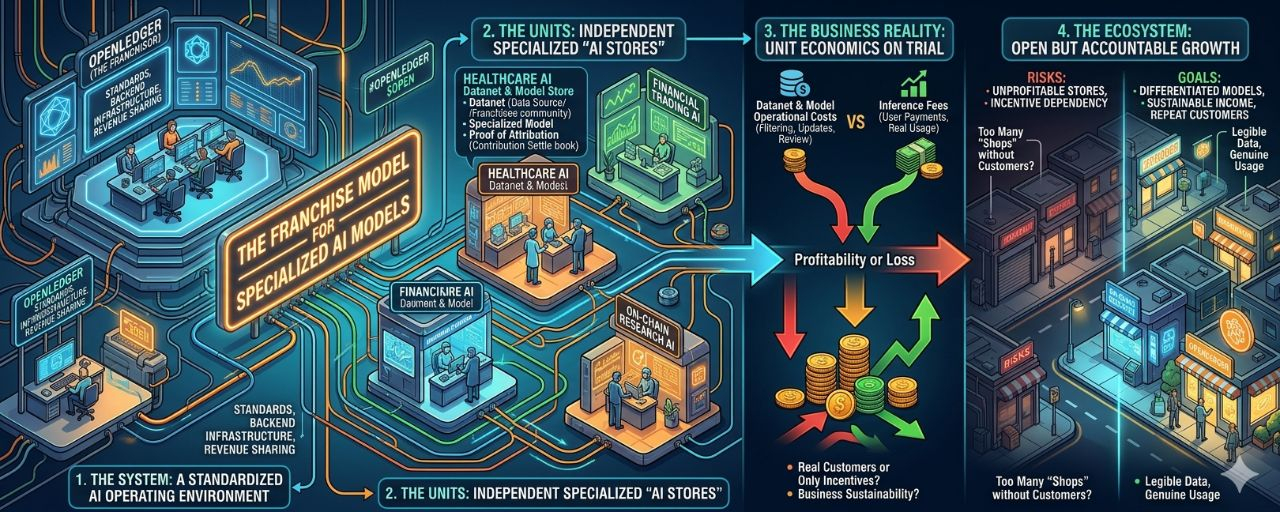
Trong franchise truyền thống, công ty mẹ không chỉ bán thương hiệu. Họ bán cả một hệ vận hành: công thức, tiêu chuẩn, nguyên liệu, máy móc, phần mềm quản lý, cách tính phí, cách phân phối lợi nhuận. Người nhận quyền không phải tự phát minh lại mọi thứ từ đầu. Họ chỉ cần bỏ vốn, chọn địa điểm, vận hành cửa hàng và tìm khách.
OpenLedger, nếu đọc dưới góc này, cũng không nhất thiết phải tự xây mọi AI model cho từng ngành. Cái dự án đang cố cung cấp là “hệ vận hành” cho các mô hình AI chuyên biệt: nơi một nhóm có thể gom dữ liệu trong một ngách, dùng hạ tầng để biến dữ liệu đó thành model, cho user hoặc agent gọi model đó, rồi phân phối doanh thu về những người đã góp phần tạo ra nó.
Datanet lúc này không chỉ là kho dữ liệu. Nó giống nguồn nguyên liệu và cộng đồng vận hành của một cửa hàng AI.
Specialized model không chỉ là sản phẩm kỹ thuật. Nó giống món hàng chính mà cửa hàng bán ra.
Proof of Attribution không chỉ là cơ chế ghi công. Nó giống sổ kế toán nội bộ, giúp hệ thống biết ai cung cấp nguyên liệu nào và nguyên liệu đó có thật sự đóng góp vào sản phẩm cuối không.
Còn OpenLedger là mặt bằng, bộ máy thanh toán và lớp tiêu chuẩn chung để các cửa hàng đó có thể mở rộng mà không cần tự xây toàn bộ backend từ đầu.
Nhìn như vậy, OpenLedger thú vị hơn một danh sách feature.
Nó đang thử biến việc tạo model thành một mô hình nhượng quyền kinh tế.
Nhưng franchise có một điểm dễ bị bỏ qua: nó không xóa rủi ro kinh doanh. Nó chỉ chuyển rủi ro đó xuống từng cửa hàng nhỏ hơn.
Đây mới là chỗ tôi thấy OpenLedger đáng suy nghĩ.
Nếu hạ tầng làm việc mở một “cửa hàng AI” dễ hơn, điều đó không có nghĩa mỗi cửa hàng tự nhiên có khách, có biên lợi nhuận, có lý do tồn tại lâu dài. Nó chỉ có nghĩa chi phí khởi tạo giảm xuống. Còn bài toán kinh doanh thật vẫn nằm ở từng Datanet, từng model, từng nhóm vận hành.
Một Datanet nghe rất đẹp khi được gọi là mạng dữ liệu chuyên biệt. Nhưng nếu nhìn lạnh hơn, nó cũng giống một cửa hàng phải tự lo nguồn hàng. Dữ liệu không tự nhiên sạch. Người đóng góp không tự nhiên chất lượng. Việc lọc, cập nhật, kiểm tra, sửa lỗi, giữ cho model còn dùng được đều có chi phí.
Nếu model được gọi đủ nhiều, chi phí đó có thể đáng.
Nếu không, cả Datanet chỉ là một quầy hàng mở ra vì lúc đầu có incentive.
Một specialized model cũng vậy. Từ xa nhìn vào, việc có nhiều model cho nhiều ngách tạo cảm giác hệ sinh thái đang mở rộng. Nhưng ở cấp từng model, câu hỏi rất đời: ai trả tiền để nó sống?
Inference fee có đủ bù chi phí dữ liệu, fine-tune, compute, bảo trì, review và cập nhật không? Hay nó chỉ sống nhờ phần thưởng ban đầu, campaign, narrative, rồi sau đó dần trở thành một cửa hàng vẫn treo biển nhưng không còn khách thật?
Đây là điểm mô hình franchise làm OpenLedger hiện ra rõ hơn.
Nó không chỉ cho thấy khả năng mở rộng.
Nó cho thấy OpenLedger đang đặt một bài toán unit economics lên vai từng đơn vị nhỏ trong hệ sinh thái.
Nếu một cửa hàng AI y tế cần dữ liệu đắt, review đắt, rủi ro sai cao, nhưng inference fee lại bị thị trường ép xuống thấp, cửa hàng đó khó sống. Nếu một model phân tích thị trường on-chain quá dễ mở, ai cũng làm được, nguồn cung phình ra rất nhanh, doanh thu của từng model sẽ bị xé nhỏ. Nếu mọi bên trong chuỗi đều muốn một phần doanh thu, người thực sự vận hành model có thể nhận phần quá mỏng để tiếp tục cải thiện.
Lúc đó vấn đề không phải OpenLedger thiếu tính năng.
Vấn đề là hệ sinh thái có thể có quá nhiều “chi nhánh” không đủ lợi nhuận để trở thành doanh nghiệp thật.
Điều này làm tôi nhìn khác về các công cụ giúp mở model dễ hơn. Bình thường, no-code hoặc hạ tầng fine-tune nhẹ hơn được xem như lợi thế thuần túy. Càng dễ tạo model, hệ sinh thái càng nở nhanh. Đúng, nhưng chỉ đúng nửa đầu.
Nửa sau là: càng dễ mở cửa hàng, càng dễ bão hòa.
Nếu trong một khu phố có một quán bán cùng một món, nó có vị trí. Nếu có năm mươi quán bán gần như cùng một món, đa số sẽ phải giảm giá, làm marketing ồn ào hơn, hoặc sống nhờ khuyến mãi. Trong OpenLedger, tình huống tương tự có thể xảy ra với các model tài chính, trading, research, on-chain analytics. Những ngách hấp dẫn nhất sẽ bị chen vào đầu tiên. Ai cũng nói mình specialized, nhưng nhiều model có thể chỉ khác nhau ở bao bì.
Khi đó routing attention trở thành mặt bằng mới.
Trong franchise truyền thống, cửa hàng nằm ở vị trí đẹp có lợi thế lớn. Trong OpenLedger, model được agent hoặc người dùng gọi nhiều sẽ có lợi thế tương tự. Nếu một agent như OctoClaw phải chọn model để thực hiện workflow, câu hỏi “model nào được gọi” có thể quan trọng không kém câu hỏi “model nào tồn tại”.
Một model tốt nhưng ít được route có thể đói doanh thu.
Một model trung bình nhưng biết tối ưu metadata, incentive hoặc visibility có thể sống lâu hơn mức nó xứng đáng.
Đây là chỗ tôi thấy OpenLedger cần cực kỳ tỉnh.
Nếu dự án chỉ tối ưu cho số lượng cửa hàng AI được mở, nó có thể tạo ra một con phố rất đông trong ngày khai trương. Nhưng sau đó, thứ quyết định chất lượng hệ sinh thái không phải số biển hiệu. Mà là bao nhiêu cửa hàng có khách quay lại, bao nhiêu cửa hàng có biên lợi nhuận đủ sống, bao nhiêu cửa hàng có lý do tồn tại khác với cửa hàng bên cạnh.
Tôi không nghĩ cách giảm rủi ro là kiểm soát chặt mọi thứ từ trên xuống. Làm vậy thì mất tinh thần mở của OpenLedger.
Nhưng cũng không thể chỉ tin rằng thị trường sẽ tự sửa hết trong im lặng.
Điều tôi muốn thấy hơn là OpenLedger đối xử với mỗi Datanet hoặc model như một đơn vị kinh doanh có sức khỏe riêng, không chỉ như một module kỹ thuật. Nó cần những tín hiệu rất thực tế: doanh thu inference có lặp lại không, user có quay lại không, agent có tiếp tục chọn model đó sau khi hết incentive không, chi phí compute và bảo trì có được bù không, dữ liệu mới có thật sự cải thiện output không, hay chỉ đang nuôi một cửa hàng mở ra để nhận thưởng.
Nếu nhìn theo hướng này, Proof of Attribution không chỉ là câu chuyện “ai đóng góp thì được ghi nhận”. Nó còn là sổ kế toán để hỏi một câu khó hơn: contribution này có đang giúp cửa hàng AI đó kiếm tiền bền vững không?
Nếu không, attribution đẹp cũng chưa đủ.
OpenLedger có thể mở rộng rất nhanh nếu mô hình franchise này chạy được. Nhưng chính vì vậy, rủi ro lớn nhất không phải là thiếu người mở cửa hàng.
Rủi ro lớn nhất là quá nhiều người mở cửa hàng mà không ai có business thật.
Một hệ sinh thái như vậy nhìn ngoài sẽ rất sáng. Nhiều Datanet. Nhiều model. Nhiều agent. Nhiều activity. Nhưng nếu từng đơn vị nhỏ bên dưới không sống được bằng doanh thu thật, toàn bộ mạng lưới sẽ phụ thuộc vào incentive để giữ đèn.
Và đó là kiểu tăng trưởng tôi nghĩ OpenLedger phải tránh.
Với tôi, câu hỏi quan trọng nhất khi nhìn OpenLedger qua mô hình nhượng quyền không phải là: dự án có thể mở rộng đến bao nhiêu model?
Câu hỏi là: mỗi “cửa hàng AI” trên OpenLedger có đủ khác biệt, đủ khách hàng, đủ biên lợi nhuận và đủ động lực để sống sau mùa incentive đầu tiên không?
Nếu có, OpenLedger thật sự có thể trở thành một hệ thống nhượng quyền tri thức rất mạnh.
Nếu không, nó vẫn có thể có một con phố rất đông.
Chỉ là sau ánh đèn khai trương, sẽ có rất nhiều cửa hàng AI lặng lẽ đóng cửa từ bên trong.