The conversation around AI agents has reached a level of enthusiasm that outpaces the infrastructure supporting it. Autonomous trading, self-executing contracts, on-chain decision-making these capabilities are real, and in controlled environments they work impressively. But the discussion consistently skips over a foundational question: what happens when the data an agent relies on cannot be trusted?
This is not a hypothetical concern. It is the central vulnerability of every autonomous AI system operating at scale today and it is one that very few projects are addressing at the infrastructure level.
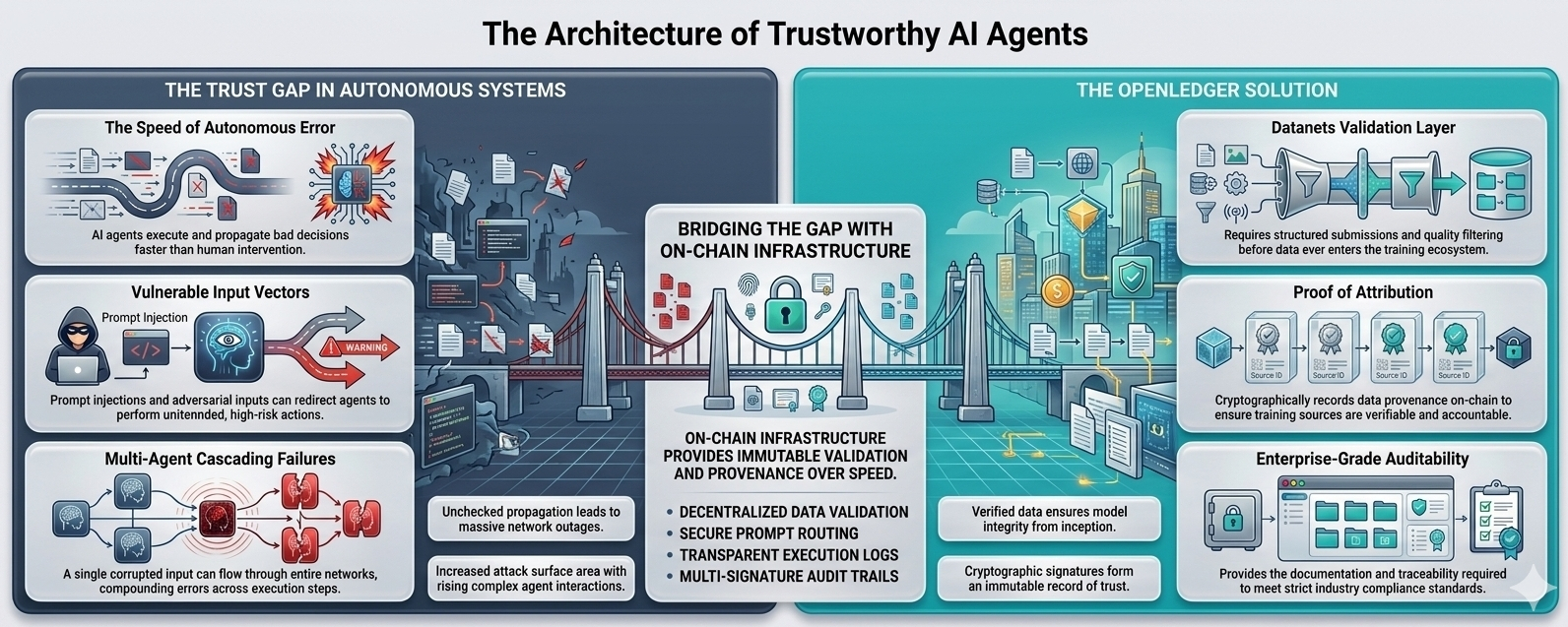
The problem with autonomous systems and unverified data
An AI agent operates by taking inputs, processing them through a model, and executing an action based on the output. The speed and autonomy that make agents valuable also make them dangerous when the input layer is compromised. Unlike a human analyst who might pause on a suspicious data point, an agent executes. The faster the system, the faster a bad decision propagates.
Prompt injection is one well-documented attack vector where malicious instructions are embedded in data that an agent processes, causing it to behave contrary to its intended function. Adversarial inputs are another carefully constructed data designed to push a model toward a specific, unintended output. In financial applications, the consequences of either can be significant. In healthcare or legal AI contexts, they can be severe.
The common thread is that the agent itself is not the weak point. The data pipeline feeding it is.
Where OpenLedger's architecture addresses this
@OpenLedger's design places data validation at the center of the system rather than treating it as a secondary concern. The Datanets contribution layer requires structured submissions with format validation, acceptance rate tracking, and quality filtering before data enters the ecosystem. This is not a cosmetic feature it is a deliberate architectural choice to keep the signal-to-noise ratio of the data layer high.
The Proof of Attribution system adds another dimension to this. Because every data contribution is cryptographically recorded on-chain with contributor identity and submission metadata, the provenance of any piece of data in the system is traceable. When an agent queries a model trained on OpenLedger data, the inputs it is working with carry verifiable history not anonymous scraped content with no accountability attached.
This matters for enterprise deployment in a way that is often underappreciated. Enterprise clients evaluating AI infrastructure are not just asking whether the model is accurate. They are asking whether they can audit what the model was trained on, whether the data sources are accountable, and whether the system can produce documentation that satisfies compliance requirements. A validated, attribution-tracked data layer answers all three questions.
The coordination layer for multi-agent systems
As AI systems move toward networks of interacting agents where one agent's output becomes another agent's input the data integrity problem compounds. A single corrupted input in a multi-agent workflow can cascade through several execution steps before anyone detects the problem, by which point the downstream consequences may already be difficult to reverse.
OpenLedger's on-chain validation architecture creates checkpoints in this flow. Because data provenance is recorded and verifiable at each stage, a multi-agent system built on this infrastructure has the ability to surface anomalies before they propagate rather than discovering them after execution has already occurred.
This is what meaningful defensive coordination looks like in practice. Not a security marketing claim, but a structural property of how the data layer is organized.
The gap between demo performance and production reliability
It is worth being direct about what remains unproven. Validation systems that perform well at small scale do not automatically hold up under the volume and variety of inputs that production environments generate. The quality filtering mechanisms in Datanets need to be robust against sophisticated attempts to game acceptance criteria. The on-chain attribution records need to remain queryable at low latency even as the dataset grows significantly.
These are engineering challenges that require sustained investment and real-world stress testing to resolve. The architecture is sound. The execution track record at scale is still being established.
That is an honest assessment of where the project stands which is further along than most in the space on the question of data integrity, but not yet at the point where the claims can be fully validated against production workloads.
Why this is the right problem to be working on
The AI agent narrative will continue to grow. Automation at scale is genuinely valuable, and the infrastructure supporting it will attract significant capital and development resources over the next several years.
But the projects that build lasting positions in this space will be the ones that recognized early that autonomous execution requires trustworthy inputs and built the data layer accordingly. The speed of an agent is irrelevant if the decisions it makes cannot be trusted. The efficiency of automation is irrelevant if the system cannot be audited.
@OpenLedger is building toward the infrastructure that makes agent-driven AI trustworthy rather than just fast. In the long arc of how this technology develops, that is the more important problem to solve.