The most disturbing thing about OpenLedger is not that it monetizes data.
Everyone monetizes data.
Web2 did it behind closed doors. AI labs do it through opaque training pipelines. Crypto projects do it with prettier dashboards and token incentives. None of that is new.
What makes OPEN different is more subtle: it does not simply extract human knowledge. It tries to formalize the moment when human judgment becomes machine-readable value.
That is the real product.
Not the token. Not the DataNet branding. Not the familiar promise of decentralized AI. The real product is a new kind of accounting system where expertise, credibility, uncertainty, and professional instinct are compressed into measurable units that a protocol can price.
And once something can be measured, it can be governed.
Once it can be governed, it can be taxed.
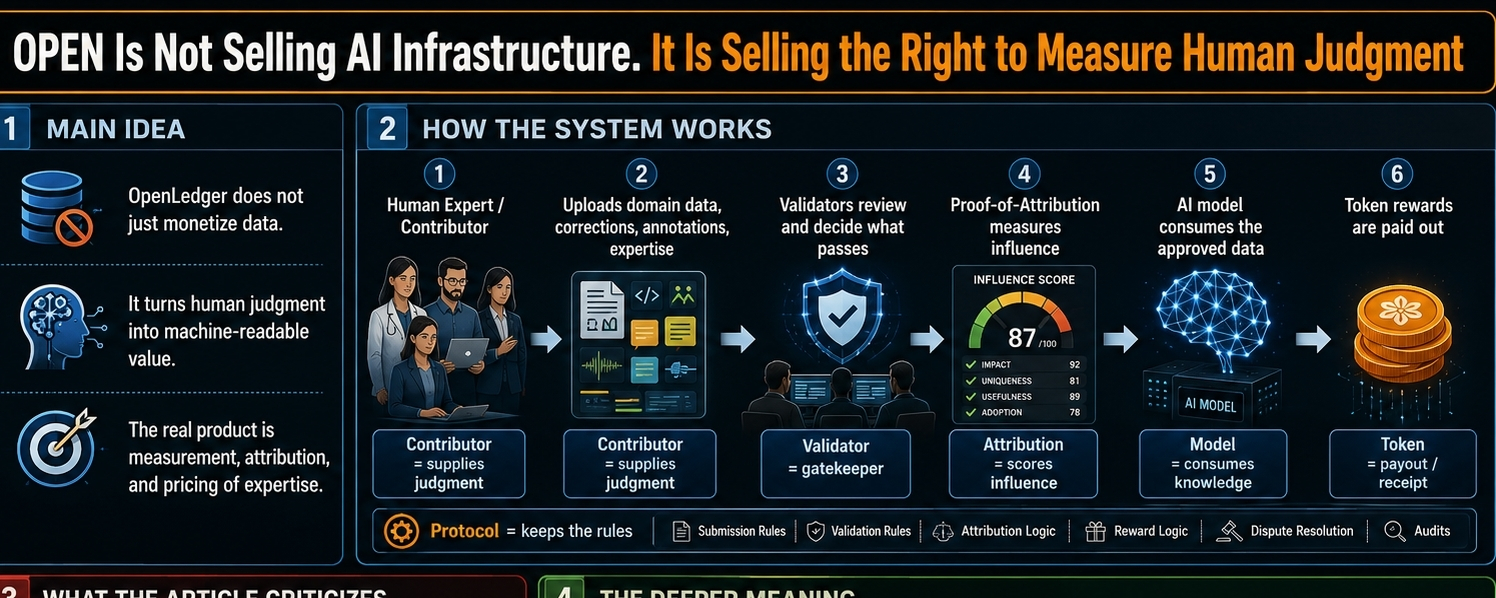
OpenLedger presents itself as an AI data infrastructure project. On the surface, the pitch sounds almost reasonable: contributors upload domain-specific data, validators check its quality, attribution mechanisms track the usefulness of that data, and rewards flow back to the people who helped improve the model.
Clean story. Nice symmetry.
But the deeper you look, the less it feels like infrastructure and the more it feels like a court system for cognition. Every upload is evidence. Every validator review is a ruling. Every attribution score is a sentencing document. The contributor is not simply submitting data. He is submitting his judgment to be inspected, classified, priced, and eventually absorbed.
This is where the tension begins.
Most people still think the AI data problem is about access. Who owns the data? Who contributes it? Who gets paid? But OpenLedger points toward a harsher question: who gets to decide how much human judgment is worth after it enters the machine?
That question is far more dangerous than the usual Web3 talking points.
Because in this system, expertise does not arrive as a whole. It arrives broken into fragments. A code snippet here. A medical annotation there. A legal interpretation somewhere else. A professional correction. A domain-specific example. A judgment call that took years of experience to develop but only seconds to upload.
The protocol does not see the years.
It sees the data point.
That is the cold genius of Proof-of-Attribution. It sounds like a rights mechanism, but it also functions as a machine for shrinking human contribution into percentages. Your experience becomes a traceable influence. Your influence becomes a number. Your number becomes a payout. And because the number looks objective, the payout becomes difficult to challenge.
This is not traditional exploitation. Traditional exploitation often hides the worker. OpenLedger does something more psychologically advanced: it shows the worker his reflection, then tells him exactly how little that reflection is worth.
That precision is what makes it feel modern.
A centralized platform might take your work and erase your name. OpenLedger can record your work, preserve your trace, assign you credit, and still leave you with almost no pricing power. The result is not invisibility. It is documented dependency.
That is a very different kind of trap.
The validator layer makes this even more interesting. Validators are described as guardians of data quality, but economically they behave like border agents. They control what enters the system. They decide what is clean, useful, relevant, or valuable enough to pass. They do not necessarily create the knowledge, but they regulate its admission.
So the contributor learns quickly.
Raw expertise is not enough. You must format it correctly. Package it properly. Align it with validator expectations. Make it legible to the protocol. Make it clean enough for the model. Make it profitable enough for the network.
Over time, the contributor stops asking, “What do I know?”
He starts asking, “What version of what I know will pass?”
That shift matters.
Because the moment expertise is shaped around validation standards, the system is no longer just collecting knowledge. It is training human beings to produce knowledge in the form most convenient for machines.
That may be OpenLedger’s most under-discussed power.
It does not only feed AI. It disciplines the people feeding AI.
DataNet’s vertical structure strengthens this discipline. Medical DataNet, legal DataNet, code DataNet, finance DataNet — all of it sounds like specialization. And yes, specialization has obvious technical benefits. Different domains require different standards. A medical annotation should not be judged like a JavaScript snippet. A legal argument should not be processed like a trading dataset.
But specialization also creates cages.
It turns broad human intelligence into narrow economic lanes. A doctor’s intuition becomes valuable only inside the medical enclosure. A lawyer’s reasoning becomes useful only inside the legal enclosure. A developer’s practical experience becomes priced within a code-specific market.
Human expertise is messy, cross-domain, and deeply contextual.
The protocol prefers it sorted.
That sorting process quietly weakens the contributor. Once your knowledge is locked inside a vertical category, your bargaining power becomes local. You are not selling intelligence. You are supplying a narrow type of input to a narrow type of machine. The system does not need your full mind. It needs the portion that can be tagged, verified, and reused.
This is why OpenLedger feels less like an AI commons and more like a cognitive refinery.
People bring in raw judgment.
The protocol separates it.
Validators filter it.
Models consume it.
Tokens settle it.
And somewhere in that pipeline, the original human texture disappears.
The irony is that contributors may still feel empowered. In fact, that may be the entire psychological design. The system gives them something Web2 rarely gave them: a visible trace. A record. A receipt. A signal that their work did not vanish completely into the black hole of a centralized model.
That visibility can feel like dignity.
But visibility is not ownership.
Being recorded is not the same as having leverage.
A worker can be perfectly visible and still structurally weak. A contributor can have every annotation timestamped and still have no meaningful control over how the value of that annotation is calculated. A wallet can receive rewards while the person behind it slowly loses the ability to negotiate the worth of his own expertise.
This is the emotional core of OPEN.
It does not make people believe they are rich.
It makes them believe they are counted.
And in the AI era, being counted is becoming dangerously addictive.
When models absorb everything, when platforms scrape silently, when creative and professional labor disappears into outputs with no memory of origin, even a tiny on-chain acknowledgment can feel powerful. A contributor may accept poor economics because the alternative feels worse: total erasure.
That is why the system works.
Not because the rewards are always attractive.
But because the receipt feels better than nothing.
From a technical perspective, people will talk about OpenLedger’s architecture, data availability choices, rollup design, attribution logic, and validation network. Those details matter, but they are not the deepest story. The deeper story is that OpenLedger wraps a labor relationship in neutral technical language.
“Proof-of-Attribution” sounds fair.
“Validation” sounds responsible.
“DataNet” sounds collaborative.
“Contributor rewards” sound empowering.
But the combined structure creates a market where human judgment is continuously audited by systems the contributor does not control. This is not merely decentralization. It is bureaucratization through code.
The boss is no longer a person.
The boss is a scoring mechanism.
And that is much harder to argue with.
A human manager can be accused of unfairness. A company can be blamed for exploitation. A platform can be criticized for opacity. But when the protocol tells you your contribution was worth 0.003%, disagreement becomes complicated. The system does not sound cruel. It sounds calculated.
That is the danger of mathematical authority.
It can turn economic weakness into a technical fact.
Still, calling OpenLedger evil would be too simple. In a market full of empty AI tokens, narrative farms, and projects that use decentralization as decoration, OPEN is at least confronting a real problem: AI needs human knowledge, and that knowledge is not free. Someone has to build the rails for sourcing it, verifying it, and rewarding it.
OpenLedger’s uncomfortable honesty is that it treats knowledge as supply.
Not inspiration.
Not creativity.
Not sacred human output.
Supply.
And maybe that is why the project matters. It strips away the comforting language around decentralized AI and shows the transaction underneath. You give the machine judgment. The machine gives you settlement. The protocol keeps the rules.
The bargain is not fake.
It is just unequal.
The market still does not know how to price this. Token volatility reflects that confusion. Investors can price compute narratives. They can price storage narratives. They can price infrastructure narratives. But pricing human cognition as a recurring input market is stranger. It sits somewhere between labor, data, reputation, and intellectual property.
OPEN is trying to make that category tradable.
That is ambitious.
It is also dangerous.
Because once cognition becomes an asset class, the next battle will not be about who contributes. It will be about who controls the measurement layer. The party that defines attribution defines value. The party that defines validation defines quality. The party that defines quality defines access to rewards.
This is where decentralization becomes slippery.
Power may not sit in one company anymore. It may be distributed across validators, token incentives, governance parameters, reputation systems, and model demand. But distributed power is still power. Sometimes it is even harder to resist because there is no single face to confront.
No villain.
No office.
No HR department.
Just a network.
And the network says the math is fair.
That is why OPEN should be watched beyond price action. It may be one of the early examples of a larger shift: the conversion of human expertise into protocol-managed inventory. Not data in the old sense. Not content in the social media sense. But judgment itself — professional, contextual, hard-earned judgment — becoming a structured input for machine intelligence.
This is not the democratization of AI.
It is the supply-chainization of thought.
The contributor becomes a vendor.
The validator becomes customs.
The model becomes the factory.
The token becomes the receipt.
And the protocol becomes the market-maker of human relevance.
In that sense, OPEN is not lying. It is telling the truth more bluntly than most projects dare to. The AI economy does not simply need GPUs and data centers. It needs millions of small human decisions, cleaned and formatted, routed into models, scored for usefulness, and settled at a price low enough for the machine economy to scale.
That is the real infrastructure.
Not servers.
Not rollups.
Not dashboards.
People.
More specifically, people whose judgment can be converted into machine-readable increments.
Maybe future historians will look back at projects like OpenLedger and say this was the moment AI labor stopped being hidden and started becoming financialized. The moment the invisible human layer behind artificial intelligence was brought on-chain — not necessarily to liberate it, but to make it more efficiently measurable.
That is the uncomfortable possibility.
OPEN may not be a scam.
It may be something colder.
A working prototype of the labor market AI actually wants.
One where humans do not disappear from the machine, but also do not control it. One where contributors are credited, but not empowered. One where expertise is visible, but still cheap. One where the system does not steal your knowledge in the dark; it invites you to submit it in daylight, then pays you according to a formula you did not write.
That is why OPEN feels important.
Not because it solves the AI data problem perfectly.
But because it reveals the shape of the next problem.
In the AI age, the most valuable resource may not be data itself. It may be structured human confidence: the tiny professional judgments that tell a model what is correct, useful, safe, relevant, or true.
OpenLedger is building a market around those judgments.
And markets do not merely reward things.
They reshape them.
So the final question is not whether OPEN is good or bad. That is too easy. The real question is whether human expertise can enter a protocol without becoming subordinate to the protocol’s measurement system.
Right now, the answer is not comforting.
Because once your judgment becomes a data point, and that data point becomes an attribution score, and that score becomes a token payout, something irreversible has happened.
Your knowledge has not only been used.
It has been translated into the language of the machine.
And translation always has a cost.
OPEN is that cost made visible.