Ich dachte heute über @OpenLedger aus der entgegengesetzten Richtung nach.
Normalerweise, wenn Leute über AI-Blockchain-Projekte diskutieren, beginnen sie mit der Gelegenheit. Daten werden monetarisierbar. Modelle werden zu Vermögenswerten. Agenten werden zu wirtschaftlichen Akteuren. Liquidität fließt dorthin, wo Wert früher gefangen war. Das ist eine interessante These und Teil des Grundes, warum $OPEN immer wieder in Gesprächen über AI-Infrastruktur auftaucht.
Aber die nützlichere Frage könnte weniger angenehm sein: Was könnte das verlangsamen?
Nicht, weil die Idee schwach ist. Tatsächlich das Gegenteil. Starke Infrastrukturideen scheitern oft oder bewegen sich langsam, wenn sie auf bestehendes Verhalten, Regulierung, Kostenstrukturen und institutionelle Gewohnheiten stoßen. Statt #OpenLedger wie eine fertige Antwort zu behandeln, könnte es besser sein, zu fragen, was richtig laufen muss, bevor es weit verbreitet genutzt wird.
Das Problem vor OpenLedger
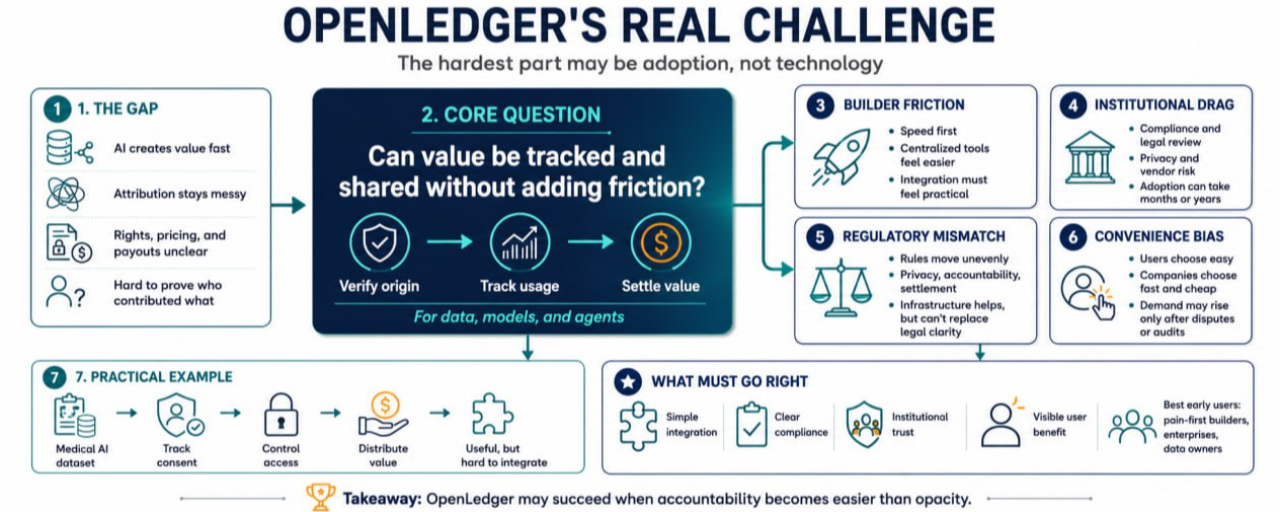
KI breitet sich bereits durch Geschäftsabläufe aus, aber die wirtschaftliche Schicht darum herum ist chaotisch.
Ein Unternehmen könnte Daten von Dritten verwenden, Modelle feinabstimmen, Agenten einsetzen und Entscheidungen automatisieren, ohne einen klaren Weg zu haben, um zu verfolgen, wer was beigetragen hat. Nutzer wissen oft nicht, wie ihre Daten verwendet werden. Entwickler wissen möglicherweise nicht, wie sie KI-Assets bepreisen sollen. Institutionen möchten möglicherweise bessere Prüfpfade, zögern jedoch, sensible Operationen offenzulegen. Regulierungsbehörden versuchen immer noch zu verstehen, wo die Verantwortung beginnt und endet.
Das schafft eine seltsame Lücke. KI kann schnell Wert schaffen, aber nachzuweisen, woher dieser Wert kommt, ist viel schwieriger.
OpenLedgers Fokus auf die Freischaltung von Liquidität zur Monetarisierung von Daten, Modellen und Agenten spricht direkt diese Lücke an. Dennoch garantiert das Vorhandensein des richtigen Problems keine einfache Akzeptanz.
Risiko Eins: Entwickler könnten zusätzliche Reibung vermeiden
Entwickler kümmern sich normalerweise zuerst um Geschwindigkeit.
Wenn ein Entwickler eine KI-App mit einer zentralisierten API, einer einfachen Datenbank und einem Zahlungsanbieter veröffentlichen kann, könnte es ihnen zunächst egal sein, wie tiefere Zurechnung oder Abwicklung aussieht. Teams in der Frühphase kämpfen oft um Nutzer, nicht um die Gestaltung perfekter wirtschaftlicher Infrastrukturen.
Dies ist ein echtes Adoptionsrisiko für OpenLedger. Selbst wenn überprüfbare Datenströme und Monetarisierungswege nützlich sind, müssen Entwickler sie als praktisch empfinden. Wenn die Integration schwerfällig erscheint, die Dokumentation unklar ist oder die Vorteile zu spät kommen, könnten viele Teams die Nutzung aufschieben.
Die Herausforderung ist nicht nur technisch. Sie ist auch verhaltensbedingt. Menschen übernehmen Infrastruktur, wenn sie den bereits empfundenen Schmerz lindert.
Risiko Zwei: Institutionen bewegen sich langsam
Institutionen benötigen möglicherweise eine OpenLedger-ähnliche Infrastruktur, sind jedoch selten schnelle Anwender.
Banken, Versicherungen, Gesundheitsunternehmen, Universitäten, Logistikunternehmen und öffentliche Stellen kümmern sich um Compliance, Beschaffung, rechtliche Überprüfung, Lieferantenrisiko, Datenschutz und interne Genehmigungen. Selbst wenn die Vorteile offensichtlich sind, kann die Implementierung Monate oder Jahre dauern.
Für Institutionen ist das Versprechen, KI-Datenströme zu monetarisieren, nicht genug. Sie benötigen das Vertrauen, dass das System die Prüfstandards, Sicherheitsanforderungen, Berichtspflichten und regulatorischen Erwartungen erfüllen kann.
Hier muss @OpenLedger mehr als ein interessantes Netzwerk sein. Es muss auf die bestmögliche Weise langweilig werden: zuverlässig, verständlich und leicht zu rechtfertigen innerhalb eines Risikoausschusses.
Risiko Drei: Regulierungsbehörden könnten nicht synchron handeln
Die KI-Regulierung ist immer noch ungleichmäßig.
Eine Gerichtsbarkeit könnte sich auf den Datenschutz konzentrieren. Eine andere könnte sich auf die Modellverantwortung konzentrieren. Eine weitere könnte sich um die finanzielle Abrechnung, den Verbraucherschutz oder die Datenlokalisierung kümmern. Für ein System, das sich mit KI-Assets, Datenrechten, Agentenaktivitäten und Wertverteilung befasst, schafft dies ein komplexes Umfeld.
OpenLedger könnte helfen, indem es die Ströme transparenter und nachvollziehbarer macht. Aber Regulierungsbehörden könnten sich immer noch darüber uneinig sein, was als akzeptabler Nachweis, rechtmäßige Datennutzung oder faire Vergütung zählt.
Diese Unsicherheit kann die Akzeptanz verlangsamen. Institutionen könnten auf klarere Regeln warten, bevor sie sich tief engagieren. Entwickler könnten regulierte Anwendungsfälle meiden. Nutzer könnten skeptisch bleiben, wenn sie nicht verstehen, wie ihre Rechte geschützt sind.
Infrastruktur kann Compliance unterstützen, kann jedoch rechtliche Klarheit nicht ersetzen.
Ein praktisches Beispiel: Ein medizinisches KI-Dataset
Stell dir vor, ein Unternehmen möchte ein KI-Tool entwickeln, das Kliniken hilft, Patientenaufnahmeformulare zu analysieren.
Die Daten haben Wert. Das Modell hat Wert. Der Agent, der Fälle weiterleitet, hat Wert. Aber die Risiken sind ernst. Die Privatsphäre der Patienten muss geschützt werden. Die Zustimmung muss klar sein. Der Zugang muss kontrolliert werden. Wenn das Tool die Ergebnisse verbessert oder die Kosten senkt, gibt es möglicherweise Fragen darüber, wer finanziell profitiert.
Eine OpenLedger-ähnliche Infrastruktur könnte helfen, Berechtigungen, Nutzung und Wertverteilung zu verfolgen. Das wäre für Entwickler, Institutionen, Nutzer und Regulierungsbehörden von Bedeutung.
Aber die Akzeptanz wäre trotzdem schwierig. Gesundheitsorganisationen könnten sich um Compliance-Risiken sorgen. Anwälte könnten in Frage stellen, ob das Abrechnungsmodell zu bestehenden Regeln passt. Patienten könnten vage Versprechen zur Datenmonetarisierung nicht vertrauen. Die Integration mit alten Systemen könnte teuer sein.
Die Wert proposition ist also real, aber der Weg ist nicht automatisch.
Risiko Vier: Der Markt könnte Bequemlichkeit bevorzugen
Das größte Risiko könnte sein, dass viele Menschen sagen, sie wollen Transparenz, aber Bequemlichkeit wählen.
Nutzer klicken durch Bedingungen, die sie nicht lesen. Unternehmen wählen Werkzeuge, die günstiger und schneller sind. Entwickler optimieren für die Geschwindigkeit des Launches. Institutionen verschieben oft Infrastrukturänderungen, bis das Risiko unvermeidlich wird.
Das bedeutet nicht, dass OpenLedger nicht funktionieren kann. Es bedeutet, dass die Nachfrage möglicherweise allmählich wächst, insbesondere nachdem Streitigkeiten, Prüfungen oder regulatorischer Druck undurchsichtige KI-Systeme kostspieliger machen.
Anders ausgedrückt könnte die Notwendigkeit für OpenLedger nur dann offensichtlich werden, wenn die derzeitige Art, KI zu bauen, unter dem Druck der realen Welt zu brechen beginnt.
Wichtige Erkenntnis
Die wahrscheinlichsten frühen Nutzer von OpenLedger könnten Entwickler sein, die bereits den Schmerz der KI-Zurechnung, Datenmonetarisierung, Agentenabwicklung oder institutionellen Compliance verspüren. Es könnte auch für Datenbesitzer von Interesse sein, die eine Vergütung wünschen, Unternehmen, die Nachvollziehbarkeit benötigen, und Teams, die KI-Workflows entwickeln, wo Vertrauen wichtiger ist als Geschwindigkeit allein.
Es könnte funktionieren, wenn #OpenLedger die Überprüfung und Wertverteilung einfacher erscheinen lässt als das Management privater Vereinbarungen, manueller Prüfungen und unklarer Eigentumsverhältnisse. Es könnte scheitern oder sich langsam entwickeln, wenn die Integration zu schwierig ist, die Vorschriften verwirrend bleiben oder Nutzer und Unternehmen weiterhin Bequemlichkeit über Verantwortlichkeit wählen.
Deshalb sehe ich $OPEN weniger als eine einfache KI-Erzählung und mehr als einen Test für das Marktverhalten. Wollen die Leute nur intelligentere KI, oder wollen sie auch KI-Systeme, die nachweisen können, wie Wert geschaffen und geteilt wird?
Dies ist keine Finanzberatung.
Was denkst du, ist das größte Hindernis für OpenLedger: Regulierung, Akzeptanz durch Entwickler, Vertrauen der Institutionen oder Nutzerbewusstsein?