Ich hatte kürzlich eine kleine Erkenntnis, während ich ein KI-Tool benutzt habe.
Die Ausgabe fühlte sich nützlich an. Das Modell schien fähig zu sein. Der Workflow war geschmeidig. Aber nach ein paar Minuten fragte ich mich: Wem gehört eigentlich der Wert, der hier geschaffen wird?
Nicht die Benutzeroberfläche. Nicht der Abonnementplan. Ich meine den tieferen Wert. Die Daten hinter dem Modell, die Feinabstimmungsarbeit, die Agentenlogik, das Feedback von Nutzern und die zukünftigen Einnahmen, die daraus entstehen könnten.
Diese Frage ist leicht zu ignorieren, wenn KI wie ein Produkt wirkt. Es wird schwieriger zu ignorieren, wenn KI anfängt, wie eine Wirtschaft auszusehen.
Das Eigentumsproblem vor OpenLedger
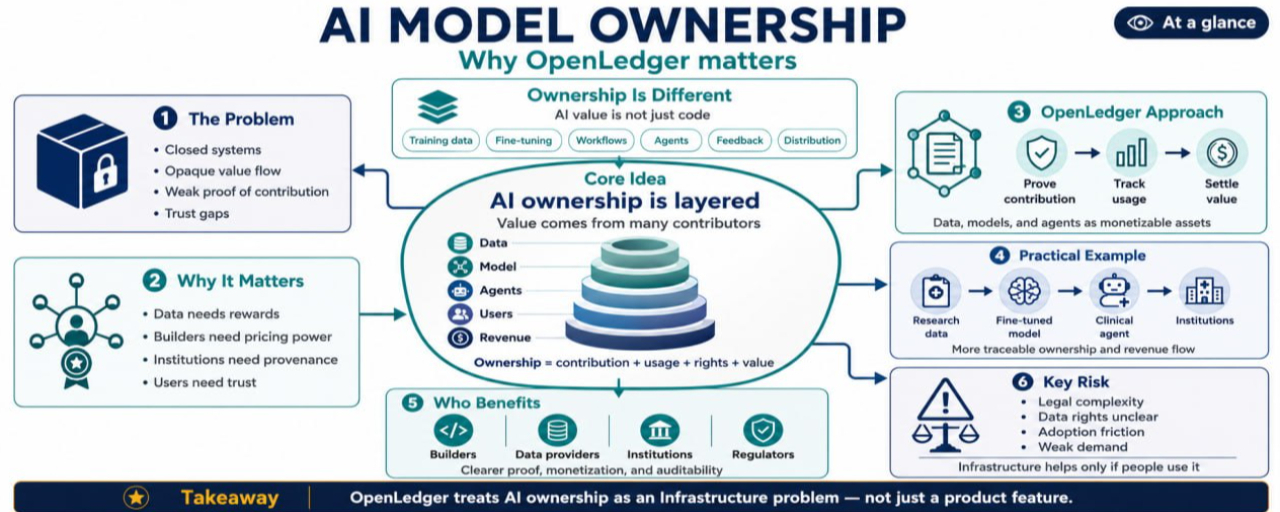
Die meisten KI heute wird durch geschlossene Systeme erfahren.
Ein Benutzer tippt, das Modell antwortet, und die Plattform kontrolliert die Umgebung. Das ist einfach für Verbraucher, aber es schafft ein chaotisches Eigentumsproblem für alle anderen.
Builder können Modelle feinabstimmen, haben aber Schwierigkeiten nachzuweisen, wie viel Wert ihre Arbeit hinzufügt. Datenanbieter können nützliche Datensätze bereitstellen, erhalten aber wenig fortlaufenden Nutzen. Benutzer können wertvolles Feedback generieren, nehmen jedoch selten an der Wirtschaft teil. Institutionen können KI-Tools übernehmen, während sie auf private Aufzeichnungen angewiesen sind, die sie nicht vollständig überprüfen können. Regulierungsbehörden können Fragen stellen, die geschlossene Plattformen nicht klar beantworten können.
Das ist nicht nur ein philosophisches Problem. Besitz beeinflusst Anreize.
Wenn Datenbesitzer nicht belohnt werden, könnten sie vermeiden, qualitativ hochwertige Daten zu teilen. Wenn Modellbauer ihren Beitrag nicht nachweisen können, könnten sie ihre Preismacht verlieren. Wenn Institutionen die Herkunft nicht überprüfen können, könnten sie zögern, KI in sensiblen Workflows einzusetzen. Wenn Benutzer sich ausgenutzt fühlen, bricht das Vertrauen zusammen.
Der Besitz von KI-Modellen geht nicht nur darum, wer eine Datei hält. Es geht darum, wer Beitrag, Nutzung, Rechte und Wert nachweisen kann.
Warum KI-Modelle anders sind als normale Software
Traditionäre Software hat normalerweise eine klarere Eigentumsspuren.
Ein Unternehmen schreibt Code, lizenziert ihn, verkauft den Zugang und wartet das Produkt. KI-Modelle sind komplizierter, weil deren Wert aus vielen Schichten kommt.
Trainingsdaten sind wichtig. Feinabstimmungen sind wichtig. Eingaben und Workflows sind wichtig. Agentenintegrationen sind wichtig. Menschliches Feedback ist wichtig. Verteilung ist wichtig. Selbst Nutzungsmuster können das Produkt im Laufe der Zeit verbessern.
Wenn ein Modell wertvoll wird, wird die Frage schwierig: Kam der Wert vom ursprünglichen Modell, dem Datensatz, der Feinabstimmung, dem Agentenwrapper, den Benutzern oder der Bereitstellungsumgebung?
Normalerweise ist die Antwort alle von ihnen.
Deshalb kann zentralisierter Besitz unvollständig erscheinen. Es mag effizient sein, aber es verbirgt oft die Beitragskarte. Für kleine Tools mag das akzeptabel sein. Für Unternehmens-KI, regulierte Workflows und agentenbasierte Ökonomien wird es schwieriger zu verteidigen.
Wo OpenLedger wichtig sein könnte
Hier wird @OpenLedger relevant.
OpenLedger baut um die Idee herum, dass Daten, Modelle und Agenten monetisierbare KI-Assets sein sollten. Für mich ist der entscheidende Punkt nicht einfach, einen weiteren Marktplatz zu schaffen. Es geht darum, eine Infrastruktur zu schaffen, in der Eigentum und Nutzung transparenter dargestellt werden können.
Wenn ein Modell verwendet wird, sollte diese Nutzung nachverfolgbar sein. Wenn Daten Wert beitragen, sollte dieser Beitrag leichter erkennbar sein. Wenn ein Agent Einnahmen generiert, sollte der Wertfluss nicht vollständig von privaten Tabellenkalkulationen oder informellen Vereinbarungen abhängen.
$OPEN fügt sich natürlich in dieses Gespräch als Teil der wirtschaftlichen Schicht des Netzwerks ein, aber das größere Problem ist die Koordination. Der Besitz von KI benötigt Schienen, die viele Teilnehmer unterstützen können, ohne dass jeder einem zentralen Betreiber vertrauen muss.
Für Builder könnte das stärkeren Nachweis des Beitrags bedeuten. Für Datenanbieter könnte es bessere Monetarisierung bedeuten. Für Institutionen könnte es sauberere Prüfpfade bedeuten. Für Regulierungsbehörden könnte es mehr sichtbare Verantwortlichkeit schaffen.
Ein praktisches Beispiel
Stell dir ein medizinisches Forschungsmodell vor, das von mehreren Health-Tech-Startups verwendet wird.
Eine Gruppe trägt anonymisierte Forschungsdaten bei. Ein anderes Team optimiert das Modell für die Überprüfung klinischer Literatur. Ein dritter Builder wickelt es in einen Agenten, der Forschern hilft, Muster in klinischen Studien zu identifizieren. Institutionen nutzen den Agenten über eine kontrollierte Schnittstelle.
In einem geschlossenen Setup hängt die Umsatzbeteiligung von Verträgen, Vertrauen und interner Berichterstattung ab. Der Datenanbieter weiß möglicherweise nicht, wie oft sein Beitrag verwendet wurde. Das Feinabstimmungsteam hat möglicherweise Schwierigkeiten, seine Auswirkungen nachzuweisen. Die Institution möchte möglicherweise klarere Beweise dafür, dass die Datenquellen des Modells konform sind. Regulierungsbehörden könnten fragen, wie mit sensiblen Informationen umgegangen wurde.
Mit einer Infrastruktur im OpenLedger-Stil könnte jede Schicht mehr wie ein nachverfolgbares Asset behandelt werden. Der Datensatz, das Modell und der Agent müssten weiterhin rechtliche Vereinbarungen und Datenschutzmaßnahmen haben, aber Nutzung und Abrechnung könnten leichter zu überprüfen sein.
Das löst zwar nicht magisch die Compliance im Gesundheitswesen, könnte aber die Unklarheit über Eigentum und Wertverteilung verringern.
Die Schicht des menschlichen Verhaltens
Die Leute gehen oft davon aus, dass die Einführung von Technologie auf Leistung basiert.
In Wirklichkeit hängt die Einführung oft von Vertrauen und Anreizen ab.
Ein Datenbesitzer könnte fragen: "Werde ich fair bezahlt?"
Ein Builder könnte fragen: "Kann ich beweisen, dass mein Modell verwendet wird?"
Eine Institution könnte fragen: "Kann ich dieses System der Compliance erklären?"
Ein Regulierer könnte fragen: "Wer ist verantwortlich, wenn etwas schiefgeht?"
Ein Benutzer könnte fragen: "Hilf ich, etwas zu trainieren, ohne es zu wissen?"
Die Gelegenheit von OpenLedger liegt in diesen Fragen.
Wenn der Besitz von KI klarer wird, könnten mehr Menschen bereit sein, teilzunehmen. Aber wenn der Besitz vage bleibt, könnten viele wertvolle Mitwirkende an der Seitenlinie bleiben.
Das Risiko: Eigentum ist schwer zu standardisieren
Das größte Risiko besteht darin, dass der Besitz von KI-Modellen zu komplex für einfache Infrastrukturen sein könnte.
Die Rechtssysteme variieren von Land zu Land. Datenrechte sind nicht immer klar. Einige Datensätze können nicht frei monetarisiert werden. Einige Modelle basieren auf unklaren Quellen. Institutionen benötigen möglicherweise private Umgebungen. Regulierungsbehörden könnten langsam agieren oder sich uneinig sein.
Es gibt auch ein Produkt-Risiko. Wenn Builder die Werkzeuge schwierig finden, könnten sie schnellere zentrale Plattformen wählen. Wenn Benutzer keine praktischen Vorteile sehen, werden sie sich nicht um Eigentumsunterlagen kümmern. Wenn Datenanbieter keinen bedeutenden Wert verdienen, könnte die Teilnahme flach bleiben.
OpenLedger kann Schienen bereitstellen, aber der Markt muss sie weiterhin ehrlich nutzen.
Fundierte Erkenntnis
Die Menschen, die am wahrscheinlichsten OpenLedger nutzen, sind Builder, die KI-Modelle und Agenten erstellen, Datenbesitzer, die nach besserer Monetarisierung suchen, und Institutionen, die vor der Skalierung von KI klareren Besitz und Prüfbarkeit benötigen.
Es könnte funktionieren, weil der Wert von KI zu vielschichtig für alte Eigentumsmodelle wird.
Es könnte scheitern, wenn rechtliche Unsicherheit, schwache Nachfrage oder schlechte Benutzererfahrung die Mitwirkenden in geschlossenen Systemen halten.
Für mich ist #OpenLedger interessant, weil es den Besitz von KI als ein Infrastrukturproblem behandelt, nicht nur als eine Markenbehauptung.
Keine finanzielle Beratung.
Wer sollte deiner Meinung nach mehr Wert in KI erfassen: Modellbauer, Datenanbieter, Benutzer oder Agentenentwickler?