Imagine asking an AI a question and knowing that every useful answer automatically rewards the people whose data helped create it.
That idea sounds familiar because we have already seen a version of it before. Every time a song is streamed, a royalty system works quietly in the background, tracking usage and distributing value to the artists, writers, and rights holders who made the music possible. The listener rarely thinks about it, but the infrastructure exists to connect contribution with compensation.
What struck me when looking at @OpenLedger is that it is applying a similar idea to one of the biggest unanswered questions in AI: if data is the fuel powering artificial intelligence, why aren't the people providing that data rewarded when value is created?
This question is becoming more important as AI adoption accelerates. Models are becoming larger, more capable, and more commercially valuable. At the same time, the demand for high-quality data continues to grow. Every specialized dataset, every expert contribution, and every verified piece of information adds texture to the intelligence these systems can deliver.
Yet the economics remain surprisingly one-sided.
Most contributors provide data once and never participate in the value generated afterward. The model improves. The application grows. Revenue flows to platforms and developers. Meanwhile, the people whose knowledge helped create those outcomes often disappear from the economic picture entirely.
OpenLedger was built around the idea that this structure is unsustainable.
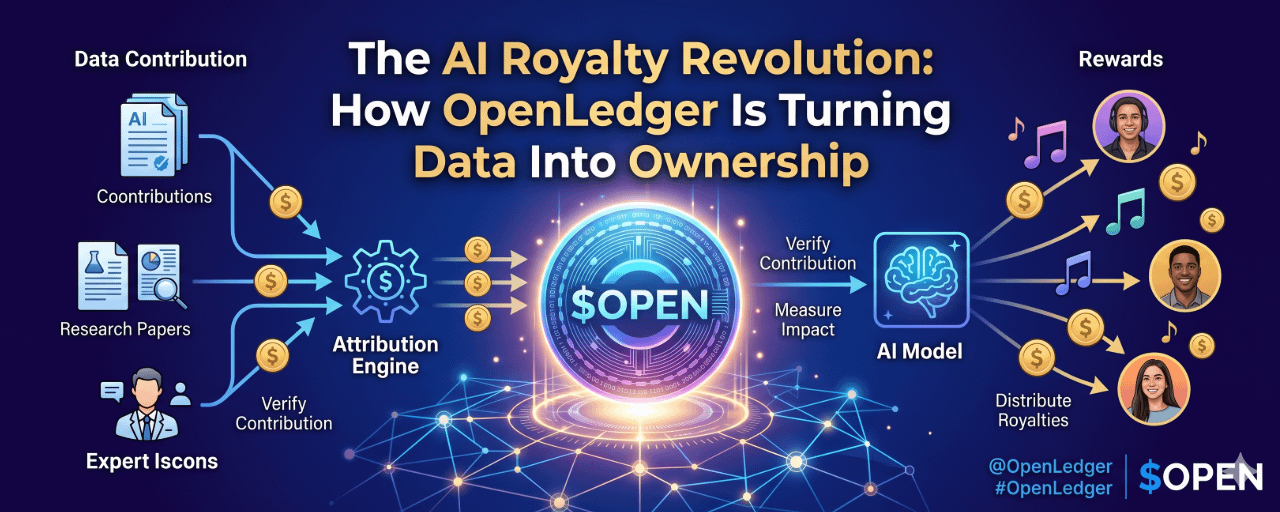
Its core thesis is simple: AI should not only consume data. It should recognize where that data came from, measure its contribution, and reward the people who created it.
That sounds straightforward on the surface.
Underneath, it addresses one of the most difficult infrastructure problems in artificial intelligence.
The challenge is attribution.
When an AI model produces an answer, that output is rarely connected to a single source. Instead, it reflects patterns learned from thousands or millions of data points. Some data contributes directly. Some shapes context. Some improves accuracy in subtle ways that become visible only after deployment.
Because of this complexity, most AI systems operate as black boxes when it comes to contribution tracking. We know valuable data went in. We see valuable outputs come out. What happens in between remains largely invisible.
OpenLedger's Proof of Attribution framework is designed to solve exactly that problem.
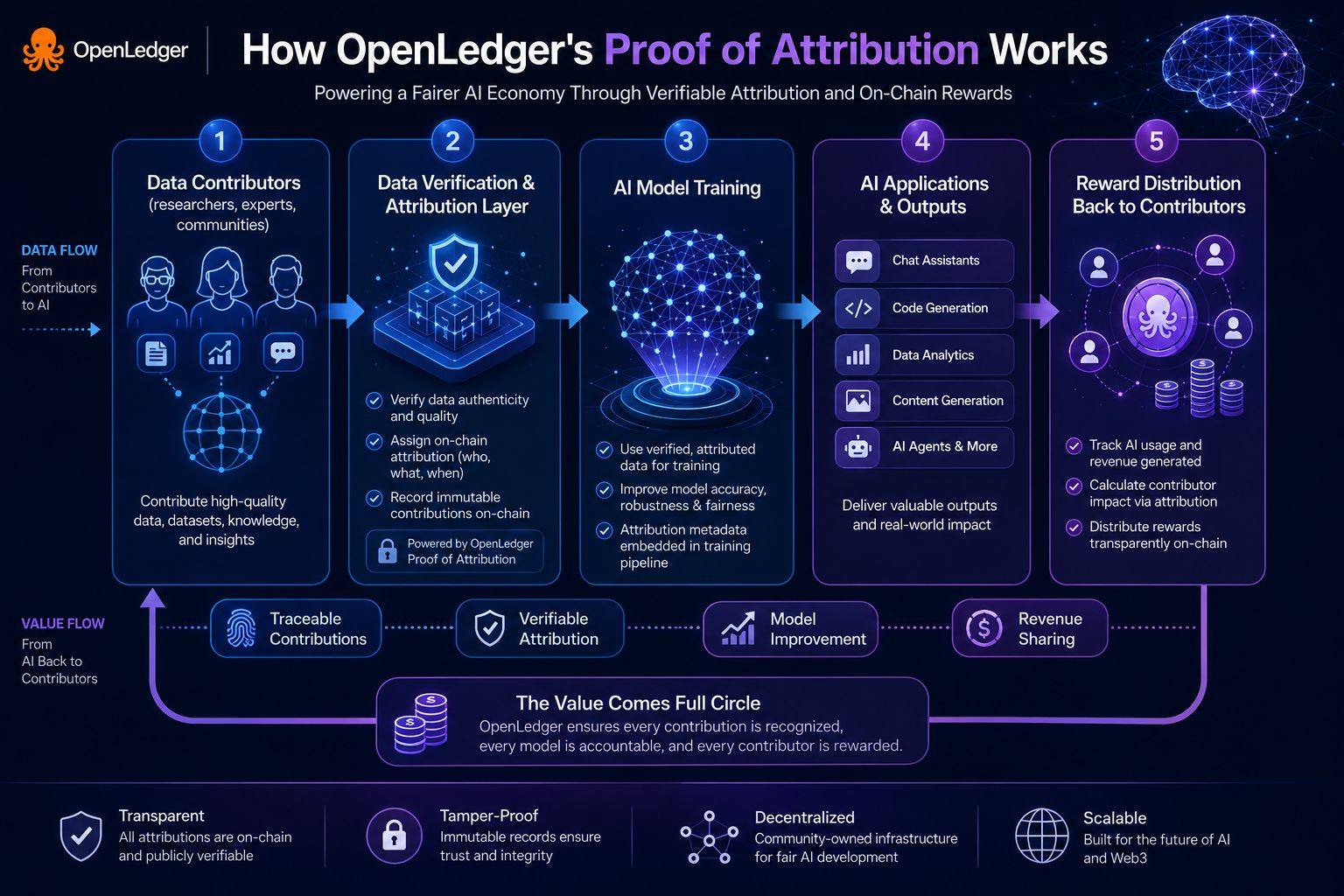
Rather than treating attribution as an afterthought, OpenLedger makes it part of the infrastructure layer. The goal is to create verifiable records showing how data contributes to model performance and how that contribution should be rewarded.
The significance of this becomes clearer when viewed through the lens of royalties.
In music, royalties create an incentive for creators to continue producing valuable work. The better the music performs, the more creators can benefit.
OpenLedger extends that logic to AI.
If a contributor provides valuable data that improves an AI model, and that model generates ongoing value, the contributor can participate in that value creation rather than being limited to a one-time transaction.
That changes the relationship between data and AI entirely.
Data stops being something that is simply extracted.
It becomes something that can generate ongoing economic participation.
Understanding that helps explain why OpenLedger talks so much about building a data economy rather than simply building AI infrastructure.
The network is not just trying to make models smarter. It is trying to create a system where intelligence itself has traceable economic origins.
That distinction matters.
Today, many AI companies compete for access to better datasets. High-quality data is increasingly scarce, especially in specialized domains like healthcare, finance, legal research, and scientific knowledge. As competition increases, the value of trusted and verifiable data rises alongside it.
OpenLedger's model creates an incentive structure designed for that future.
Contributors are motivated to provide higher-quality information because attribution creates the possibility of future rewards. Developers gain access to transparent data sources. Applications benefit from stronger trust and accountability. The network itself becomes stronger as more participants contribute meaningful information.
Meanwhile, every successful AI output strengthens the economic loop connecting contributors and builders.
That creates a very different dynamic from the current AI landscape.
Most AI ecosystems focus primarily on model ownership.
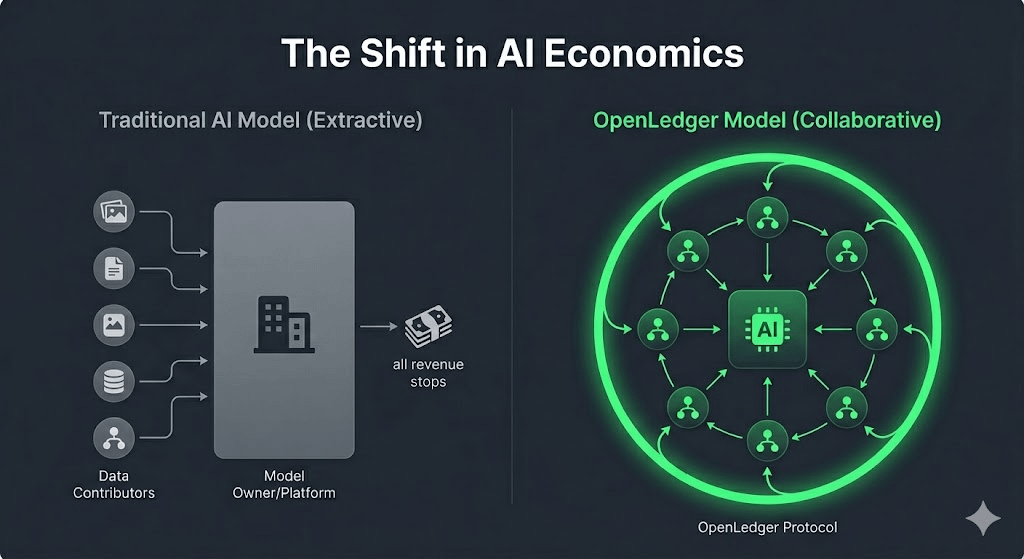
OpenLedger focuses on contribution ownership.
Most discussions center on who built the model.
OpenLedger asks who helped make the model intelligent in the first place.
That shift may sound subtle, but it has major implications.
If attribution becomes reliable, entirely new categories of AI participation become possible. Researchers could monetize specialized knowledge. Communities could earn from collective expertise. Data providers could become long-term stakeholders rather than temporary suppliers.
In other words, the economic foundation of AI starts looking less like extraction and more like collaboration.
Of course, significant challenges remain.
Attribution is difficult. Contributions overlap. Determining fair reward distribution will never be perfectly straightforward. A single AI output may depend on countless contributors whose influence varies in ways that are difficult to measure.
There is also the challenge of scale. Any attribution system must operate efficiently enough to support growing AI ecosystems while remaining transparent and trustworthy.
OpenLedger does not eliminate these challenges.
What it does is acknowledge them directly and build infrastructure specifically designed to address them.
That alone makes it different from many projects discussing AI ownership at a conceptual level without tackling the mechanics required to make it work.
What makes OpenLedger particularly relevant right now is that the broader AI industry appears to be moving toward the same conclusion.
Questions around copyright, licensing, provenance, and data ownership are becoming impossible to ignore. Regulators are paying attention. Enterprises increasingly want transparency. Contributors are beginning to ask how their knowledge is being used.
The direction of travel seems clear.
As AI becomes more valuable, the demand for attribution becomes stronger.
As attribution becomes stronger, contribution becomes measurable.
And once contribution becomes measurable, compensation becomes possible.
That is the future OpenLedger is trying to build.
Not simply a network for AI development, but an economic layer where intelligence has traceable origins and contributors can participate in the value they help create.
The most important AI infrastructure of the next decade may not be the model that generates the answer.
It may be the system that knows exactly who deserves credit for it.
@OpenLedger $OPEN #OpenLedger