
我以前在一家咨询公司做过两年行业研报。那时候每天的工作,就是把海量原始数据整理成结构化内容,再做成图表、逻辑框架和结论。很多时候,一个行业几十页的研究报告,背后可能是连续几周的信息筛选和交叉验证。
最后,这些研报会被卖给大客户,变成真正的商业价值。但说实话,那时候我心里一直有种很强的不平衡感。
因为这些内容后面产生的所有价值,基本都和我没关系了。我拿到的只有固定工资。
至于报告后来被谁使用、赚了多少钱、影响了哪些决策,我完全无法参与。
我的专业知识,在交付那一刻,其实就已经被一次性买断了。
以前我觉得这只是传统行业的问题。
后来 AI 出来之后,我才发现,这种结构性失衡不仅没有缓解,反而被放大了。
现在的大模型,本质上也在做类似的事。
平台不断吸收我们的数据、经验、表达习惯和专业知识,把它们变成模型能力,再通过 API、订阅和推理服务不断变现。
但真正提供“燃料”的人,往往什么都拿不到。
很多时候,你甚至不知道自己的内容有没有被训练过。
更别说参与后续收益分配。
直到后来我开始研究 @OpenLedger 、我才第一次感觉,有人开始认真解决这个问题了。
它最吸引我的地方,不是单纯讲 AI,而是在重新定义 AI 时代的价值分配。
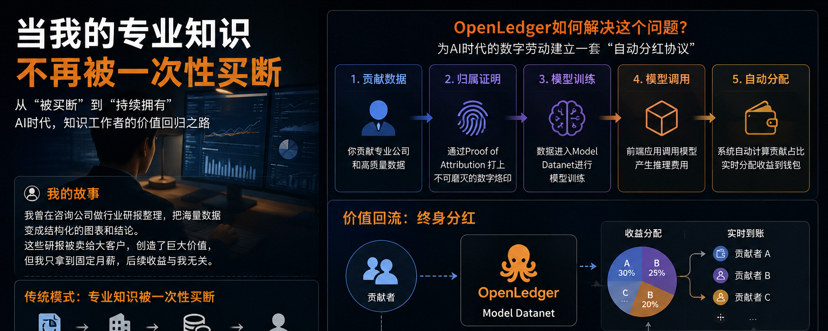
#OpenLedger 想做的,其实是一套属于数字劳动者的自动分红系统。
在它的 Model Datanet 体系里,你贡献的数据不再是无主资产,而是带有明确归属和贡献权重的智能资产。
谁提供了内容、
谁参与了训练、谁对结果贡献更大,系统都会记录。
白皮书里提到的 Proof of Attribution,本质上就是在给每一份贡献做链上归因。
一旦基于这些数据训练出来的模型被调用、被收费、被商业化,系统就会自动计算贡献比例,再把对应收益分配给贡献者。
这和传统平台最大的区别就在于:
以前的数据上传,是一次性交付。
而这里更像持续获得版税。
你的知识不再是卖断,而是开始拥有复利。
我觉得很多人还没意识到这件事真正可怕的地方。
因为过去互联网最核心的问题之一,就是创作者和平台之间的利益极度不对称。
平台拥有流量、拥有模型、拥有分发,
而个体只能不断贡献内容。
但如果未来 AI 的训练、推理和收益分配,真的开始走向链上透明化,那整个生产关系都会被重构。
尤其是 ICLR 2024 提到的 DataInf 算法出来之后,大规模归因计算第一次开始具备现实落地可能。
再结合 $OPEN 的结算层,至少现在终于有人在尝试把“谁创造价值,谁获得收益”这件事真正做出来。

所以我买这个币从来不只是因为 AI 热点。
而是因为我太清楚,被买断是什么感觉。
当一个知识工作者辛苦积累的经验,只能换一次工资,而无法享受长期收益时,这本身就是旧时代生产关系的问题。
而 OpenLedger 让我第一次觉得,AI 时代或许真的会出现另一种可能。
未来真正值钱的,
未必只是模型。
而是谁拥有数据归属权,
谁拥有贡献证明,
谁能持续获得推理收益。
很多人现在还在盯着几根 K 线涨跌。
但真正决定下一轮价值分配的,可能是你有没有参与到新的规则里。