The assumption built into most AI development today is that more data is better data. Larger training sets produce more capable models. Scale is the primary competitive advantage. This assumption has driven the last decade of AI progress and it is now running into its limits.
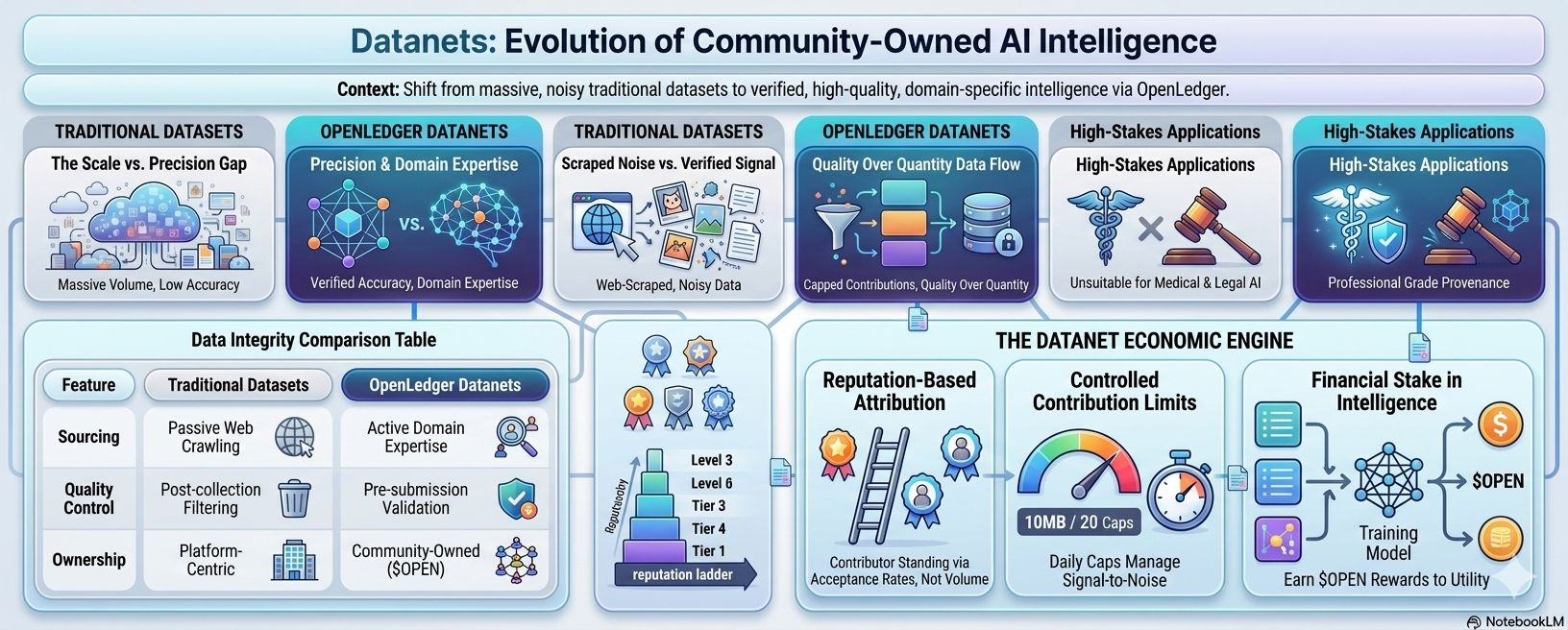
As AI applications move from general consumer tools into specialized professional domains, the relevant question is no longer how much data a model was trained on. It is whether the data was accurate, verified, domain-appropriate, and sourced with accountability. On all four criteria, the traditional large-scale dataset approach performs poorly. @OpenLedger's Datanets architecture is a direct response to this gap.
What traditional datasets actually look like
The datasets behind most major AI models were assembled through large-scale web crawling collecting text, code, and other content from across the internet with varying degrees of filtering applied afterward. The process is efficient and produces enormous volume. It also produces significant noise: outdated information, factual errors, duplicated content, and material scraped without the knowledge or consent of its creators.
For a general-purpose language model, this is a workable foundation. The scale compensates for the noise to a meaningful degree, and the applications are broad enough that precision in any single domain is not critical.
For a healthcare AI that clinicians will rely on for diagnostic support, or a legal AI that practitioners will use to research case precedents, or a financial AI managing institutional capital the noise is not workable. The errors are not acceptable. The lack of provenance documentation is a compliance problem. General datasets are not fit for these purposes, and no amount of fine-tuning fully corrects for a flawed data foundation.
The Datanets model and what it changes
OpenLedger's Datanets are domain-specific data communities structured ecosystems where contributors submit data relevant to a particular field, submissions go through format validation and quality filtering, and accepted contributions are recorded on-chain with full provenance metadata.
Several features of this design are worth examining carefully.
The contribution limits 10MB per day, 20 files per submission are not arbitrary restrictions. They are a signal-to-noise management mechanism. Unlimited contribution volume in an open system inevitably degrades quality as the incentive to submit anything outweighs the incentive to submit something good. Capping volume forces contributors to be selective about what they submit, which concentrates the incentive on quality rather than quantity.
The acceptance rate metric reinforces this. A contributor's standing in a Datanet is determined not by how much they submit but by how consistently their submissions are accepted. This creates a reputational stake in data quality that does not exist in traditional dataset assembly. A domain expert who consistently contributes verified, high-quality data builds a track record that increases their attribution weight and therefore their share of the reward distribution when that data is used in model training or inference.
Rejected submissions do not reduce a contributor's standing, which is a deliberate design choice. It allows for experimentation without penalizing contributors for testing the boundaries of what the system accepts. The system encourages participation while filtering for value.
Community ownership the concept and the challenge
The phrase "community-owned intelligence" raises a legitimate question: what does ownership actually mean in this context, and does the system deliver it in a meaningful way?
In OpenLedger's framework, ownership manifests primarily as financial participation. Contributors whose data is used in model outputs receive $OPEN token rewards proportional to their attribution score. The data itself is not owned in the sense of exclusive control it enters a shared ecosystem. But the economic value generated by that data flows back to contributors rather than being captured entirely by the platform.
This is a meaningful shift from how data is treated in traditional AI pipelines, where contributors receive nothing. It is not full data sovereignty in the sense that some decentralization advocates mean when they use the term. But as a practical implementation of shared economic stake in a data ecosystem, it is a more honest model than most alternatives currently offer.
The more significant challenge for community-owned Datanets is governance. Who decides what constitutes a valid submission in a given domain? How are disputes about data quality resolved? As Datanets grow and the financial stakes of inclusion increase, these governance questions become consequential. OpenLedger's current documentation outlines the technical mechanisms clearly but leaves some of the harder governance questions to evolve with the ecosystem — which is a reasonable approach for an early-stage system but one that will require careful attention as scale increases.
The specialized model ecosystem this enables
The commercial case for Datanets becomes clearer when you consider where AI development is heading. The era of one large general model handling every use case is giving way to an ecosystem of specialized models each fine-tuned for a specific domain, each requiring domain-specific data to perform at a level that professional users will actually trust.
A healthcare Datanet populated with verified clinical documentation, structured case records, and peer-reviewed research becomes the foundation for a medical AI that clinicians can rely on. A legal Datanet with structured case law and regulatory documentation becomes the training ground for AI that legal professionals can use with confidence. These are not theoretical applications they are the AI use cases that enterprises are actively trying to build and that general datasets cannot adequately support.
OpenLedger's ModelFactory provides the tooling to fine-tune models directly on Datanet data using LoRA and QLoRA optimization, making the pipeline from community data contribution to specialized model deployment accessible without requiring significant ML engineering resources. This closes the loop between data creation and model deployment in a way that positions Datanets as a genuine infrastructure layer rather than just a data storage mechanism.
What still needs to be proven
The Datanets concept is architecturally sound and commercially well-motivated. The execution challenges are real and worth acknowledging directly.
Building genuine domain expertise into a community-contributed dataset requires attracting the right contributors not just participants looking for token rewards, but actual domain specialists whose contributions carry the knowledge depth that makes specialized AI useful. Incentivizing that participation at scale, while maintaining quality standards, is a sustained community building challenge as much as a technical one.
The validation mechanisms also need to scale without becoming bottlenecks. As Datanets grow and submission volumes increase, the quality filtering layer needs to remain rigorous without creating delays that discourage participation. Automated validation handles format and structure efficiently. Domain-specific accuracy validation is harder to automate and will likely require human expert review at some level which introduces its own coordination and cost considerations.
These are known challenges with known approaches. Whether OpenLedger executes on them effectively is a question that the next twelve to eighteen months of development will answer more clearly than any analysis can today.
The direction is right
Community-owned domain intelligence is not just a philosophical preference. It is a practical necessity for AI applications that professionals will trust with consequential decisions. The traditional dataset model cannot deliver what specialized enterprise AI requires. A validated, attribution-tracked, domain-specific data ecosystem if built and governed well can.
@OpenLedger is building that ecosystem. The architecture is serious, the problem is real, and the commercial opportunity is significant. The execution will determine whether the vision translates into infrastructure that the AI industry actually adopts.
That is where the attention should be focused not on the token price, but on whether the data layer delivers what it promises when specialized AI models depend on it.