There's a weird thing that happens when you contribute data to an AI system. You expect some kind of record. A receipt. Something that says — this came from you, and here's what happened to it after.
That expectation doesn't survive contact with how most pipelines actually work. So I started checking OpenLedger more carefully, not from the whitepaper side, but from the behavior side. What does the chain actually say about who owns what, after the data moves.
the part that doesn't match
People assume that if data is attributed on-chain, ownership follows automatically. That attribution equals control.
What actually happens is more slippery. Attribution gets logged. But the downstream use — the model weights that form from aggregated contributions — those weights don't carry provenance in any recoverable way. The chain records that you contributed. It doesn't record what your contribution became.
I thought the ledger would be the proof. Turns out the ledger is more like a timestamp on a door you can't reopen.
I remember sitting with a dataset I'd been building for about eight months. Agricultural labeling work, fairly specific. Uploaded it through an integrated node last November, watched the confirmation, felt like something had been anchored. A few weeks later I tried to trace any derivative use. Nothing. The contribution record existed. The lineage didn't. That gap... it sat with me.
how the system is actually structured
The model OpenLedger uses is a contributor-node-verifier loop. Data comes in from contributors. Nodes validate and route it. Verifiers confirm the record. Incentives flow based on contribution scoring.
That loop is clean on paper. But the feedback doesn't close. There's no path from "model behavior changed because of this input" back to the original contributor signal. The system rewards entry. It doesn't reward traceable impact.
It's similar to a liquidity pool where you provide depth but can't see your specific capital doing anything. You get a share of fees. You don't get a trace of your trades. The abstraction works for the pool. It's uncomfortable for anyone who believed the abstraction was also an audit trail.
the part that still bothers me
OpenLedger governance proposals — including parameter updates around node validation thresholds — have been processed on-chain. Proposal 0x4a7... referenced in the governance module around late May 2026 touched verifier scoring weights. That's real system adjustment. The community can see the vote, see the outcome.
But this part still bothers me: the proposal changed how contributions are scored, retroactively affecting how existing contributions rank in the incentive model. No contributor was notified. The ledger moved without the contributors who built it.
That's not a bug exactly. But it's a tension that governance transparency doesn't fully resolve. Visibility and consent are still two different things.
loose comparisons, not conclusions
Ocean Protocol tried to solve something adjacent — data marketplaces with compute-to-data so your data never actually leaves. The tradeoff there was friction. Buyers had to trust the compute environment. Adoption stayed narrow.
Filecoin addresses storage provenance, not use provenance. Your file exists, verifiably. What a model does with it after retrieval is still outside the chain's sight.
OpenLedger sits between those approaches. More integrated than Ocean in terms of AI workflow. More ambitious than Filecoin on the attribution side. But neither comparison quite maps. The problem it's trying to solve is newer than both.
sitting with what I don't know
The honest version of data ownership in AI might not be about tracing your input through a model. That might be technically incoherent — weights blend everything, by design. The question might really be about governance rights, not data rights. Who gets to influence the system your data trained, not who can point at a weight and say mine.
If that's the actual problem, then the ledger is infrastructure for the wrong thing. And the real mechanism isn't on-chain attribution — it's token-weighted influence over model parameters. Which OpenLedger partially has, through its governance layer. But it's not framed that way. It's still framed as ownership.
I keep coming back to that gap between what the framing promises and what the mechanism delivers. Not because the mechanism is broken. Because the framing creates expectations the mechanism wasn't designed to satisfy. And when that mismatch meets a real contributor — someone with eight months of labeled data and a confirmation hash — it doesn't feel like a technical limitation. It feels like a broken promise.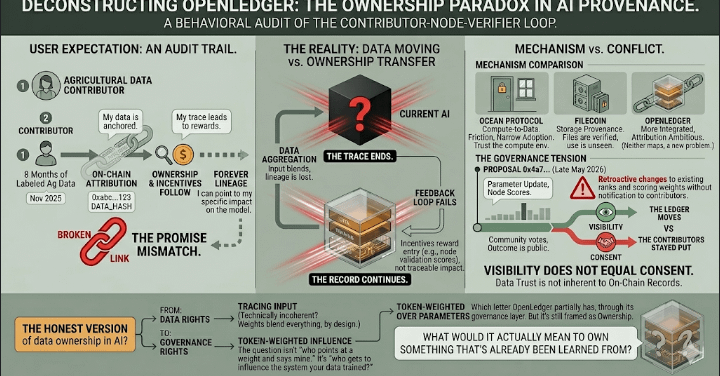
The on-chain record exists. The data trust does not, necessarily, follow.
What would it actually mean to own something that's already been learned from?