

A few years ago, most conversations about AI felt strangely simple. People argued about intelligence. Which model was smarter. Which company had more compute. Which architecture would dominate. The assumption underneath all of it was almost universal: if AI became good enough at thinking, everything else would eventually solve itself.
I used to think that too.
Lately, though, I've found myself paying attention to something much less exciting. Not intelligence. Not speed. Not even accuracy.
Memory.
Or maybe more specifically, what happens when machine memory starts behaving differently from human memory.
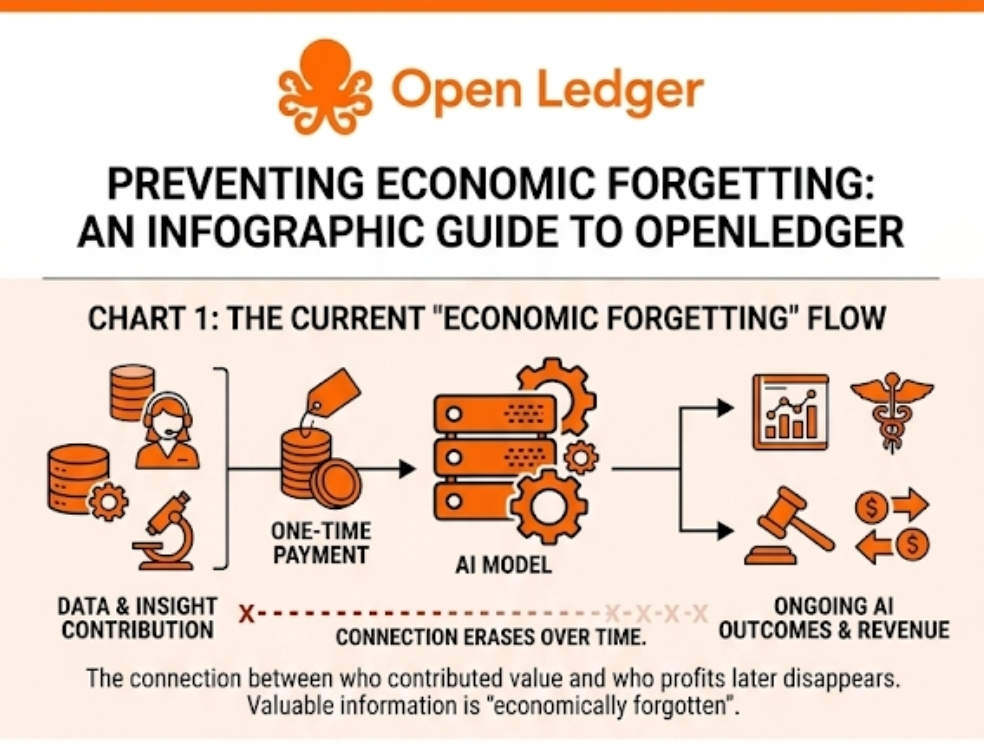
Humans forget things all the time. We forget conversations, details, names, mistakes. Sometimes forgetting is healthy. Entire legal systems are built around limiting how long certain information follows people around. But when an economy forgets important information, the consequences can be surprisingly expensive.
That distinction keeps nagging at me when I look at AI infrastructure.
Most people still talk about AI as if the core problem is generating better answers. Yet the more I watch enterprises experiment with AI, the less convinced I am that better answers are the real bottleneck. In many cases, the problem appears after the answer is generated.
Where did that information come from?
Who contributed it?
Can anyone verify it?
And perhaps most importantly, if something goes wrong six months later, can anybody reconstruct what happened?
Those questions sound boring until money gets involved.
I remember reading about a financial institution testing AI-assisted workflows. What interested me wasn't whether the model produced useful outputs. It was the compliance discussion afterward. The organization wasn't asking whether the AI was intelligent. They were asking whether they could explain the decision-making process to regulators if necessary.
That feels like a different category of problem entirely.
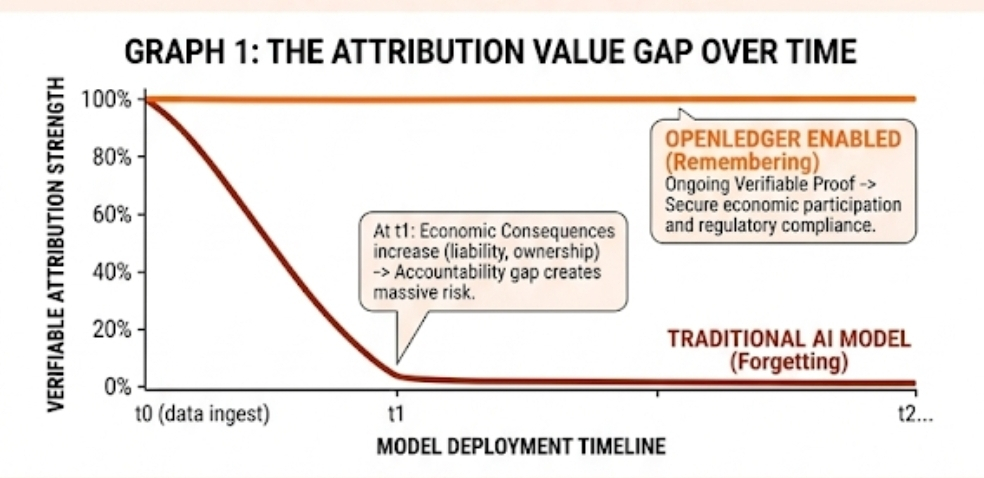
An economy can tolerate imperfect intelligence for a surprisingly long time. What it struggles to tolerate is invisible accountability.
That's partly why OpenLedger caught my attention.
A lot of AI projects are competing in the intelligence race. Faster models. Better reasoning. More efficient training. OpenLedger seems to be looking somewhere else. Almost underneath the AI itself.
The way I interpret it, the project is asking a strange question: what if the scarce resource isn't intelligence, but traceable knowledge?
At first, I thought that sounded like a branding exercise around data ownership. The more I sat with it, the less comfortable that explanation felt.
Because once AI systems start interacting with each other, the knowledge chain becomes messy very quickly.
Imagine ten AI systems contributing to a single output. One provides research. Another provides market data. Another contributes historical records. Others add analysis, filtering, or ranking mechanisms.
Eventually an answer appears.
Everyone sees the answer.
Almost nobody sees the path.
That hidden path may end up mattering more than the final output.
In traditional finance, ownership records are valuable because they allow markets to assign responsibility. In supply chains, provenance records matter because businesses need to know where products originated. In healthcare, documentation exists because memory cannot be trusted on its own.
Yet much of AI still operates as though attribution is optional.
That strikes me as odd.
We're building systems that increasingly influence economic decisions while simultaneously treating information lineage as secondary infrastructure.
Maybe that's fine while AI remains a productivity tool.
I'm less certain if AI becomes a participant in economic activity itself.
The OpenLedger thesis starts looking more interesting through that lens.
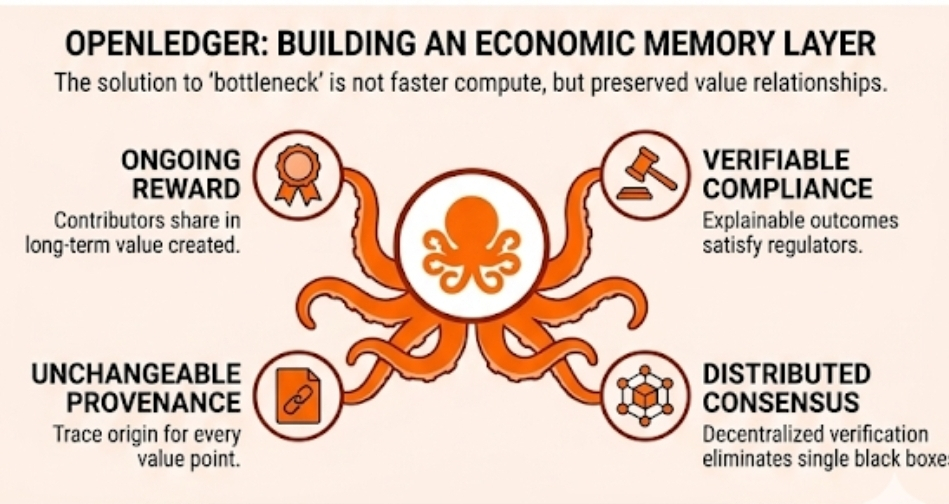
If data contributions remain traceable, knowledge doesn't simply enter a model and disappear. Contributors can potentially remain connected to downstream value creation. More importantly, decision chains become observable.
The market usually frames this as a reward problem. People contribute data and receive compensation.
I think that's only part of the story.
The larger issue might be economic memory.
When a system loses track of where knowledge originated, it gradually loses its ability to distinguish signal from noise. High-quality contributors become harder to identify. Bad information and good information begin competing on similar footing. Eventually incentives start drifting.
That process is slow. Almost invisible.
Then suddenly everyone notices quality deteriorating.
I've seen similar patterns outside AI. Financial markets often spend years optimizing efficiency before discovering they accidentally removed transparency. Social platforms optimize engagement before realizing they weakened credibility. Systems rarely break all at once. They drift.
AI infrastructure may face something similar.
Still, I don't think OpenLedger's path is straightforward.
There's a tradeoff here that nobody really talks about.
Remembering everything has costs.
Storage costs. Verification costs. Coordination costs.
Privacy complications too.
The same attribution layer that creates accountability can also create friction. Developers generally prefer simplicity. Enterprises often prefer flexibility. Users claim they want transparency, at least until transparency becomes inconvenient.
That's where many infrastructure narratives collide with reality.
Everyone supports accountability in theory.
Support becomes much thinner when accountability creates operational overhead.
Which is why I don't view OpenLedger as a guaranteed winner.
What I find interesting is the direction of the bet itself.
The industry is obsessed with making AI smarter. OpenLedger seems more interested in making AI economically accountable.
Those are not the same objective.
And I keep wondering whether the market is focusing on the wrong scarcity.
Compute becomes cheaper over time.
Models improve.
Inference costs fall.
But trusted records have a strange tendency to become more valuable as systems grow more complex.
Maybe AI forgetfulness sounds like a technical inconvenience today. A product issue. Something engineers eventually solve.
Maybe.
Or maybe forgetfulness becomes the hidden source of risk that nobody notices until entire AI-driven markets depend on remembering who contributed what, when, and why.
That's the possibility I keep coming back to.
Not because it's dramatic.
Mostly because economic history is full of examples where record-keeping looked boring right up until the moment it became essential.