
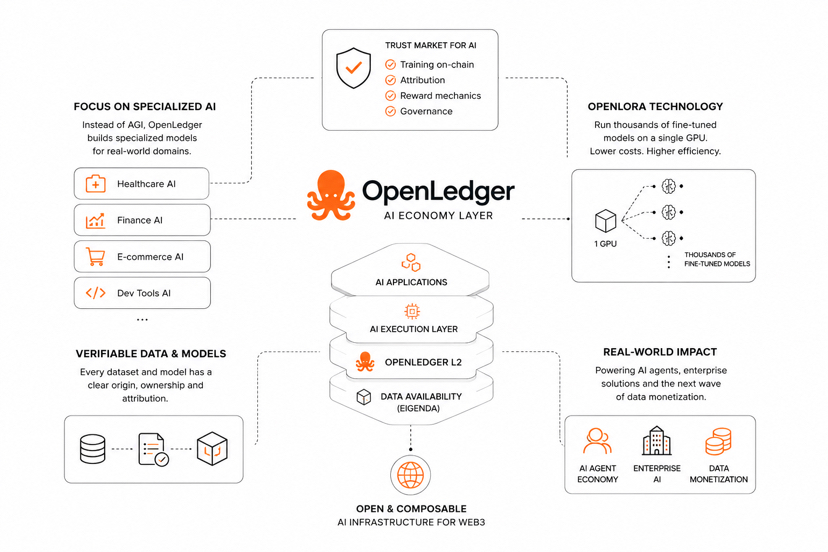
Je länger ich die Entwicklung des AI-Sektors beobachte, desto mehr fällt mir eine interessante Sache auf. Die meisten Projekte sind heute regelrecht besessen von der Idee, ein universelles AGI oder ein "Modell, das alles kann" zu schaffen. Und auf den ersten Blick scheint das logisch: je leistungsfähiger die KI, desto größer das Potenzial. Aber in der Realität benötigt das Business oft keine abstrakten, allwissenden Systeme, sondern präzise Modelle für spezifische Aufgaben, Nischen und Szenarien. Und genau hier @OpenLedger geht es etwas in eine andere Richtung. Anstatt dem Wettlauf nach universellen LLM nachzujagen, setzt das Ökosystem auf eng spezialisierte AI-Modelle und vertikale Lösungen für bestimmte Domänen. Und ehrlich gesagt, je länger man darauf schaut, desto mehr beginnt man zu verstehen — es geht hier nicht nur um ein "nächstes AI-Narrativ", das der Markt durchläuft und nach ein paar Monaten vergisst. Es geht um den Versuch, eine AI-Infrastruktur aufzubauen, die tatsächlich innerhalb der Web3-Wirtschaft funktionieren kann. Besonders interessant in diesem Zusammenhang ist OpenLoRA — ein Baustein, über den bisher viel weniger gesprochen wird, als er es verdient. Der Kern dessen ist, dass die Technologie es ermöglicht, Tausende von feinjustierten Modellen auf einer einzigen GPU zu starten. Und hier beginnt das, was wirklich Beachtung verdienen sollte. Denn heute wird Inference zu einem der teuersten Teile des AI-Marktes. Das Skalieren von Modellen kostet ein Vermögen. Die Infrastruktur wird schneller komplizierter, als der Markt das normal begreifen kann. Und während die meisten Projekte versuchen, ein schönes Bild von der "Zukunft der KI" zu verkaufen, @OpenLedger sieht es so aus, als ob sie versuchen, das eigentliche Fundament des Problems zu lösen — wie man KI günstiger, skalierbarer und für die reale Nutzung tauglich macht. Aber noch interessanter ist etwas anderes. Heute ist es fast unmöglich, KI ordnungsgemäß zu überprüfen. Ich werde ehrlich sein, das triggert und nervt mich wirklich, ich habe es satt! Wir wissen nicht, woher die Daten stammen, wer die Modelle tatsächlich erstellt hat, wie Attribution funktioniert und wie fair der Wert innerhalb des Ökosystems verteilt wird. Und je größer der AI-Sektor wird, desto stärker trifft dieses Problem die gesamte Industrie. Im #OpenLedger ist jetzt der Moment, an dem nicht nur die Technologie der AI-Modelle oder die Effizienz der Inference überprüft wird. Es wird die Möglichkeit geprüft, einen "Markt des Vertrauens" für AI zu schaffen. Wo das Training von Modellen, Attribution, Belohnungsmechaniken und Governance in ein On-Chain-Umfeld übertragen werden, und Daten sowie Intelligenz nicht mehr als geschlossene Ressource großer Unternehmen existieren. Und ehrlich gesagt fesselt mich der Gedanke, dass die Entwicklung $OPEN potenziell nicht nur auf dem Hype um AI basieren könnte, sondern darauf, wie das Ökosystem lernt, Vertrauen zwischen Modellen, Daten und Nutzern aufzubauen. Denn die KI der Zukunft… das bezieht sich nicht nur auf die Modelle selbst. Es geht um Transparenz. Interaktion. Die Wirtschaft um sie herum. Und wenn OpenLedger es schaffen kann, KI in ein composable On-Chain-System zu verwandeln, wo Daten, Modelle und Agenten als ein einziges Netzwerk funktionieren — könnte das viel wichtiger werden als der nächste "revolutionäre AI-Token", den der Markt unter Asphalt begräbt und den man höchstens bis zum nächsten Zyklus in Erinnerung behält
Mal sehen, ob die Idee durchstartet oder wie Hunderte ähnliche in den Graben fliegt 🫠
