
熬夜刷完$OPEN 社区,越琢磨越慌!这个看似踩中AI+Web3风口的优质项目,藏着两个白皮书绝口不提的致命问题,普通玩家真的要谨慎!
平心而论,@OpenLedger 的逻辑真的没毛病。归因证明、数据合作社,精准解决了AI行业数据确权、贡献无回报的痛点,绝对是赛道里的正经好方向。
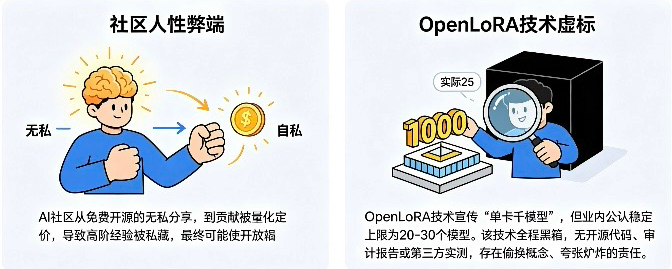
但最大的隐患,从来不是技术,是人性!
以前AI圈全是免费开源氛围,大佬随手分享Prompt、训练技巧、踩坑干货,行业进步全靠社区无私共享。可OPEN把所有数据、经验贡献量化定价、链上确权,彻底改变了游戏规则。
当每一份经验都能换钱,谁还愿意免费公开分享?高阶训练方法、Agent工作流这些核心干货,只会被私藏起来。参考Web3早期内容平台,为奖励逐利的结局就是社区变质、优质内容枯竭。一旦公开贡献度暴跌,AI赖以发展的开放协作生态,直接就废了!
更离谱的是近期爆火的OpenLoRA,完全是夸大炒作!
业内公认天花板摆在这:斯坦福LoRAX、S-LoRA顶配环境下,最多稳定跑二三十个模型,再多就延迟崩盘、彻底失效。
但OPEN直接喊出单卡千模型,数据虚标超40倍!最扯的是全程纯黑箱,无开源代码、无审计报告、无实测Demo、无第三方数据,所有亮眼参数全是项目方自吹自擂。
说白了就是偷换概念!把硬盘可存储的LoRA补丁数量,冒充成实时可运行的模型数量,纯纯忽悠小白。
真心看好OPEN的赛道布局,但社区逐利化、技术数据注水这两个硬伤不解决,再华丽的架构都是空壳。
你们觉得OPEN是真有硬实力,还是靠包装炒作的伪创新?#OpenLedger

OPENUSDT
Perp
0.1801
+3.62%