
The more time i spend reading AI infrastructure designs, the more i think the hardest problems are no longer happening inside the models themselves.
They’re happening around them.
Training tends to get most of the attention because it feels tangible. Bigger datasets. Better architectures. Improved performance benchmarks.
But eventually another constraint starts appearing.
Deployment.
Because a model that works in a lab and a model that operates economically at scale are not necessarily the same thing.
That’s the part of @OpenLedger OpenLoRA architecture that caught my attention .
The system isnt primarily trying to make individual models smarter.
Its trying to make large numbers of specialized models economically deployable.
Those are very different objectives.
OpenLoRA is built around the idea that multiple fine-tuned models can share a common backbone while dynamically loading only the specialized components required for a specific request .
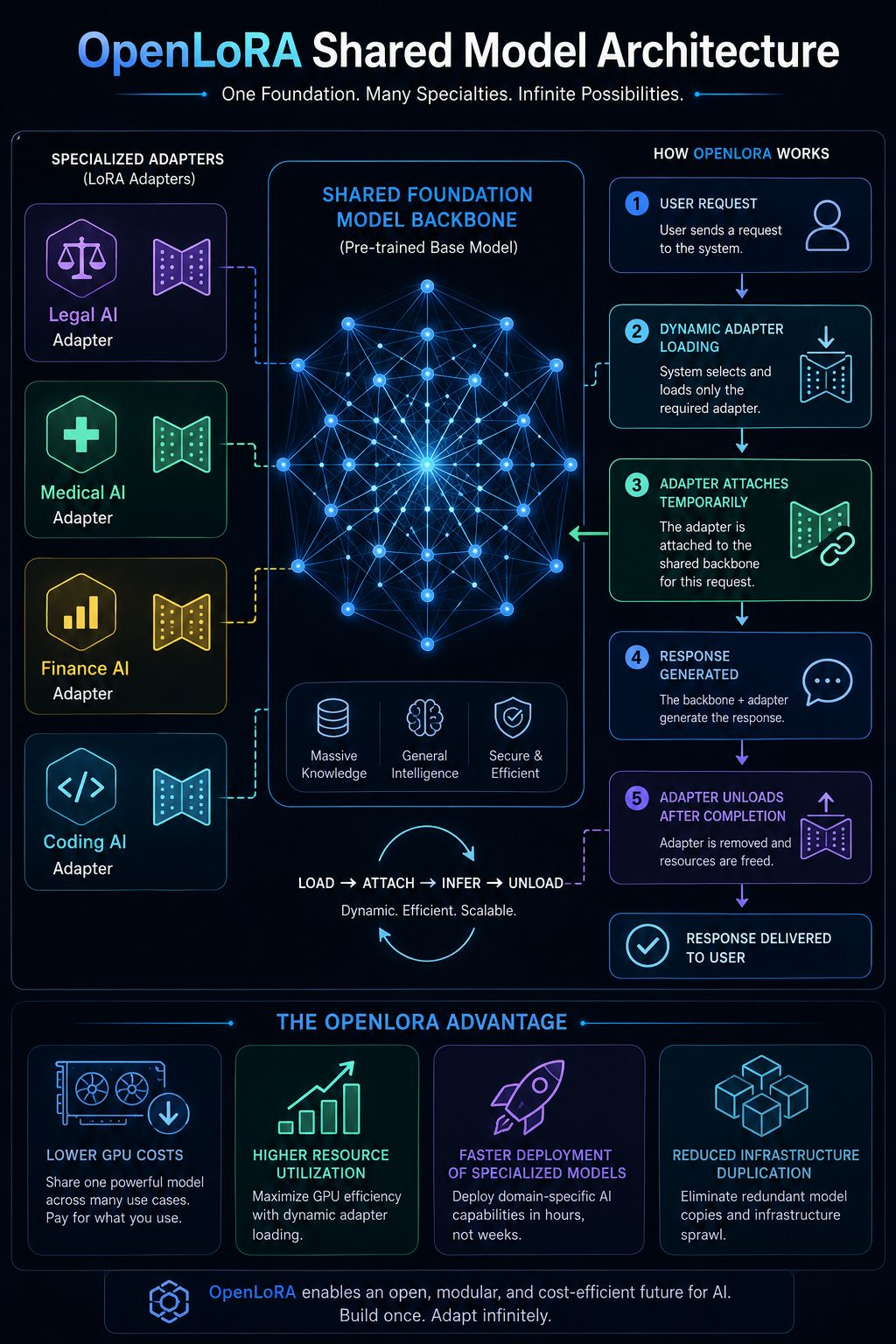
Conceptually, thats a strong infrastructure decision.
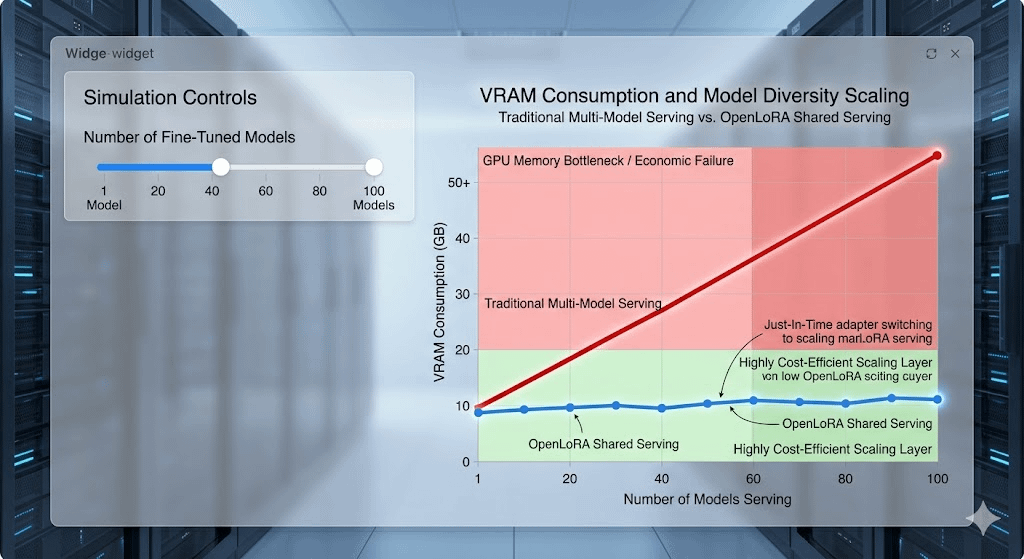
Because dedicated resources for every specialized model create an obvious scaling problem.
As the number of models grows, infrastructure costs grow with them.
Eventually the economics stop making sense.
Shared resource architecture offers a different path.
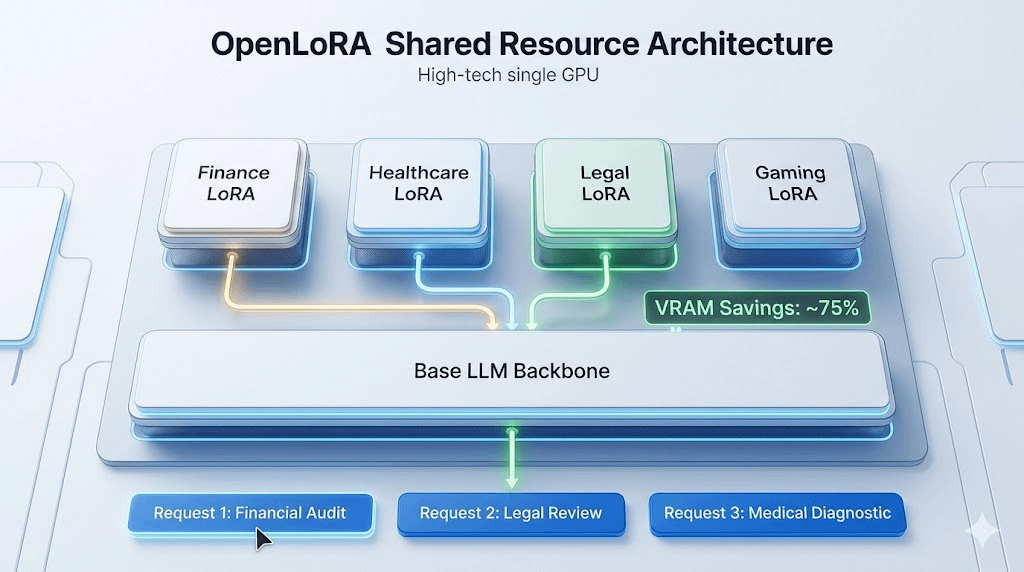
Instead of replicating everything repeatedly, the system attempts to maximize utilization of existing computational resources.
That sounds efficient.
And efficiency usually wins.
But infrastructure optimization always introduces tradeoffs.
The more aggressively resources are shared, the more coordination pressure emerges.
Suddenly the challenge isnt raw compute anymore.
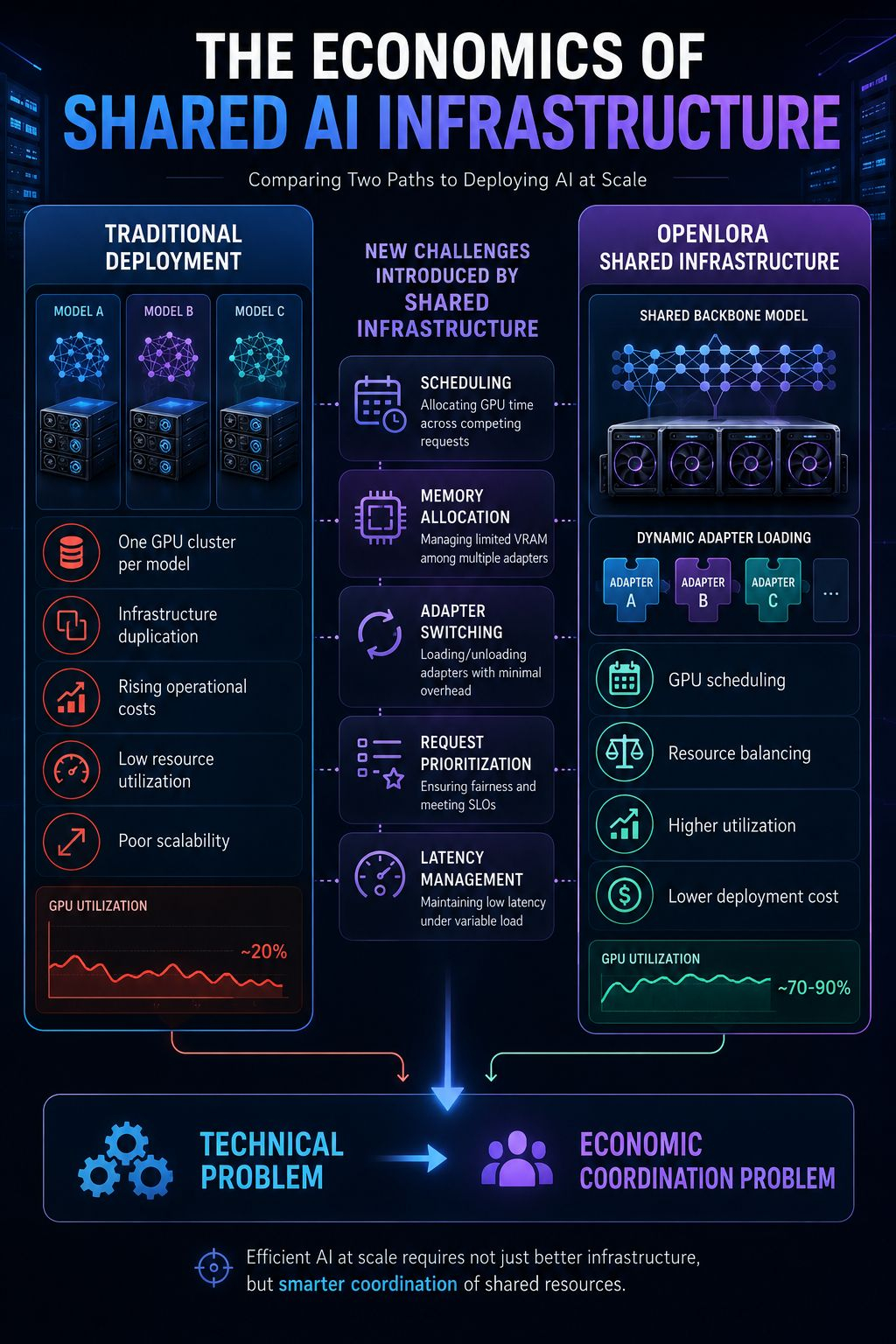
Its scheduling.
Memory allocation.
Adapter switching.
Request prioritization.
Latency management.
OpenLedger’s architecture addresses some of this through dynamic model loading, GPU scheduling mechanisms, and resource balancing strategies designed to keep utilization high while avoiding bottlenecks .
On paper, thats exactly where infrastructure innovation should happen.
The question is whether those optimizations remain effective as model diversity expands.
Because shared systems become harder to manage as heterogeneity increases.
Different workloads create different performance requirements.
Different applications tolerate different latency thresholds.
Different users create different demand patterns.
Eventually infrastructure stops behaving like a technical problem and starts behaving like an economic coordination problem.
And those tend to be much harder.
Still, i think OpenLoRA focuses attention on something the industry often overlooks.
AI isnt only competing on intelligence.
Its competing on efficiency.
The model with slightly lower performance but dramatically lower operational cost often becomes more useful than the model with marginally better benchmark scores.
Especially if specialized AI ecosystems continue growing.
In that world, deployment efficiency becomes a strategic advantage rather than a technical detail.
Which makes OpenLoRA less interesting as a model framework and more interesting as an economic infrastructure layer.
Can shared model-serving architecture scale alongside growing specialization, or does increasing complexity eventually overwhelm the efficiencies it creates