 I keep coming back to a simple contradiction in crypto and AI: everyone says data is valuable, but most systems still treat the people who create, clean, label, or refine that data as if they were invisible. The same thing happens with models and agents. We celebrate the interface, the demo, or the output, but we rarely get a clear accounting of who contributed what, who can prove it, and who should be paid when the output becomes useful. OpenLedger positions itself directly inside that gap, describing itself as an AI blockchain built to unlock liquidity for data, models, and agents. That framing matters because it is less about adding “AI” to a chain and more about asking whether AI can be organized around attribution instead of opacity.
I keep coming back to a simple contradiction in crypto and AI: everyone says data is valuable, but most systems still treat the people who create, clean, label, or refine that data as if they were invisible. The same thing happens with models and agents. We celebrate the interface, the demo, or the output, but we rarely get a clear accounting of who contributed what, who can prove it, and who should be paid when the output becomes useful. OpenLedger positions itself directly inside that gap, describing itself as an AI blockchain built to unlock liquidity for data, models, and agents. That framing matters because it is less about adding “AI” to a chain and more about asking whether AI can be organized around attribution instead of opacity.
Before a project like this appears, the recurring problem is easy to see. AI systems are trained on datasets assembled from many hands, yet the contribution chain usually disappears the moment training begins. The resulting model can be powerful, but the provenance of its ingredients is often murky, and the people who supplied the data are rarely visible in the final economic picture. OpenLedger’s own material is explicit about this complaint: it argues that today’s AI lacks transparency, that contributors go uncredited, and that centralized actors end up controlling the most valuable models. I think that diagnosis is broadly correct, even if the cure is still uncertain. The same grievance has shown up repeatedly in older attempts at data marketplaces, licensing systems, and decentralized AI projects, and they have usually stumbled for the same reason: they can describe value, but they struggle to measure it cleanly enough to distribute it fairly.
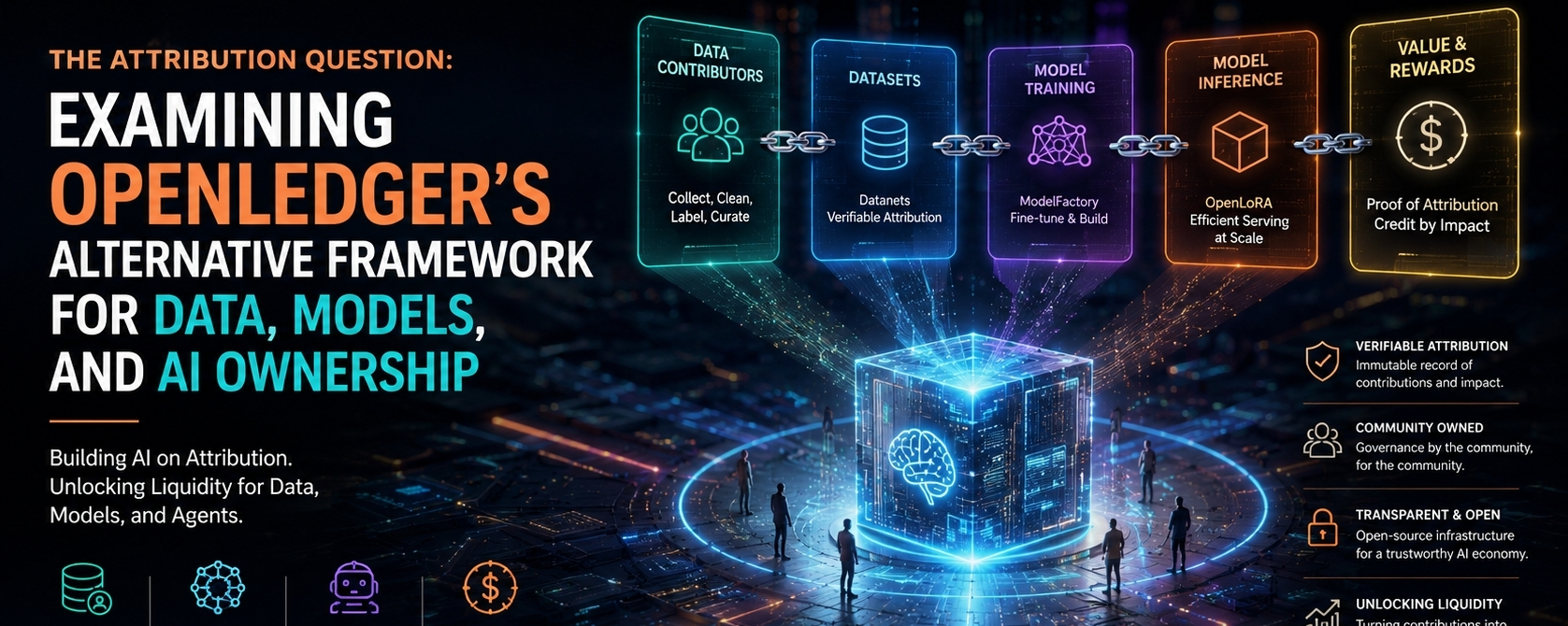
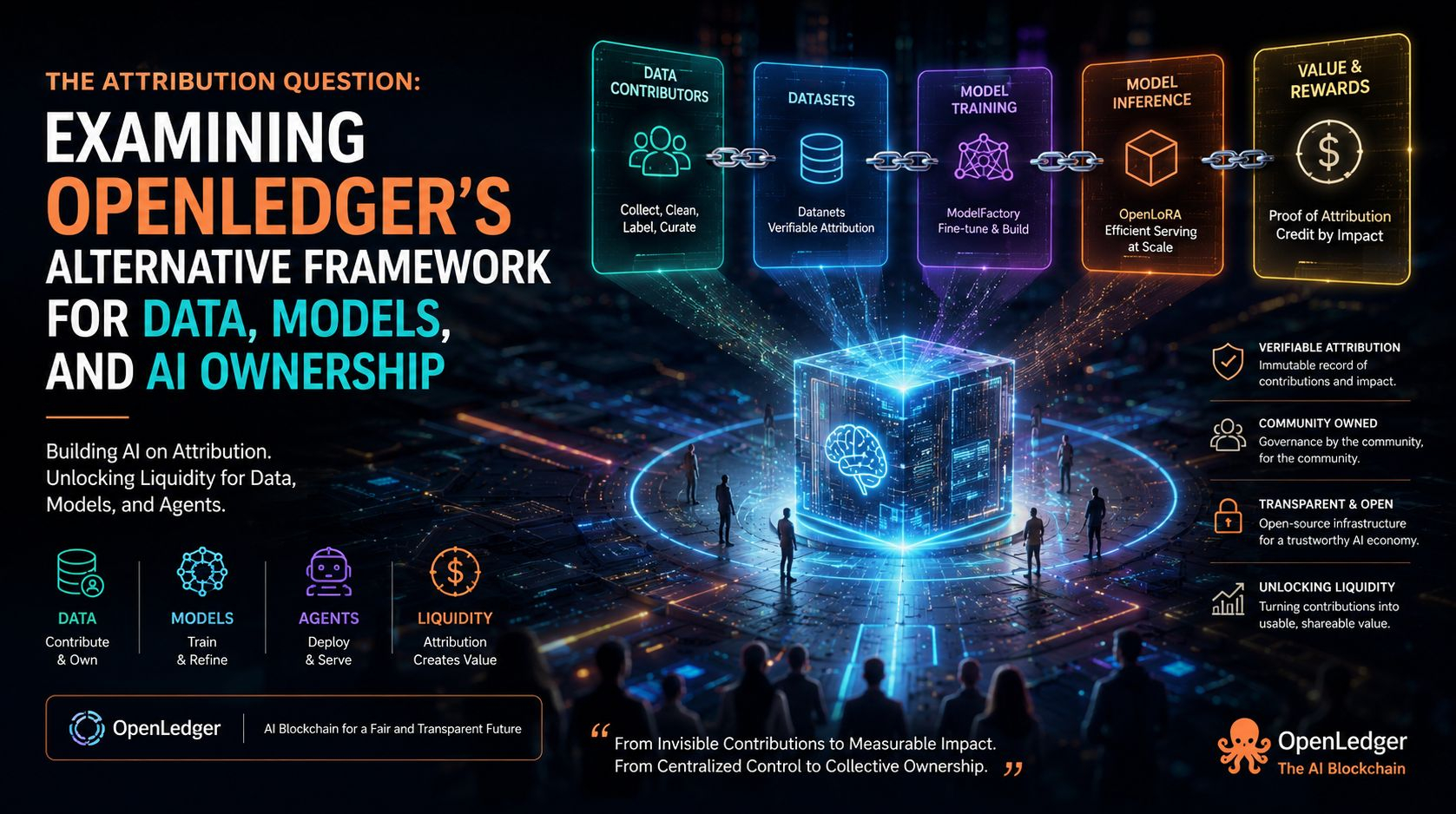
What interests me about OpenLedger is that it does not present itself as a generic blockchain with an AI theme. In its documentation, it defines OpenLedger as an AI-blockchain infrastructure for training and deploying specialized models using community-owned datasets, which it calls Datanets. It also says that dataset uploads, model training, reward credits, and governance participation all happen on-chain. That is a serious design choice, because it turns the protocol into an accounting layer for AI activity rather than a passive settlement rail around it. In principle, that lets the system treat contributions as first-class events instead of after-the-fact social claims. In practice, of course, the hard part is not recording activity; it is deciding what counts, how it is weighted, and whether the recorded facts are meaningful enough to support real coordination.
The Datanet idea is the clearest expression of that ambition. OpenLedger describes Datanets as decentralized data networks that aggregate, validate, and distribute domain-specific datasets for model training, with verifiable attribution attached to contributions. I read that as an attempt to make the data layer more intentional and narrower in scope. Instead of one giant, vaguely curated corpus feeding a general-purpose model, the protocol prefers structured repositories around specialized use cases. That makes sense, because many of the best AI systems are not broad in a philosophical sense; they are narrow, disciplined, and built on data that is good enough for a specific task. But specialization has its own tax. It raises the coordination cost of finding contributors, the curation cost of maintaining quality, and the adoption cost of convincing anyone that a new dataset is worth the overhead of entering it into a formal system.
Proof of Attribution is where OpenLedger tries to turn that coordination into something enforceable. The documentation describes it as a cryptographic mechanism that links data contributions to AI model outputs, keeping an immutable record of contributions and assigning credit and rewards based on data impact. That is a thoughtful response to one of AI’s oldest structural problems: the output is visible, but the causal chain behind it is not. If the mechanism works as intended, it could give data providers a way to see when their input mattered and reward them accordingly. Still, I am skeptical in the right way. Attribution is not the same thing as truth, and traceability is not the same thing as quality. A system can prove that a dataset was used without proving that the dataset was good, lawful, unbiased, or even appropriate for the result it helped produce. That distinction is where many attribution systems become more fragile than their diagrams suggest.
ModelFactory extends the same logic upward into model creation. OpenLedger describes it as a fine-tuning platform for large language models that runs under the OpenLedger ecosystem and offers a GUI-only experience for working with permissioned datasets. I see that as a practical move, because most useful AI work is not done by people who want to wrestle with infrastructure. If the project wants contributors, curators, and smaller teams to participate, then lowering the technical barrier is not cosmetic; it is essential. Yet the trade-off is familiar. The easier a platform is to use, the more it has to hide complexity behind the interface, and the more the system’s credibility depends on whether that hidden machinery is actually reliable. A polished interface can make a serious workflow accessible, but it cannot substitute for trustworthy rules about data rights, dataset quality, or model governance.
OpenLoRA pushes the idea further into serving and inference. The docs say it is designed to serve thousands of fine-tuned LoRA models on a single GPU through dynamic adapter loading, memory-efficient merging, and optimizations such as tensor parallelism, flash attention, paged attention, quantization, and token streaming. That is not a casual detail. It suggests that OpenLedger is trying to solve not only the problem of building specialized models, but also the problem of serving many of them economically. In other words, the protocol is not only imagining ownership and attribution; it is also trying to reduce the friction of deploying many small, domain-specific models rather than one giant monolith. That is a compelling direction, because it matches how a lot of real work actually happens. But it also creates another execution burden: the more layers a platform adds, the more places there are for complexity, latency, and maintenance cost to accumulate.
The ecosystem around the project shows how broad the ambition is. On the official site, OpenLedger highlights products such as Explorer, Staking, AI Studio, and a live agent experience called OctoClaw, while the documentation says governance is powered by a hybrid on-chain system using OpenZeppelin’s modular Governor framework and token holders participate in protocol direction and upgrades. That combination tells me the project is not merely a research sketch. It is trying to become a full stack: data onboarding, model training, inference, governance, and user-facing applications. I respect the completeness of that ambition, but completeness can be a burden. The more surfaces a protocol exposes, the harder it is to keep each one coherent, secure, and genuinely useful. A project can look conceptually elegant while still struggling to make one or two of its surfaces feel indispensable in daily use.
My main reservation is that attribution-heavy systems tend to assume a degree of clean input that the real world does not reliably provide. Data is messy before it becomes on-chain. Rights are often ambiguous. Contributors may be difficult to verify. Labels can be wrong. Entire datasets can be assembled from uneven, partially trusted sources. OpenLedger’s mechanism can record what happened, but it cannot magically rescue bad inputs from becoming trusted outputs. That is why the project feels more like an accounting experiment than a finished solution. Accounting can improve fairness, but it can also create a false sense of precision if the underlying measurements are weak. The system may end up being most valuable precisely where the data is already organized, professional, and cooperative, which is also where the problem is easier to solve in the first place.
There is also the matter of adoption friction. A community-owned dataset model sounds fairer than the status quo, but fairness does not automatically produce participation. Contributors need reasons to join, buyers need reasons to trust, and builders need a workflow that is easier than the centralized alternatives they already use. If the protocol is too rigid, it will feel academic. If it is too loose, attribution becomes cosmetic. If governance becomes too political, the system may slow down just when it needs decisive iteration. These are not minor implementation concerns; they are the ordinary failure modes of protocols that try to move beyond simple transfer mechanics and into social coordination. OpenLedger’s own product list suggests that it understands this, but acknowledging the problem is not the same as solving it.
I think the most plausible beneficiaries are not generic AI consumers but the people closest to specialized knowledge: domain data providers, niche model builders, small teams assembling permissioned datasets, and communities that care about proving contribution rather than simply consuming output. Those are the users who may gain the most from a system that preserves provenance and distributes credit. The people who remain outside the frame are just as important, though: casual users who do not care about attribution, enterprises that prefer simpler procurement, and developers who want scale without protocol overhead. That leaves me with the question I cannot quite settle: if AI is becoming a layer of abstraction over human judgment, can a blockchain-based accounting system really preserve the human chain of contribution without turning the whole thing into a more elaborate machine for describing value that still cannot fully agree on how to measure it?