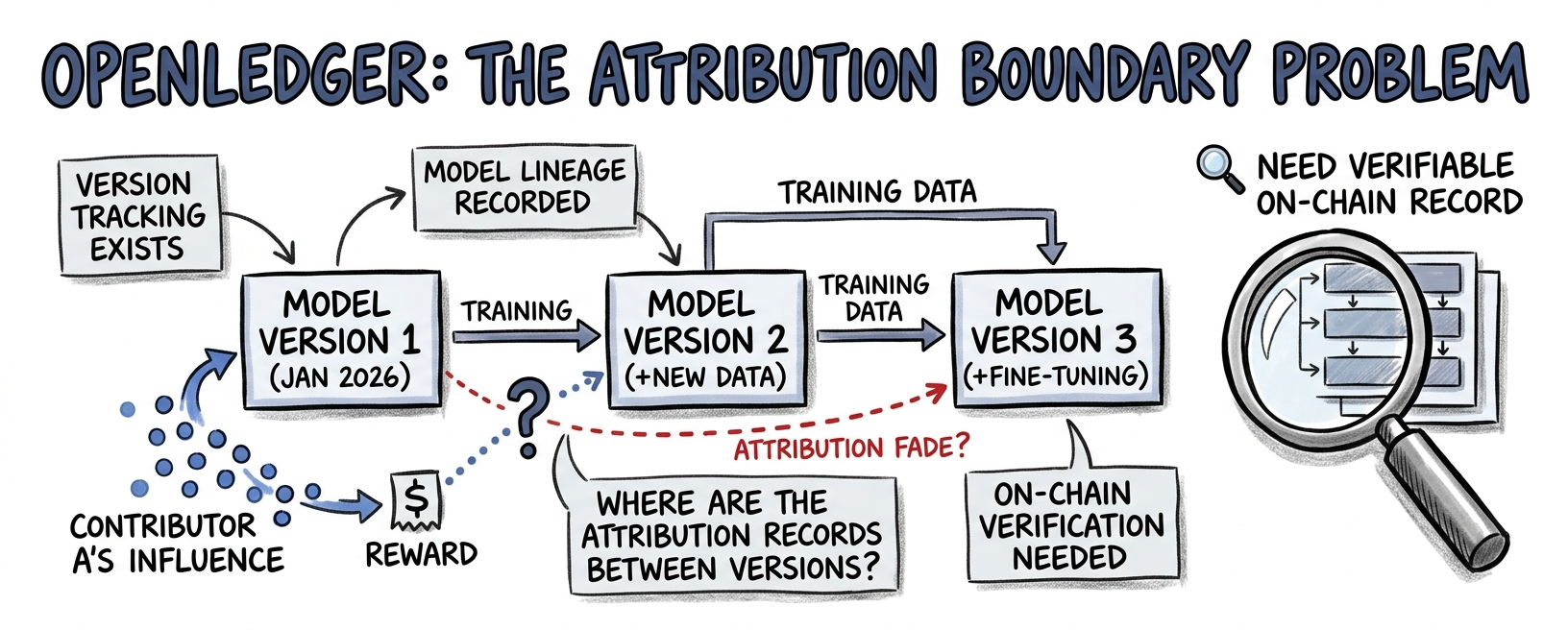
Ich habe vor ein paar Tagen die Dokumentation zur Modellversionierung durchgesehen und mit lockeren Definitionen und vagen Zusagen zur zukünftigen Entwicklung gerechnet. Tatsächlich war es das nicht. Die Versionierungsstruktur ist sorgfältiger gestaltet als die meisten AI-Protokolle in dieser Phase. Versionierungstracking existiert. Die Modellabstammung wird aufgezeichnet. Die Dokumentation liest sich, als hätte jemand darüber nachgedacht, bevor sie ausgeliefert wurde, und nicht danach.
Dann habe ich versucht nachzuvollziehen, was mit den Attributionsaufzeichnungen passiert, wenn ein Modell von einer Version zur nächsten wechselt.
Jedes Mal, wenn ein Modell aktualisiert wird, neue Trainingsdaten hinzugefügt, Feinabstimmungen angewendet, Architektur angepasst wird, produziert es eine neue Version. Dieses Versionieren ist das korrekte technische Verhalten. Modelle sollten sich weiterentwickeln. Datanets sollten sie verbessern. Der ganze Punkt des Beitragsloops von Openledger ist, dass bessere Daten über die Zeit bessere Modellversionen produzieren. Aber die Attribution wird basierend darauf berechnet, welche Daten welchen Modelausgang beeinflussten. Wenn sich die Modellversion ändert, ändert sich auch die Beziehung zwischen Trainingsdaten und Modelausgang. Die Daten von Mitwirkendem A hatten möglicherweise starken Einfluss auf Version 1. Version 2, die mit zusätzlichen Daten trainiert wurde, zeigt möglicherweise einen schwächeren gemessenen Einfluss von Mitwirkendem A's ursprünglichem Beitrag. Version 3 könnte noch schwächer zeigen.
Was ich nicht finden konnte, war eine öffentliche Dokumentation, die bestätigt, wie sich Attributionsaufzeichnungen an den Versionsgrenzen verhalten. 🔍
Diese Lücke ist wichtig, weil der Versionszyklus und der Attributionszyklus auf unterschiedlichen Zeitlinien laufen und möglicherweise in entgegengesetzte Richtungen. Der Versionszyklus belohnt die Verbesserung des Modells; jede neue Version repräsentiert bessere Fähigkeiten, was mehr Nachfrage nach Inferenz anziehen sollte, was mehr Attributionsereignisse und mehr Belohnungen generieren sollte. Der Attributionszyklus belohnt historischen Einfluss. Mitwirkende, die die grundlegenden Fähigkeiten des Modells geprägt haben, sollten weiterhin verdienen, während diese Fähigkeiten Werte generieren. Diese beiden Zyklen weisen auf unterschiedliche Mitwirkendenprofile zu unterschiedlichen Zeitpunkten im Leben des Modells hin. Und an jeder Versionsgrenze ist die Frage, wie viel von der Attribution der vorherigen Version in die Berechnung der neuen Version übertragen wird, genau die Frage, die die Dokumentation nicht beantwortet.
Ich habe etwas strukturell Ähnliches mit Inhaltsempfehlungsalgorithmen beobachtet, als Streaming-Plattformen 2018 und 2019 begannen, ihre Modelle zu versionieren. Kreatoren, die unter einem Algorithmus Publikum aufgebaut hatten, entdeckten, dass Versionsupdates dramatisch ändern konnten, wie ihr Inhalt verteilt wurde, nicht weil ihr Inhalt schlechter wurde, sondern weil die neue Modellversion unterschiedliche Signale gewichtet hat. Die Attribution früherer Leistungen auf zukünftige Reichweite wurde nicht so weitergetragen, wie die Kreatoren es angenommen hatten. Die Plattformen verstanden, dass dies geschah. Sie haben es nicht transparent gemacht. Kreatoren entdeckten es durch sinkende Metriken, anstatt durch Dokumentation.
Das Versionsgrenzen-Problem von Openledger hat die gleiche Form, aber eine spezifischere wirtschaftliche Konsequenz. Wenn Attributionsaufzeichnungen an den Versionsgrenzen zurückgesetzt oder degradiert werden, werden frühe Mitwirkende, die das grundlegende Verhalten eines Modells geprägt haben, zunehmend unterbezahlt, während sich das Modell verbessert. Das Modell wird besser. Ihr gemessener Einfluss wird kleiner. Ihre Belohnungen schrumpfen. Nicht, weil ihr Beitrag an Wert verloren hat, im Gegenteil. Das Modell ist wertvoller, genau weil ihre grundlegende Arbeit gut war. Aber die Attributionsberechnung in späteren Versionen kann diesen grundlegenden Einfluss möglicherweise nicht klar genug über die Versionsgrenze nachverfolgen, um ihn proportional zu würdigen.
Das wirklich starke Element hier ist, dass das Attributions-Engine-Update von Openledger aus Januar 2026 speziell dafür entwickelt wurde, Daten-Ausgaben-Links aufrechtzuerhalten, während sich Modelle weiterentwickeln. Dieses Update existiert, weil das Team die Evolution des Modells als Herausforderung für die Persistenz der Attribution identifiziert hat, was bedeutet, dass sie bereits über das Versionsgrenzenproblem nachdachten, bevor es in den Belohnungsmustern der Mitwirkenden sichtbar wurde. Das ist mehr Vorausblick, als die meisten KI-Blockchain-Projekte zeigen, und ein echter Grund zu glauben, dass die Ingenieure ihre Aufmerksamkeit an die richtige Stelle richten.
Es gibt eine Version davon, wo ich falsch liege. Das Attributions-Engine-Update könnte eine explizite Version-Grenzen-Attribution Carryforward implementiert haben, ein Mechanismus, der den Einfluss von Mitwirkenden über Versionsübergänge hinweg nachverfolgt und sicherstellt, dass grundlegende Beiträge ihr angemessenes Gewicht beibehalten, unabhängig davon, wie viele Versionen ihnen folgen. Wenn dieser Mechanismus existiert und läuft, degradiert die Attribution nicht an den Version-Grenzen und frühe Mitwirkende sind geschützt. Was ich in der öffentlichen Dokumentation nicht finden konnte, war eine Bestätigung, dass dieses spezifische Problem gelöst wurde, anstatt identifiziert.
Was ich sehen möchte, ist ein öffentliches Attributionsprotokoll von einem Modell, das seit dem Start des Mainnets mindestens zwei Versionsupdates durchlaufen hat und spezifisch zeigt, wie sich der Attributionsanteil von Mitwirkendem A zwischen Version 1, Version 2 und Version 3 desselben Modells geändert hat. Keine Erklärung, wie die Versionsgrenzenattribution funktionieren sollte. Ein tatsächlicher On-Chain-Datensatz, der zeigt, was sie tut. Dieser spezifische Datensatz, der von einem Modell kommt, das sich derzeit in seiner dritten oder späteren Version auf dem Mainnet befindet, würde mir sagen, ob das Attributions-Engine-Update frühe Mitwirkende durch Versionsübergänge geschützt hat oder ob es die Nachverfolgung der Modellentwicklung angegangen ist, ohne das Grenzenproblem vollständig zu lösen. Seine Abwesenheit bedeutet, dass die loyalsten Mitwirkenden von Openledger – diejenigen, die früh beigetragen haben und geblieben sind – derzeit davon ausgehen, dass ihr grundlegender Einfluss weitergetragen wird. Diese Annahme könnte korrekt sein. Aber sie ist noch nicht überprüfbar. Und für ein Protokoll, dessen gesamtes Wertversprechen darin besteht, Annahmen durch überprüfbare Attribution zu ersetzen, ist das die eine Lücke, die am meisten zählt.
