There’s something about OpenLedger that keeps pulling me back into the same thought again and again...
Are we actually witnessing the early foundation of a new AI economy right now or years later will we look back at this moment and quietly realize this was where it all started?
Because honestly, what makes OpenLedger interesting to me is not just the technology itself. It’s the idea underneath it.
Everyone talks about AI infrastructure, AI-native blockchains, Payable AI, decentralized intelligence all of it sounds advanced and futuristic. But once you strip away the technical language, the real question becomes surprisingly simple:
If data is becoming the fuel of AI, then who truly owns the value created from it?
That’s the part that changes everything.
OpenLedger presents itself as an EVM-compatible Layer-2 network, but the deeper story isn’t really about the chain. It’s about the economic layer forming beneath AI itself.
And that’s where things become genuinely fascinating.
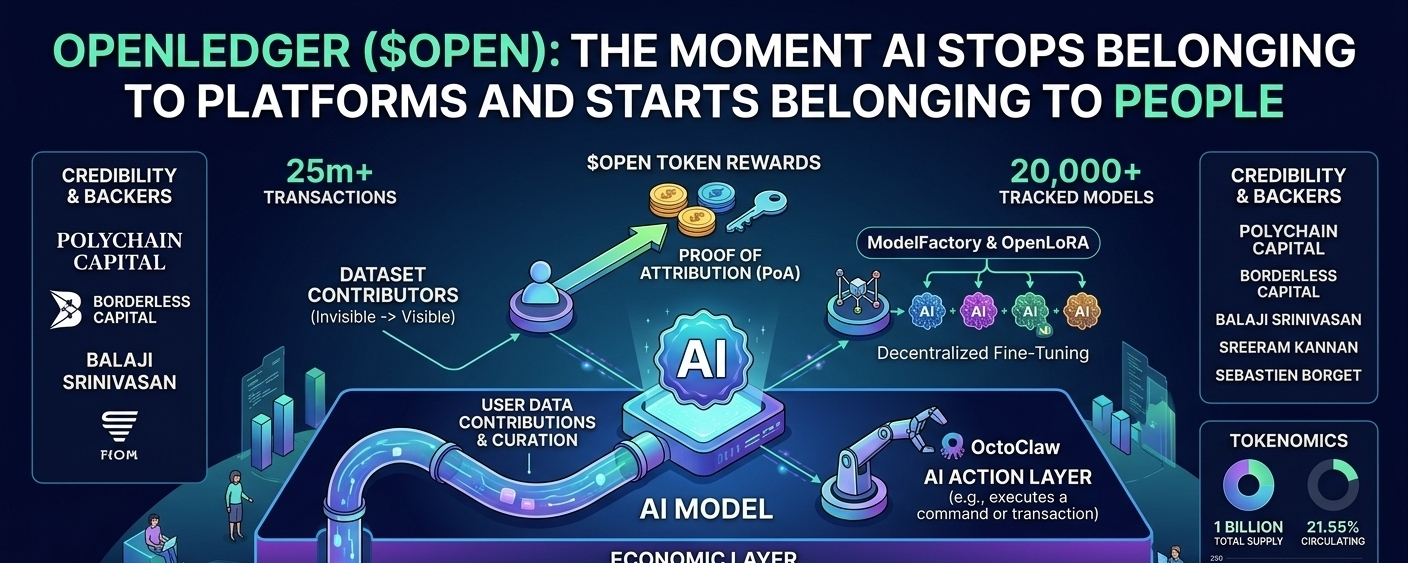
Inside the OpenLedger ecosystem, data is no longer treated like passive storage. It becomes an active economic asset. Users contribute datasets, curate information, and help shape the intelligence that AI models learn from. In a strange way, people themselves become part of the AI supply chain.
But at the same time, another thought quietly appears in my mind:
How much of this participation is genuine value creation… and how much is simply incentive-driven behavior?
That tension matters.
Then there’s ModelFactory and OpenLoRA — probably one of the more technically ambitious parts of the ecosystem. The vision sounds powerful: decentralized fine-tuning, serving multiple models through a single GPU, lowering AI deployment costs, improving scalability.
On paper, it feels efficient.
But I still wonder whether this is already moving toward real-world adoption, or if we’re still standing inside the early phase of engineering optimism where everything sounds possible before true scale arrives.
And then OpenLedger introduces OctoClaw.
This is where the narrative shifts again.
Because now AI is no longer just learning or generating outputs. It starts becoming an execution layer. An action-taking system operating in real time.
And honestly, that’s the moment where the line between assistance and autonomy starts feeling a little blurry.
The part that intrigues me most though is Proof of Attribution (PoA).
In traditional AI systems, the people contributing data usually disappear into the background. Their role becomes invisible the moment a model produces value.
OpenLedger is trying to change that dynamic completely.
The idea is simple but powerful: when AI generates output, the system attempts to trace which datasets contributed to that intelligence — and then rewards contributors through the $OPEN token economy.
Conceptually, it feels like one of the most important ideas in modern AI infrastructure.
But again, the deeper question remains:
How accurate can attribution truly become once data flows through layered models, recursive learning systems, and continuously evolving outputs?
Because attribution in AI sounds clean in theory.
Reality is rarely that clean.
Then there’s the ecosystem growth itself.
Over 25 million transactions. More than 20,000 tracked models. Numbers like these definitely create momentum around the project.
But momentum and adoption are not always the same thing.
Crypto has shown that many times before.
Still, OpenLedger has attracted serious attention. Names like Polychain Capital, Borderless Capital, Balaji Srinivasan, Sreeram Kannan, and Sebastien Borget naturally add credibility to the ecosystem.
And credibility matters.
But legitimacy alone does not guarantee long-term sustainability.
That’s where tokenomics enters the conversation — and honestly, this might be the most delicate part of the entire system.
The total supply sits at 1 billion tokens, with roughly 21.55% currently circulating. That part is manageable for now.
But the real pressure point begins later.
Starting in September 2026, the cliff for team and early investor allocations ends, followed by a 36-month linear unlock period.
And historically, unlock structures like these quietly reshape entire ecosystems.
Because if token emissions increase faster than real demand growth, the market eventually feels that pressure.
This is where the real tension around OpenLedger begins to emerge.
On one side, the project is building toward an AI-powered ownership economy.
On the other side, the market still operates on liquidity cycles, speculation, incentives, and survival psychology.
And those two worlds do not always move together.
That’s why OpenLedger feels so interesting to me.
Not because everything is already proven — but because almost nothing is fully proven yet.
It feels like watching the earliest draft of a system that could redefine how AI value moves across the internet.
Or it could become another ambitious experiment that arrived before the market was truly ready.
Right now, nobody knows.
But one thing feels undeniable:
Projects like OpenLedger are forcing a completely new conversation into the AI industry.
Not just how intelligent AI can become...
But who captures the economic value generated by intelligence itself.
And maybe that’s the real story here.
Not the models.
Not the hype.
Not even the infrastructure.
Maybe the future of AI will ultimately depend on three things only:
Data ownership. Attribution accuracy. And sustainable value distribution.
Everything else may simply evolve around those foundations.
And that uncertainty is exactly what makes this space so compelling.
Because we are still standing at a point where the future could move in multiple directions at once.
Maybe OpenLedger becomes a core layer of the next AI economy.
Or maybe years later, we simply remember it as one of the earliest attempts to solve a problem the world had not fully understood yet.
For now, all we can really do is watch carefully.
Because something important is definitely beginning here.
