@OpenLedger I think I was looking at OpenLedger from the wrong direction for too long. At first, I treated it as another AI infrastructure idea built around better incentives, cleaner attribution, stronger coordination, and fairer data ownership. Those things are still important, and they are clearly part of the story. But the more I sit with it, the more one smaller thought keeps becoming heavier in my mind. Maybe OpenLedger is not only about rewarding contribution. Maybe it is about making certain types of knowledge more valuable in a world where intelligence itself becomes easier to access.
For a long time, I assumed AI would make specialized knowledge less valuable. It felt logical. If intelligence becomes abundant, if models can answer almost anything, if reasoning becomes available everywhere, then why would expertise still carry a premium? But now I am not so sure. The more I think about attribution, verifiable contribution, and systems that can track where knowledge actually came from, the more it feels like the opposite may happen. Not because intelligence will become rare, but because real context will remain rare. And that difference matters more than it first seems.
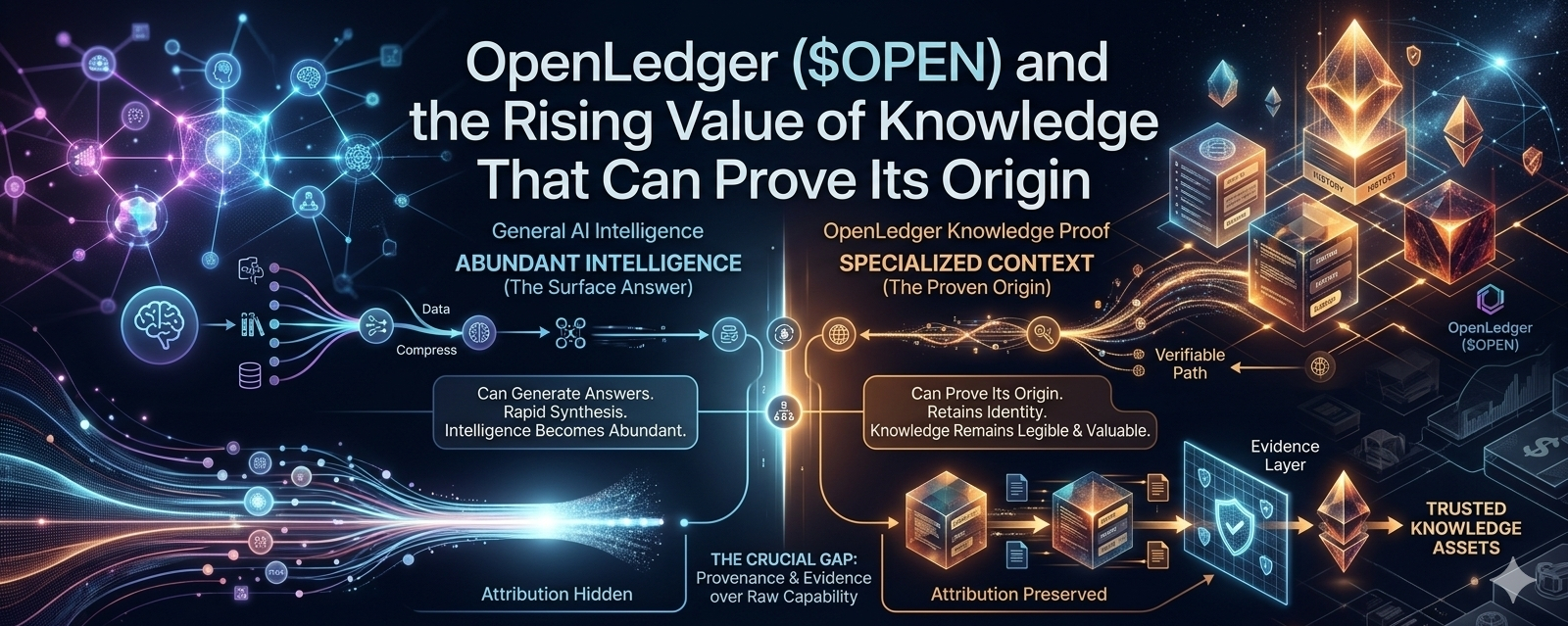
Most AI conversations still revolve around capability. Bigger models, better reasoning, stronger performance, more advanced outputs. The hidden assumption is that intelligence is the main bottleneck. But OpenLedger keeps pulling attention toward something deeper. What if the real bottleneck is not whether a system can think, but whether it can show where useful knowledge came from, why that knowledge exists, and whether it can be trusted enough to influence downstream decisions?
A model can produce an answer. That part is already becoming normal. But by the time an answer appears, so much has already been compressed and hidden. The training data is gone from view. The selection process is gone. The quality of the source is gone. The path that shaped the output often disappears before the output reaches the user. What remains is the response. What disappears is the history behind it. And that is where the real problem starts for me.
Downstream systems do not always consume history. They consume visible outputs. A person reads the answer. An AI agent follows the recommendation. An app uses the result. A ranking system measures relevance. A creator platform scores influence. But none of them necessarily know the invisible conditions that produced that output. They only see what survived into visibility. They do not always see what was true before visibility.
That is why OpenLedger feels more interesting when viewed as an evidence layer, not just an intelligence layer. Imagine two models with similar reasoning ability, similar performance, and similar outputs. One can prove where important knowledge came from, and the other cannot. Which one becomes more valuable? A few years ago, I probably would have chosen the smarter model. Now I hesitate, because intelligence without legibility creates a difficult problem. A system may know something, but can it prove why that knowledge deserves to be trusted?
Those are not the same thing. Knowing something and proving why it should matter are two different layers. And in an AI economy, that gap may become expensive. General intelligence can scale across many domains. It spreads horizontally. It becomes broader, cheaper, and more accessible. But specialized knowledge works differently. It often lives inside narrow contexts, specific industries, unusual datasets, regional behavior, supply chains, medical edge cases, technical processes, or tiny pockets of experience that look small until a valuable decision depends on them.
The internet rewarded distribution of information. AI is rewarding synthesis of information. But OpenLedger makes me wonder whether the next layer rewards the origin of information. Not every piece of knowledge will matter equally. The valuable knowledge may be the knowledge that is specific, traceable, and still attached to evidence after passing through multiple layers of AI compression. What survives the journey? What keeps its identity? What remains visible enough to count? Those questions feel more important now than they did before.
I notice the same pattern in creator ecosystems too. Thousands of people can talk about the same topic. Thousands can generate similar summaries. Surface-level intelligence becomes easy to reproduce. But some perspectives still stand out. Not always because they are smarter, but because they come from a specific observation, a rare dataset, a lived experience, or an interpretation that others cannot easily copy. That is where specialized context survives while general intelligence becomes more interchangeable.
This is the uncomfortable part. We often describe AI as something that commoditizes expertise, and maybe part of that is true. Some forms of expertise will become easier to imitate. Some knowledge will become cheaper to access. But verified context may become more valuable precisely because intelligence becomes abundant. The more capable models become, the more pressure shifts toward provenance, evidence, attestation, and knowing what entered the system before the answer appeared.
That is the design question inside OpenLedger that keeps holding my attention. On the surface, attribution can sound like a simple administrative issue. Who contributed what? Who should be rewarded? Which data was used? But downstream, those questions quietly reshape how value moves through the entire system. Who gets recognized? Which knowledge survives? Which contribution remains visible? Which expertise becomes eligible for compensation? Which source disappears during compression and never receives credit at all?
These are not small questions. They are infrastructure questions. They may look boring at first, but they touch everything once AI systems begin attaching consequence to knowledge. The truth of the knowledge may not change, but its economic weight can change completely. Once a system can verify where knowledge came from and preserve its connection to value creation, specialized knowledge starts behaving less like background material and more like a financial asset inside the AI economy.
That is where my original assumption begins to break. I used to think intelligence and knowledge would become more or less the same thing as AI improved. Now I see a separation forming. One system can generate answers. Another system can decide which knowledge survives long enough to matter. They sound similar, but they are not identical. The answer is what appears on the surface. The attribution layer is what decides whether the invisible contribution behind that answer can still be seen, trusted, and rewarded.
Maybe the most valuable thing in an AI economy will not be intelligence that can generate everything. Maybe it will be specialized knowledge that can prove it existed before the answer arrived. And maybe that is what makes OpenLedger worth paying attention to. It is not only asking how AI systems produce outputs. It is asking what gets lost before those outputs become visible, who loses value in that process, and whether the missing parts can finally be brought back into the economic picture.