I've been seeing @OpenLedger pop up in a few places lately. AI infrastructure, data provenance, decentralized training — the usual pitch that sounds impressive until you actually sit with it for a minute.
So I started reading. Not the whitepaper. Just… how people are talking about it.
And something felt off.
Most of the conversation around OpenLedger is framing it as a "secure AI training platform." Like the main feature is that it protects data. Keeps things private. Builds trust into the pipeline.
And sure — that's part of it.
But here's what clicked for me, and I haven't been able to shake it since:
The real problem OpenLedger is solving isn't data security. It's data legitimacy.
Those sound similar. They're not.
Security is about keeping bad actors out. Legitimacy is about proving the data was never contaminated in the first place — to the model, to the users of the model, and frankly, to anyone who ends up making decisions based on what that model outputs.
Right now, most AI training pipelines are basically a black box with a padlock on the outside. You're told the data is clean. You're told the sources are verified. You kind of just… trust it. And for a while, that was fine because no one was really asking hard questions.
But that's changing. Regulatory pressure, model audits, enterprise procurement requirements — people are starting to ask where did this data come from in a way they weren't two years ago.
And suddenly, "we secured the pipeline" isn't a sufficient answer anymore. The question is: can you prove the provenance?
That's where the on-chain piece actually matters — not as a crypto gimmick, but as an audit mechanism. If every dataset contribution, every training run, every model update has a verifiable chain of custody, you're not just protecting the training process. You're making the entire thing defensible.
That's a meaningfully different product than "secure AI infrastructure."
I thought OpenLedger was positioning itself for the data privacy wave. But actually — and this took me a minute to see — it might be positioning for the AI accountability wave, which is slightly downstream and probably larger.
Here's the part that bothers me though.
The accountability use case only works if the people buying AI infrastructure actually want accountability. And a lot of them... don't. Not really. They want to say they have it. There's a difference.
Enterprise AI adoption right now has a weird dynamic where the marketing layer demands explainability and the engineering layer quietly deprioritizes it. So you end up with systems that are "auditable in theory" and never actually audited.
If OpenLedger's value is entirely downstream of whether clients use the audit trail — not just deploy it — that's a real adoption risk. You can build the most elegant provenance system in the world and watch it sit unused because nobody's quarterly targets include "actually trace where the training data came from."
I'm not fully convinced that problem is solved yet. The infrastructure can be there. The incentive has to follow.
There's also the scale question I keep coming back to. Verified, on-chain provenance adds friction. Not a lot, but some. At small scale — research institutions, boutique AI labs — that friction is probably worth it. At hyperscaler scale, where you're talking about billions of data points moving through pipelines continuously... I don't know. The economics of verification start to look different.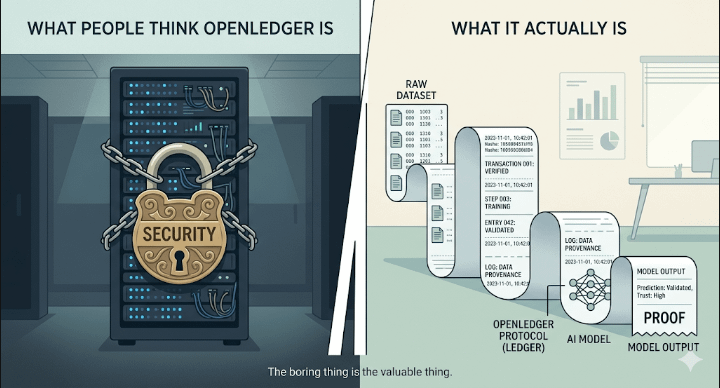
Maybe that's where it gets partitioned — legitimacy infrastructure for high-stakes AI, looser pipelines for everything else. That actually makes sense as a market structure. But it means OpenLedger is more niche than the pitch implies, at least for now.
Anyway. The charts aren't doing much. I'll probably keep watching how the accountability conversation develops — it's moving faster than I expected six months ago, mostly because regulators are now hiring people who actually understand what a training pipeline is.