
I'm waiting, watching, looking closely at how everyone in AI keeps pushing toward the same thing — bigger models, more compute, longer context windows, faster outputs. Every week there’s another breakthrough, another benchmark, another race to build something “smarter.” But honestly, the more I observe it, the more I feel like the real issue is sitting somewhere else entirely.
I keep thinking about the data.
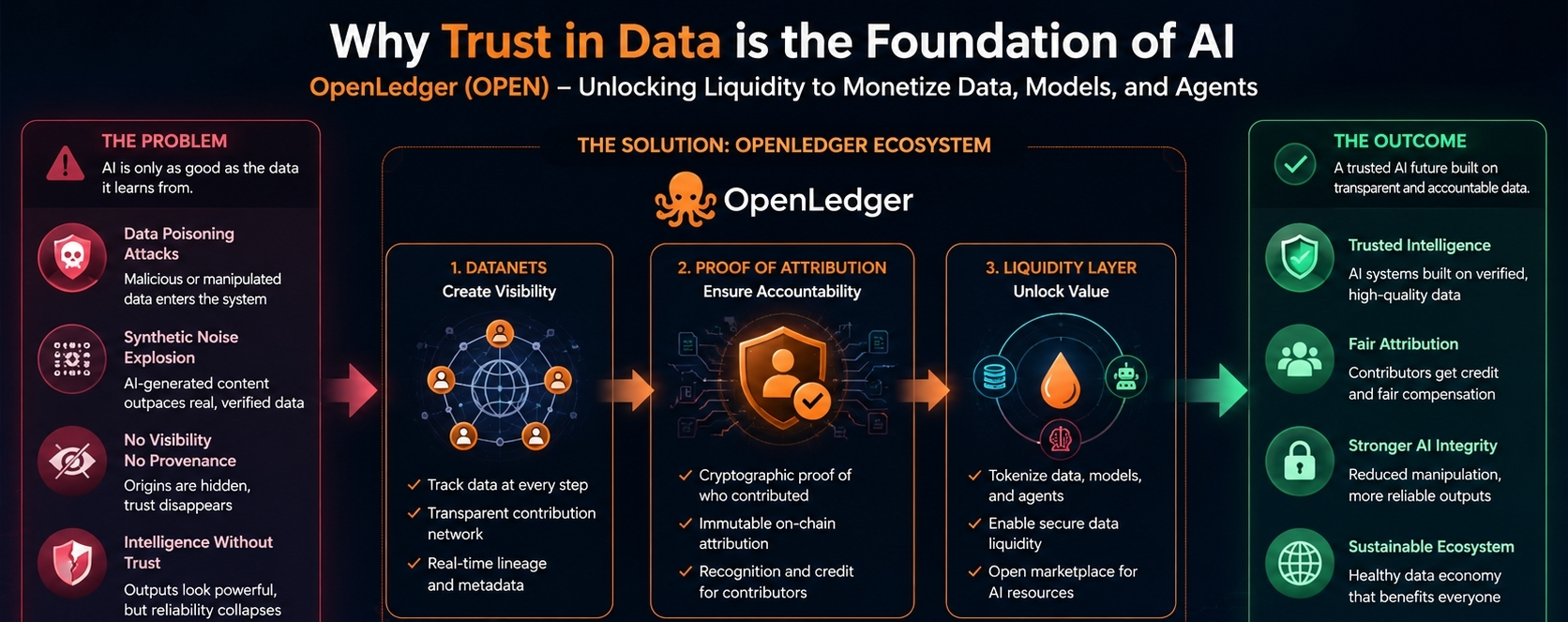
Not just the amount of it, but whether any of it can still be trusted in the long run. AI today feels like it’s growing at a speed where nobody has time to question what’s actually feeding these systems anymore. We celebrate intelligence, but rarely stop to ask if the foundation underneath it is slowly getting corrupted.
And that thought keeps staying in my head.
Because once poisoned or synthetic information starts circulating at scale, AI doesn’t really know the difference. It learns from whatever enters the system. Good data, bad data, manipulated data — it all becomes part of the model eventually. That’s what makes this feel bigger than just another competition between companies trying to release the strongest AI.
Intelligence without trust feels fragile.
That’s probably why OpenLedger caught my attention in the first place. Not because it’s screaming for attention like most projects do, but because it seems focused on something people still underestimate: accountability around data itself.
The idea of Datanets honestly makes more sense to me the longer I think about where AI is heading. Visibility matters. Knowing where information comes from matters. Attribution matters. Especially now, when the internet is slowly filling with AI-generated content layered on top of more AI-generated content.
At some point, the line between real and synthetic starts disappearing.
And when that happens, systems built purely around scale could run into a much bigger problem than performance. They could lose credibility entirely. That’s the part I don’t think enough people are paying attention to yet.
Proof of Attribution is another thing I keep coming back to. The concept feels simple on the surface, but the deeper you think about it, the more important it becomes. If AI is going to shape how people learn, search, build, and communicate, then contribution and verification can’t stay invisible forever.
Someone has to protect the integrity of the information layer.
That’s why OpenLedger feels different to me. It doesn’t look like it’s only trying to build “more AI.” It feels more like it’s trying to build infrastructure where trust can still exist inside an AI-driven world.
And honestly, that might end up mattering more than raw intelligence itself.
Because eventually, everyone will have powerful models.
But trusted ecosystems? Those will be much harder to build.
Maybe that’s what $OPEN is really aiming for in the end — not just smarter systems, but a future where knowledge still has accountability attached to it.