昨晚我特意花了一個小時,試著走一遍 @OpenLedger 的 ModelFactory 操作流程。不是真的要建模型,而是想親身確認一件事:它說的「普通人也能用」,到底門檻有多低。
走完一遍之後我的第一個想法是:比我預期的更可用,但也有幾個讓我停下來想清楚的地方。
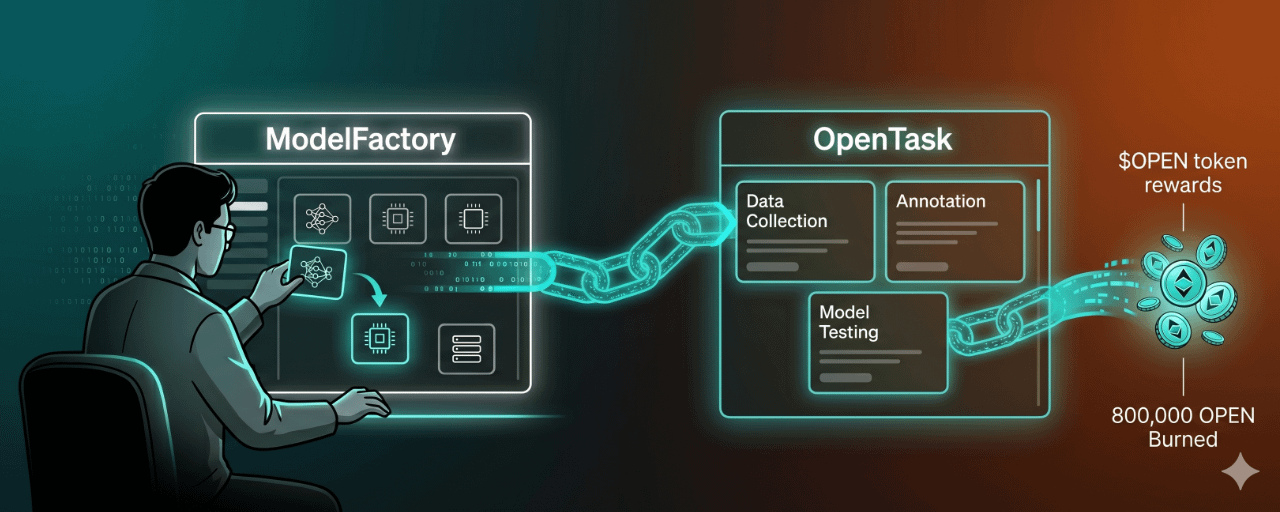
先說 ModelFactory 是什麼。
ModelFactory 是 OpenLedger 的無代碼模型工廠,設計目標是讓不懂 Python、不懂調參的人,也能透過拖拽組件的方式建立一個 AI 模型。官方公佈的測試網數據顯示,目前已有超過 2 萬個 AI 模型被建立,這個數字說明至少在門檻上,它確實讓更多人能夠進場。
但 ModelFactory 本身不是終點。它真正的意義,是和 OpenTask 任務市場的結合。
OpenTask 是 OpenLedger 生態裡的任務市場。項目方或開發者在 OpenTask 上發布數據採集、標註、模型測試等需求,社區成員可以接單完成任務。每一個完成的任務,都會通過 PoA 歸因機制記錄在鏈上,確認你對模型的貢獻程度。
這個貢獻記錄不是一次性的。當這個模型之後被其他人或企業調用時,$OPEN 的分潤會根據鏈上的歸因記錄,自動分配給當初貢獻數據的你。
⚡ 這個設計的聰明之處在於,它試圖把「一次貢獻、持續收益」這件事放進一個有鏈上記錄的系統裡。過去你可能在某個平台貢獻了標註數據,平台拿走所有價值,你什麼都沒拿到。OpenLedger 試圖讓這個過程透明化,讓貢獻可以被追蹤、被定價、被分潤。
三種普通人可以參與的方式:
第一,數據貢獻者:根據自己的專業領域,參與對應的 Datanet 標註任務。醫療背景可以標註醫療影像,金融背景可以維護加密治理數據集。
第二,模型開發者:用 ModelFactory 建立一個有特定用途的小型專用模型,部署上鏈後,每次被調用都能獲得分潤。
第三,任務接單者:在 OpenTask 接發布的任務,完成數據採集或測試需求,按完成品質拿取 OPEN代幣報酬。
「這是第一次有一個平台試圖讓普通人在 AI 產業裡,從旁觀者變成受益者,而且把整個過程放在鏈上讓人看得到。」
但在研究過程中,有一個讓我心裡沒底的地方:什麼叫做「高質量貢獻」,以及平台怎麼防止大量低質量任務刷數據,目前我看到的說明並不夠具體。這是 ModelFactory + OpenTask 能不能長期運轉的核心問題,也是我持續觀察的指標。