Der wahre Wert von $OPEN könnte nicht die Datenspeicherung sein. Es könnte die Attribution sein. Lass mich etwas zugeben, das sich ein wenig unangenehm anfühlt. Je mehr sich KI verbessert, desto weniger sicher bin ich, wer tatsächlich für die Schaffung ihres Wertes belohnt wird. Die meisten Gespräche über KI konzentrieren sich auf die Skalierung. Größere Modelle. Mehr Daten. Mehr Rechenleistung. Schnellere Systeme. Jedes Projekt scheint zu konkurrieren, um zu beweisen, dass es mehr Informationen verarbeiten kann als das letzte. Aber in letzter Zeit habe ich über eine andere Frage nachgedacht. Was passiert, nachdem die Daten verwendet wurden? Genauer gesagt, wie wissen wir, wer zum Wert eines KI-Systems beigetragen hat? Das ist der Teil, der meine Aufmerksamkeit immer wieder auf sich zieht. Daten sind nicht mehr selten. Jeden Tag werden enorme Mengen an Informationen im Internet generiert. Die Speicherung wird günstiger. Die Sammlung wird einfacher. Neue Datensätze erscheinen ständig. Was immer noch schwierig erscheint, ist es, den Wert zu seiner Quelle zurückzuverfolgen. Wenn ein KI-Modell ein nützliches Ergebnis produziert, wer hat das möglich gemacht? War es die Person, die die Daten beigetragen hat? Der Forscher, der das Modell verbessert hat? Die Community, die Jahre damit verbracht hat, Wissen zu einem bestimmten Thema aufzubauen? Theoretisch haben alle eine Rolle gespielt. Praktisch wird die Verbindung oft schwer zu erkennen. Ich habe etwas Ähnliches im Krypto-Bereich gesehen. Viele der Personen, die Wert schaffen, agieren im Hintergrund. Infrastrukturprovider, Validatoren, Liquiditätsanbieter und Mitwirkende helfen, gesamte Ökosysteme am Laufen zu halten, dennoch bemerken die meisten Nutzer sie selten. Der Wert existiert. Die Sichtbarkeit nicht. KI scheint sich in die gleiche Richtung zu bewegen. Jeder spricht über Modelle, weil Modelle das sind, womit die Menschen interagieren. Aber hinter jeder KI-Antwort steht eine lange Kette von Mitwirkenden, deren Einfluss schwerer nachverfolgt werden kann, je größer die Systeme werden. Ein vor Monaten hochgeladener Datensatz kann immer noch die Ergebnisse von heute beeinflussen. Eine Modellverbesserung, die von einem Mitwirkenden vorgenommen wurde, kann Tausenden zukünftigen Nutzern zugutekommen. Wert wird im gesamten Netzwerk geschaffen, aber der Pfad, der Beitrag und Belohnung verbindet, wird oft unsichtbar. Deshalb hat OpenLedger meine Aufmerksamkeit erregt. Zuerst nahm ich an, die Hauptidee sei der Datenbesitz. Besitze deine Daten. Kontrolliere deine Daten. Monetarisiere deine Daten. Das sind wichtige Konzepte. Aber je mehr ich darüber nachdachte, desto mehr hatte ich das Gefühl, dass die größere Herausforderung die Attribution sein könnte. Besitz beantwortet eine einfache Frage: "Wer hat es?" Attribution versucht, eine schwierigere zu beantworten: "Wer hat geholfen, den Wert zu schaffen?" Dieser Unterschied wird immer wichtiger, je mehr KI-Ökosysteme wachsen. Wenn Mitwirkende nicht sehen können, wie ihre Arbeit mit Ergebnissen verbunden ist, beginnen die Anreize, sich von der tatsächlichen Wertschöpfung zu entfernen. Und wenn die Anreize brechen, kämpfen Ökosysteme schließlich. Hier fühlt sich der Fokus von OpenLedger auf Attribution interessant an. Das Ziel ist nicht einfach, Informationen zu speichern. Es geht darum, ein System zu schaffen, in dem Beiträge mit dem Wert verbunden bleiben, den sie helfen zu generieren. Natürlich denke ich nicht, dass irgendein Attribution-System perfekt ist. Große Netzwerke sind kompliziert. Teilnehmer optimieren für Belohnungen. Metriken können manipuliert werden. Das Verhalten in der realen Welt offenbart oft Schwächen, die auf dem Papier unsichtbar erscheinen. Das gilt für Krypto. Es gilt für KI. Und es wird wahrscheinlich für beide so bleiben. Daher betrachte ich Attribution nicht als gelöstes Problem. Ich betrachte es als ein wichtiges. Viele Menschen konzentrieren sich darauf, intelligentere KI zu entwickeln. Vielleicht sollten wir auch Zeit damit verbringen, KI-Ökosysteme zu bauen, die die Wertschöpfung leichter verständlich machen. Denn wenn KI schließlich ein Netzwerk wird, das von unzähligen Mitwirkenden betrieben wird, hört Attribution auf, ein Feature zu sein. Es wird zur Infrastruktur. Und Infrastruktur ist normalerweise am wichtigsten, wenn niemand sie bemerkt. Ob OpenLedger letztendlich erfolgreich ist, kann nur die Zeit beantworten. Aber ich komme immer wieder zu derselben Frage zurück: Wenn Daten im Überfluss vorhanden sind und Modelle im Überfluss vorhanden sind, was bleibt dann knapp? Von meinem Standpunkt aus könnte die Antwort nicht die Speicherung sein. Es könnte die Fähigkeit sein, zu verstehen, woher der Wert tatsächlich kommt. Und das ist ein Problem, das es wert ist, beachtet zu werden.
Artikel
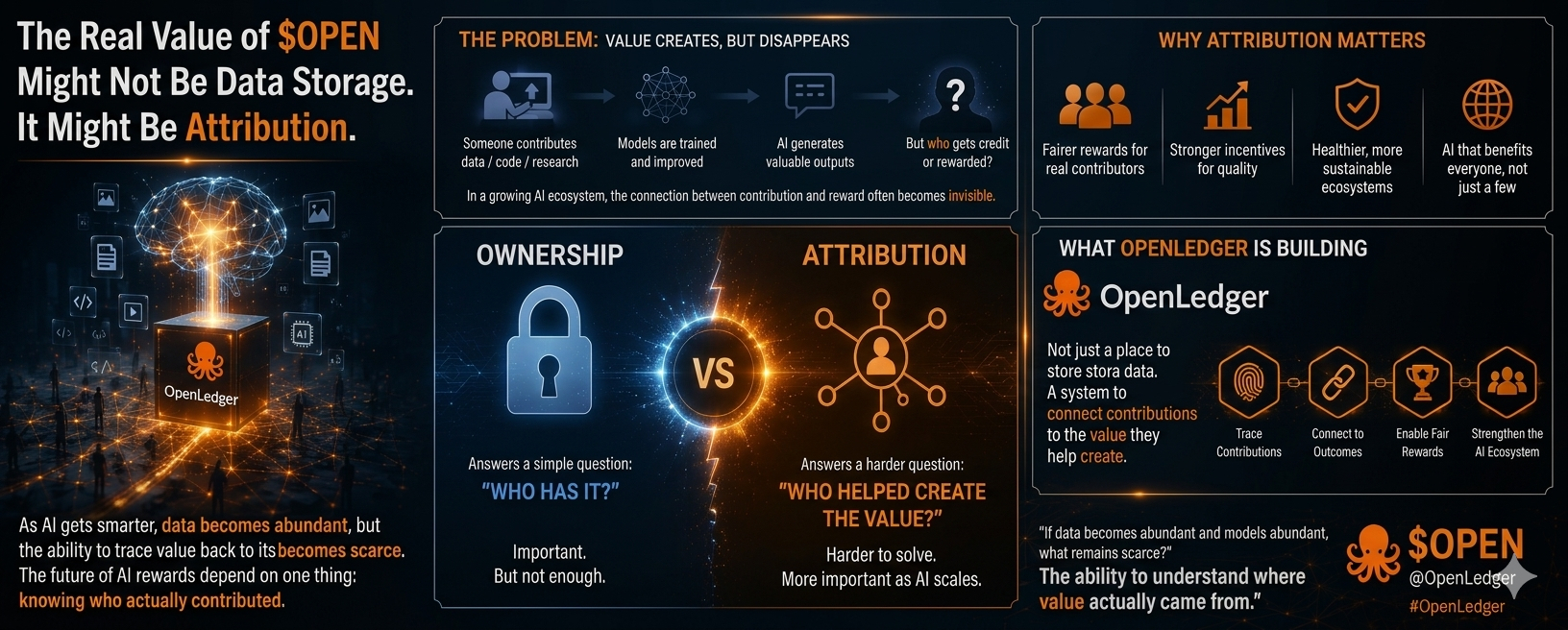
Der nächste Engpass der KI ist nicht Daten. Es ist die Attribution.
--
Haftungsausschluss: Enthält Meinungen von Drittanbietern. Keine Beratung. Binance Ai wird ohne Gewähr bereitgestellt. Siehe AGB.