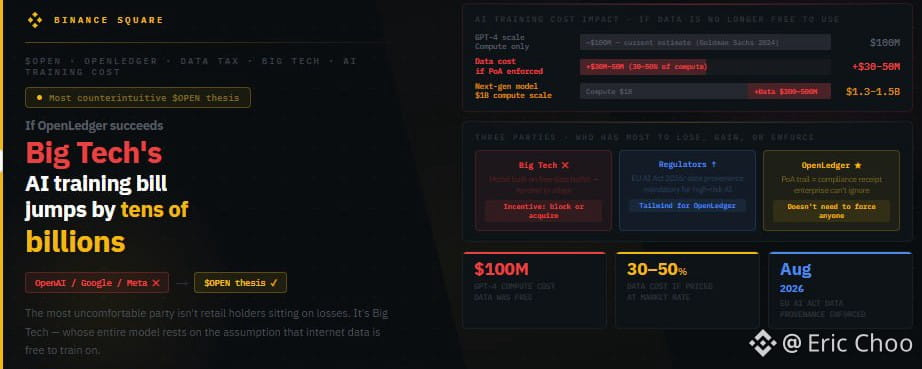
Ich habe angefangen, darüber nachzudenken, nachdem ich eine Zahl im Bericht von Goldman Sachs für 2024 gelesen habe: Die geschätzten Kosten, um GPT-4 zu trainieren, liegen bei etwa 100 Millionen USD. Diese Zahl berücksichtigt nicht die Kosten für Daten, da die Daten kostenlos aus dem Internet bezogen werden. Wenn Daten nicht kostenlos wären, wie hoch wäre diese Zahl? Niemand weiß es genau, aber viele Schätzungen gehen davon aus, dass qualitativ hochwertige, kuratierte Daten 30 bis 50 % des Wertes des Trainings ausmachen könnten, wenn sie zum Marktpreis bewertet werden. Bei GPT-4 wären das 30 bis 50 Millionen USD nur für einen Trainingslauf. Bei dem nächsten Modell könnten die Kosten 1 Milliarde USD betragen, wobei die Datenkosten zwischen 300 und 500 Millionen USD liegen würden.
Das ist, was @OpenLedger und $OPEN versuchen, die Infrastruktur dafür aufzubauen: eine Welt, in der jeder Datensatz einen Preis hat, jede Inferenz eine Lizenzspur hat, und KI-Labore nicht mehr mit dem Geschäftsmodell "kostenloses Datenbuffet" weitermachen können, wie sie es tun. Nicht durch Gesetze, nicht durch Advocacy, sondern durch eine Protokoll-Ebene on-chain, die, wenn genügend Akzeptanz erreicht wird, zum unverzichtbaren Standard wird.
Ich möchte etwas direkt ansprechen, was beide Research-Dokumente, die ich gelesen habe, angedeutet haben, aber nicht direkt gesagt haben. Das Spotify-Modell ist das nächste Beispiel für das, was OpenLedger anstrebt. Vor Spotify erhielten kleine Musiker nichts von illegalen Downloads. Nach Spotify erhalten sie Mikro-Lizenzgebühren, jedes Mal, wenn ein Lied gestreamt wird, auch wenn es ein kleiner Betrag ist. Wichtiger ist, dass dieser Standard die gesamte Funktionsweise der Musikindustrie verändert hat. Nicht weil Spotify so nett ist, sondern weil sie eine Infrastruktur geschaffen haben, die groß genug ist, um Lizenzgebühren in großem Maßstab durchzusetzen, auf eine Weise, die die Musikindustrie nicht ignorieren kann.
Das Problem ist, dass OpenLedger Big Tech nicht zu etwas zwingen kann, zumindest nicht im direkten Sinne. Google kann weiterhin kostenlos auf Common Crawl trainieren, selbst wenn OpenLedger existiert. Niemand kann das durch einen Smart Contract verhindern. Das ist die größte Schwäche der These, und ich denke, es ist wichtig, das zu sagen, anstatt nur einseitig optimistische Inhalte zu schreiben.
Aber so kann OpenLedger Veränderungen schaffen, nicht durch direkte Durchsetzung, sondern durch Alternativen: Wenn Modelle, die auf OpenLedger DataNet mit verifizierten, kuratierten, domänenspezifischen Daten trainiert werden, konsequent besser abschneiden als Modelle, die mit unübersichtlichen Internetdaten in regulierten Bereichen wie Gesundheitswesen oder legaler KI trainiert werden, werden Unternehmenskäufer Modelle von OpenLedger bevorzugen. Nicht weil sie sich um Fairness kümmern, sondern weil der EU AI Act und andere regulatorische Rahmenbedingungen beginnen, Herkunftsdokumentationen zu verlangen. Ein Krankenhaus, das ein KI-Diagnosetool kauft, muss dem Regulierer nachweisen, dass die Trainingsdaten dieses Tools die Qualitätsstandards erfüllen. Die PoA-Spur von OpenLedger bietet genau das. Natürlich, ohne dass jemand gezwungen werden muss.
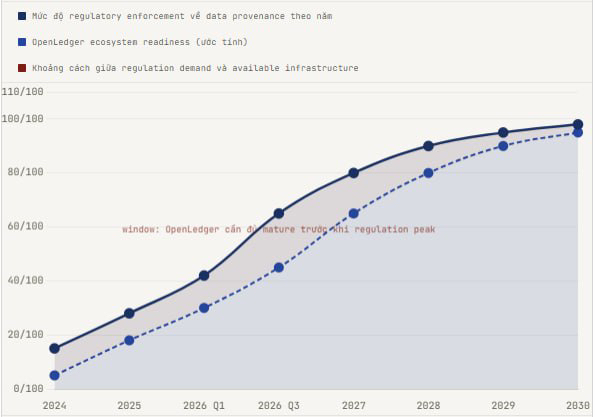
Als ich die Investor-Liste von OpenLedger durchgesehen habe, insbesondere Balaji Srinivasan, der viele große technologische Veränderungen vorhergesagt hat, gibt mir das zusätzliches Vertrauen, nicht weil Balaji immer recht hat, sondern weil er oft nur wettet, wenn er einen klaren regulatorischen Vorteil sieht. Der EU AI Act, die US AI Executive Order und das AI-Governance-Framework von Singapur drängen alle in die Richtung, dass Datenherkunft verpflichtend ist. OpenLedger muss Big Tech nicht überzeugen. Sie müssen nur warten, bis die Regulierungsbehörden das für sie tun.
 Was mich an dieser langfristigen These glauben lässt, sind nicht Hype oder FOMO. Es ist einfache wirtschaftliche Logik. In 20 Jahren Internet wurde alles, was kostenlos erschien, letztendlich in den Preis eingepreist. Kostenlose E-Mails, dann wurden Spam-Filter und E-Mail-Marketing zu einer milliardenschweren Industrie. Kostenlose Suche, dann wurde SEO und Google Ads zu einem großen Teil des Internet-BIP. Kostenlose soziale Medien, dann wurde die Aufmerksamkeitseconomie und Datenbrokerage zum Geschäftsmodell von Meta und Twitter. Kostenlose Daten-KI, was wird das sein? OpenLedger wettet auf die Antwort: Attributionseconomie, in der jede Daten-Spur einen Preis on-chain hat.
Was mich an dieser langfristigen These glauben lässt, sind nicht Hype oder FOMO. Es ist einfache wirtschaftliche Logik. In 20 Jahren Internet wurde alles, was kostenlos erschien, letztendlich in den Preis eingepreist. Kostenlose E-Mails, dann wurden Spam-Filter und E-Mail-Marketing zu einer milliardenschweren Industrie. Kostenlose Suche, dann wurde SEO und Google Ads zu einem großen Teil des Internet-BIP. Kostenlose soziale Medien, dann wurde die Aufmerksamkeitseconomie und Datenbrokerage zum Geschäftsmodell von Meta und Twitter. Kostenlose Daten-KI, was wird das sein? OpenLedger wettet auf die Antwort: Attributionseconomie, in der jede Daten-Spur einen Preis on-chain hat.
Ich kenne den genauen Zeitrahmen nicht. Vielleicht 3 Jahre. Vielleicht 7 Jahre. Aber während alle $OPEN verkaufen, weil es um 91% gefallen ist, sehe ich das, was ich kaufe, nicht als einen verlorenen Token. Das ist eine Wette, dass KI für Daten bezahlen muss, so wie Netflix für Inhalte zahlen muss, und OpenLedger baut die Infrastruktur auf, um dieses Geld zu sammeln.
Wenn der EU AI Act tatsächlich die Anforderungen an die Herkunftsdokumentation für hochriskante KI-Systeme ab 2026 durchsetzt und OpenLedger die einzige Infrastruktur mit einer on-chain PoA-Spur ist, die granular genug ist, um diese Anforderungen zu erfüllen, glauben Sie, dass Big Tech sich entscheiden wird, OpenLedger in ihren Pipeline zu integrieren, oder werden sie ihre eigenen Alternativen entwickeln, um die Abhängigkeit von einem on-chain-Protokoll zu vermeiden, das sie nicht kontrollieren?