Autor: 0xjacobzhao | https://linktr.ee/0xjacobzhao
Dieser unabhängige Forschungsbericht wird von IOSG Ventures unterstützt. Der Forschungs- und Schreibprozess wurde von Sam Lehman (Pantera Capital) und seinem Bericht über verstärktes Lernen inspiriert. Besonderer Dank gilt Ben Fielding (Gensyn.ai), Gao Yuan (Gradient), Samuel Dare & Erfan Miahi (Covenant AI), Shashank Yadav (Fraction AI) und Chao Wang für ihre wertvollen Vorschläge zu diesem Artikel. Dieser Artikel strebt nach objektivem und genauem Inhalt, einige Ansichten beinhalten subjektive Urteile, was unvermeidlich zu Verzerrungen führen kann. Wir bitten die Leser um Verständnis.
Künstliche Intelligenz entwickelt sich von einem auf "Modellanpassung" basierenden statistischen Lernen hin zu einem Fähigkeitsystem, das auf "strukturiertem Schlussfolgern" basiert. Die Bedeutung des Post-Trainings steigt schnell an. Das Auftreten von DeepSeek-R1 markiert einen paradigmatischen Umschwung des verstärkenden Lernens im Zeitalter großer Modelle, und es entsteht ein Branchenkonsens: Die Vorab-Training schafft die Grundlage für die allgemeine Fähigkeit des Modells, während verstärktes Lernen nicht mehr nur ein Werkzeug zur Wertausrichtung ist, sondern sich als systematische Verbesserung der Qualität der Schlussfolgerungsketten und der komplexen Entscheidungsfähigkeit erwiesen hat und sich schrittweise zu einem technischen Weg entwickelt, der das Intelligenzniveau kontinuierlich erhöht.
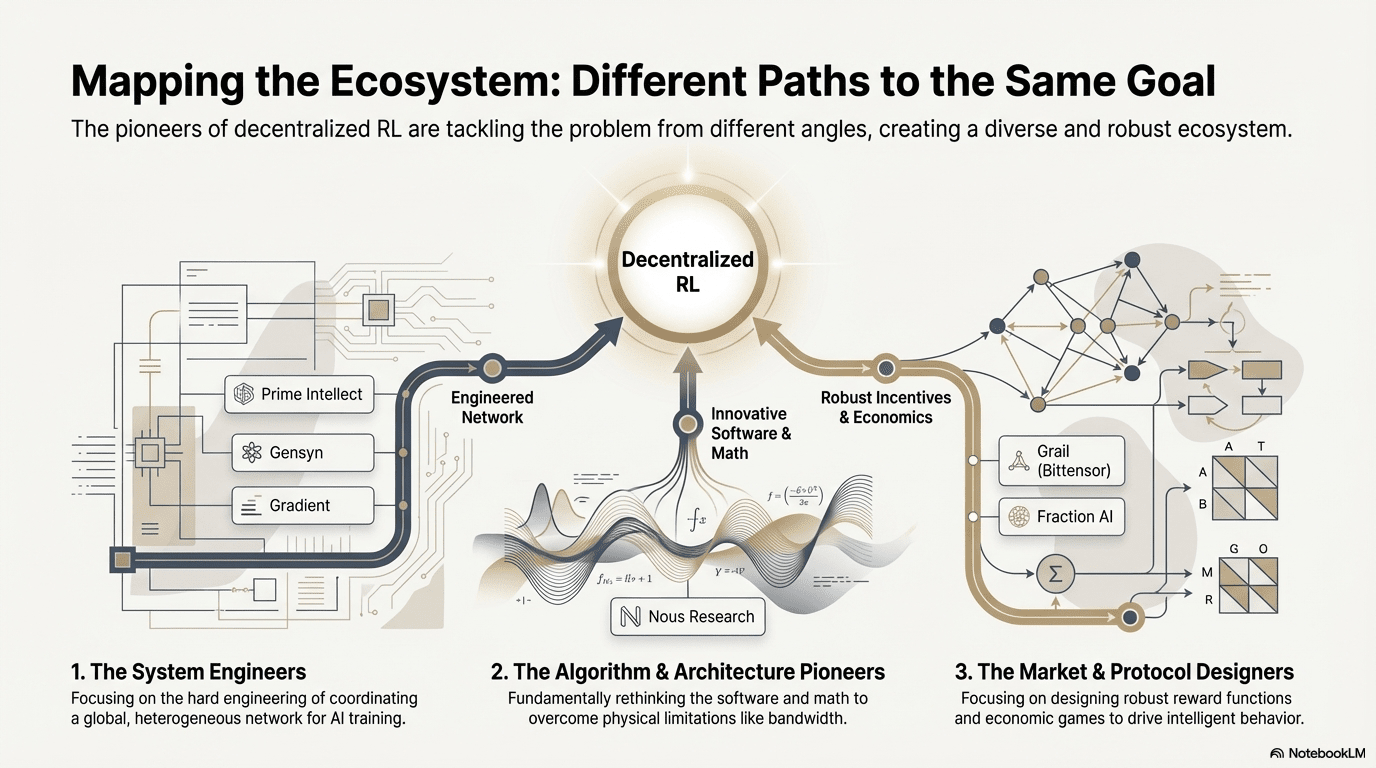
In der Zwischenzeit rekonstruiert Web3 durch dezentrale Rechenleistungsnetzwerke und kryptografische Anreizsysteme die Produktionsverhältnisse von KI, während die strukturellen Anforderungen des verstärkten Lernens an Rollout-Sampling, Belohnungssignale und verifizierbares Training auf natürliche Weise mit der Rechenleistung, der Anreizverteilung und der verifizierbaren Ausführung von Blockchains übereinstimmen. Dieser Forschungsbericht wird die AI-Trainingsparadigmen und die Prinzipien der verstärkten Lerntechnologie systematisch aufdröseln, die strukturellen Vorteile von verstärktem Lernen × Web3 darlegen und Analysen zu Projekten wie Prime Intellect, Gensyn, Nous Research, Gradient, Grail und Fraction AI bereitstellen.
1. Die drei Phasen des KI-Trainings: Vortraining, Anweisungsfeinabstimmung und Nachtrainingsausrichtung
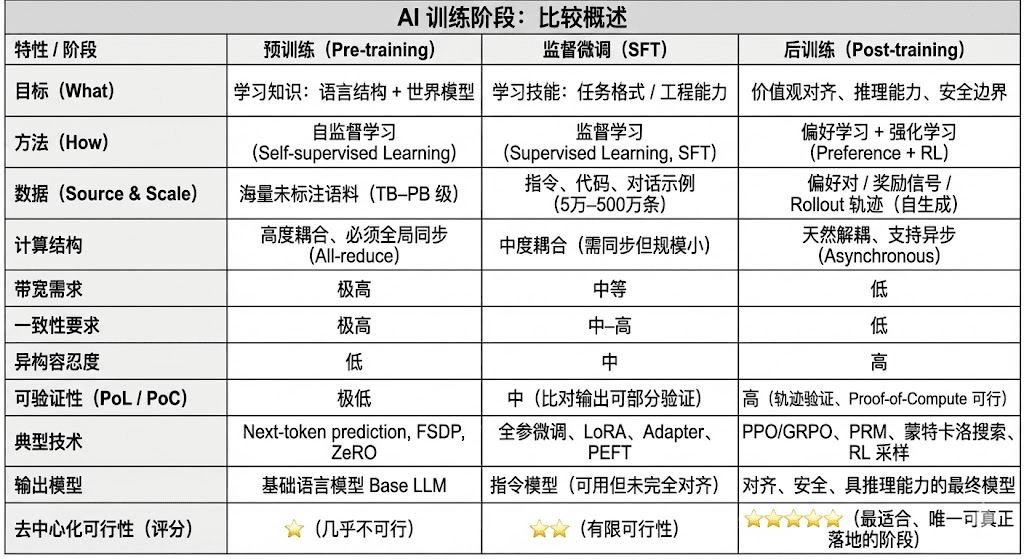
Moderne große Sprachmodelle (LLM) durchlaufen in ihrem gesamten Lebenszyklus normalerweise drei Kernphasen: Vortraining (Pre-training), überwachte Feinabstimmung (SFT) und Nachtraining (Post-training/RL). Diese erfüllen jeweils die Funktionen „Bau eines Weltmodells – Injektion von Aufgabenfähigkeiten – Formung von Inferenz und Werten“; ihre rechnerischen Strukturen, Datenanforderungen und Verifizierungsanforderungen bestimmen das Maß an Dezentralisierung.
Vortraining (Pre-training) baut durch großflächiges selbstüberwachtes Lernen (Self-supervised Learning) die statistische Sprachstruktur und das multimodale Weltmodell des Modells auf und ist die Grundlage der LLM-Fähigkeiten. Diese Phase erfordert Training auf Billionen von Korpora in global synchroner Weise, abhängig von Tausenden bis Zehntausenden von H100-Homogenitätsclustern, wobei die Kosten bis zu 80–95 % ausmachen und extrem empfindlich gegenüber Bandbreite und Urheberrechten sind, weshalb sie in einem stark zentralisierten Umfeld abgeschlossen werden muss.
Feinabstimmung (Supervised Fine-tuning) wird verwendet, um Aufgabenfähigkeiten und Anweisungsformate zu injizieren, wobei die Datenmenge klein ist und die Kosten etwa 5–15 % ausmachen. Feinabstimmung kann sowohl als vollständiges Training als auch als parameter-effiziente Feinabstimmung (PEFT) durchgeführt werden, wobei LoRA, Q-LoRA und Adapter in der Industrie gängig sind. Es ist jedoch weiterhin erforderlich, Gradienten zu synchronisieren, was das dezentrale Potenzial einschränkt.
Nachtraining (Post-training) besteht aus mehreren iterativen Unterphasen, die die Inferenzfähigkeit des Modells, Werte und Sicherheitsgrenzen bestimmen. Seine Methoden umfassen sowohl verstärkte Lernsysteme (RLHF, RLAIF, GRPO) als auch nicht-RL-Präferenzoptimierungsmethoden (DPO) sowie Prozessbelohnungsmodelle (PRM). Diese Phase hat eine geringere Datenmenge und Kosten (5–10 %) und konzentriert sich hauptsächlich auf Rollouts und Strategieaktualisierungen; sie unterstützt natürlich asynchrone und verteilte Ausführungen, wobei Knoten nicht die vollständigen Gewichte besitzen müssen, und in Kombination mit verifizierbarer Berechnung und On-Chain-Anreizen kann ein offenes dezentrales Trainingsnetzwerk entstehen, was sie zur am besten geeigneten Trainingsphase für Web3 macht.
Zwei. Panorama der verstärkten Lerntechnologie: Architektur, Frameworks und Anwendungen
2.1 Struktur und Kernaspekte des verstärkten Lernens
Verstärktes Lernen (Reinforcement Learning, RL) treibt die selbstständige Verbesserung der Entscheidungsfähigkeit von Modellen durch „Umgebung Interaktion – Belohnungsfeedback – Strategieaktualisierung“ voran. Die Kernstruktur kann als Feedbackschleife betrachtet werden, die aus Zustand, Aktion, Belohnung und Strategie besteht. Ein vollständiges RL-System umfasst normalerweise drei Arten von Komponenten: Policy (Strategienetzwerk), Rollout (Erfahrungssampling) und Learner (Strategieaktualisierer). Strategie und Umgebung interagieren zur Generierung von Trajektorien, während der Learner die Strategie basierend auf dem Belohnungssignal aktualisiert, wodurch ein fortlaufender, sich ständig optimierender Lernprozess entsteht:
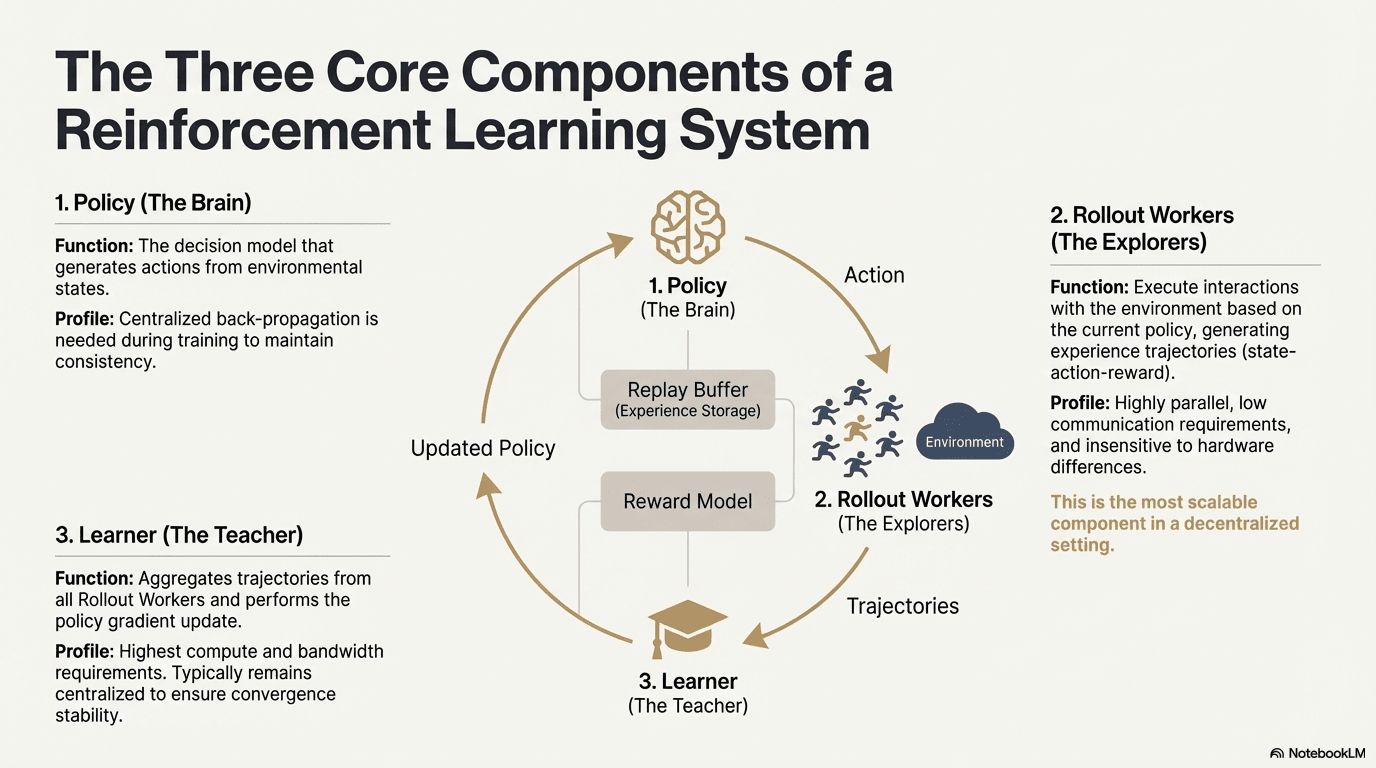
Strategienetzwerk (Policy): Generiert Aktionen aus dem Zustand der Umgebung und ist das Entscheidungszentrum des Systems. Während des Trainings muss eine zentrale Rückpropagation zur Aufrechterhaltung der Konsistenz erfolgen; bei der Inferenz kann es an verschiedene Knoten verteilt und parallel ausgeführt werden.
Erfahrungssampling (Rollout): Knoten interagieren mit der Umgebung gemäß der Strategie und generieren Trajektorien von Zustand – Aktion – Belohnung usw. Dieser Prozess ist hochgradig parallel, hat eine extrem niedrige Kommunikation und ist nicht empfindlich gegenüber Hardwareunterschieden, was ihn zur idealen Erweiterung für Dezentralisierung macht.
Lerner (Learner): Aggregiert alle Rollout-Trajektorien und führt die Aktualisierung der Strategiegene durch, ist das Modul mit den höchsten Anforderungen an Rechenleistung und Bandbreite, daher wird es häufig zentralisiert oder leicht zentralisiert bereitgestellt, um die Konvergenzstabilität zu gewährleisten.
2.2 Rahmen der Phasen des verstärkten Lernens (RLHF → RLAIF → PRM → GRPO)
Verstärktes Lernen kann typischerweise in fünf Phasen unterteilt werden, deren Gesamtprozess wie folgt beschrieben wird:
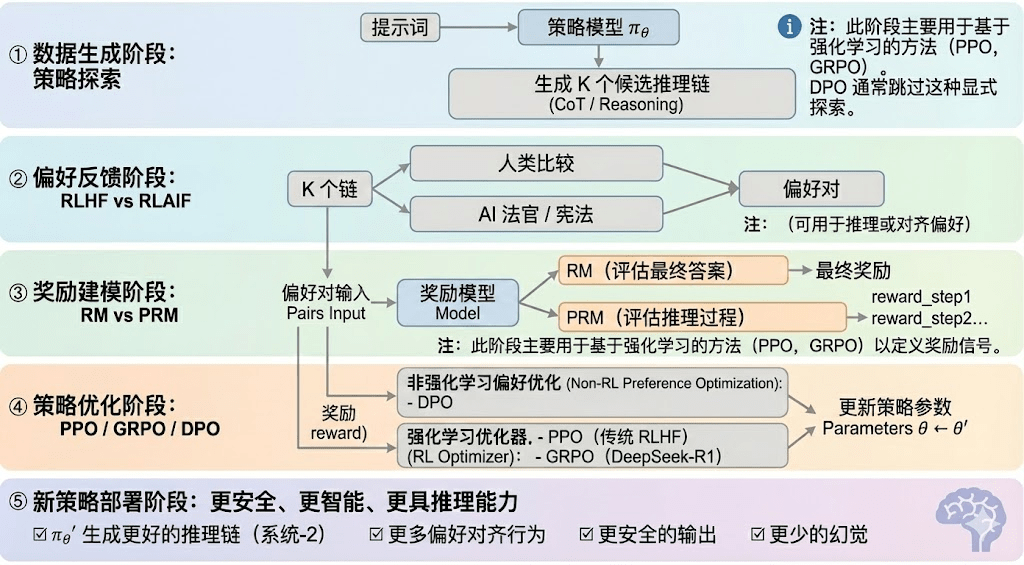
Datenproduktionsphase (Policy Exploration): Unter der Bedingung gegebener Eingabeaufforderungen generiert das Strategie-Modell πθ mehrere potenzielle Inferenzketten oder vollständige Trajektorien, die als Grundlage für nachfolgende Präferenzbewertungen und Belohnungsmodellierung dienen und die Breite der Strategieforschung bestimmen.
Präferenz-Feedbackphase (RLHF / RLAIF):
RLHF (Reinforcement Learning from Human Feedback) optimiert die Modellausgaben durch mehrere Vorschläge, menschliche Präferenzannotation und das Training von Belohnungsmodellen (RM) mit PPO, wodurch die Modellausgaben besser mit menschlichen Werten übereinstimmen; dies ist ein entscheidender Teil des Übergangs von GPT-3.5 zu GPT-4.
RLAIF (Reinforcement Learning from AI Feedback) automatisiert das Sammeln von Präferenzen mit KI-Richtern oder konstitutionellen Regeln anstelle menschlicher Annotationen, was die Kosten erheblich senkt und skalierbare Merkmale aufweist und zum dominierenden Ausrichtungsmuster von Anthropic, OpenAI, DeepSeek usw. geworden ist.
Belohnungsmodellierungsphase (Reward Modeling): Präferenzen werden auf das Eingangsbelohnungsmodell angewendet, das die Ausgaben als Belohnungen lernt. RM lehrt das Modell, „was die richtige Antwort ist“, während PRM das Modell lehrt, „wie man richtig schlussfolgt“.
RM (Belohnungsmodell) wird verwendet, um die Qualität der endgültigen Antworten zu bewerten, es bewertet nur die Ausgaben:
Prozessbelohnungsmodell (PRM): Es bewertet nicht nur die endgültige Antwort, sondern vergibt Punkte für jeden Schritt der Inferenz, jedes Token und jeden logischen Abschnitt. Dies ist auch eine Schlüsseltechnologie von OpenAI o1 und DeepSeek-R1, die im Wesentlichen darin besteht, „das Modell zu lehren, wie man denkt“.
Belohnungsvalidierungsphase (RLVR / Reward Verifiability): Während der Generierung und Verwendung von Belohnungssignalen werden „verifizierbare Beschränkungen“ eingeführt, um sicherzustellen, dass Belohnungen nach Möglichkeit aus reprodizierbaren Regeln, Fakten oder Konsensen stammen, was das Risiko von Belohnungshacking und Verzerrungen verringert und die Auditierbarkeit und Skalierbarkeit in offenen Umgebungen verbessert.
Strategieoptimierungsphase (Policy Optimization): Unter Anleitung des Signals, das vom Belohnungsmodell gegeben wird, werden die Strategieparameter θ aktualisiert, um eine stärkere Inferenzfähigkeit, höhere Sicherheit und stabilere Verhaltensmuster der Strategie πθ′ zu erreichen. Zu den gängigen Optimierungsansätzen gehören:
PPO (Proximal Policy Optimization): Der traditionelle Optimierer für RLHF, bekannt für seine Stabilität, hat jedoch oft mit langsamer Konvergenz und unzureichender Stabilität in komplexen Inferenzaufgaben zu kämpfen.
GRPO (Group Relative Policy Optimization): Ist die zentrale Innovation von DeepSeek-R1, die die Vorteilverteilung innerhalb der Kandidatenantworten modelliert, um den erwarteten Wert zu schätzen, anstatt einfach zu sortieren. Diese Methode behält die Belohnungsamplitudeninformationen und ist besser für die Optimierung von Inferenzketten geeignet, der Trainingsprozess ist stabiler und wird als wichtiger verstärkter Lernoptimierungsrahmen für tiefere Inferenzszenarien betrachtet, nach PPO.
DPO (Direct Preference Optimization): Eine nicht verstärkte Lernmethode für Nachtrainings: Sie generiert keine Trajektorien, baut kein Belohnungsmodell auf, sondern optimiert direkt auf Präferenzpaaren, was kostengünstig und stabil ist, daher wird es häufig für die Ausrichtung von Open-Source-Modellen wie Llama, Gemma usw. verwendet, verbessert jedoch nicht die Inferenzfähigkeit.
Neue Strategieimplementierungsphase (New Policy Deployment): Die optimierten Modelle zeigen: stärkere Fähigkeiten zur Generierung von Inferenzketten (System-2 Reasoning), Verhaltensweisen, die besser den menschlichen oder KI-Präferenzen entsprechen, niedrigere Illusionsraten und höhere Sicherheit. Während des kontinuierlichen Iterationsprozesses lernen die Modelle fortlaufend Präferenzen, optimieren Prozesse und verbessern die Entscheidungsqualität, was einen geschlossenen Zyklus bildet.

2.3 Fünf Kategorien der industriellen Anwendungen des verstärkten Lernens
Verstärktes Lernen (Reinforcement Learning) hat sich von früheren spielerischen Intelligenzen zu einem autonomen Entscheidungsrahmen über Branchen hinweg entwickelt. Die Anwendungsfälle können je nach technologischer Reife und industrieller Umsetzbarkeit in fünf Hauptkategorien zusammengefasst werden, die in ihren jeweiligen Richtungen entscheidende Durchbrüche erzielt haben.
Spiel und Strategien-Systeme (Game & Strategy): Dies war die früheste Validierung von RL, in Umgebungen mit „perfekten Informationen + klaren Belohnungen“ wie AlphaGo, AlphaZero, AlphaStar und OpenAI Five zeigte RL Entscheidungsintelligenz, die sich mit menschlichen Experten messen und sie sogar übertreffen kann und legte die Grundlage für moderne RL-Algorithmen.
Robotik und verkörperte Intelligenz (Embodied AI): RL ermöglicht es Robotern, durch kontinuierliche Kontrolle, dynamische Modellierung und Interaktion mit der Umgebung zu lernen, wie man steuert, Bewegungen kontrolliert und multimodale Aufgaben (wie RT-2, RT-X) ausführt, was schnell in die Industrialisierung eintreten kann und einen entscheidenden technologischen Weg zur Realisierung von Robotern in der realen Welt darstellt.
Digitale Inferenz (Digital Reasoning / LLM System-2): RL + PRM treiben große Modelle von „Sprachimitation“ zu „struktureller Inferenz“ und repräsentieren Ergebnisse, die tiefere Inferenzschleifen optimieren, anstatt nur endgültige Antworten zu bewerten. Darunter fallen DeepSeek-R1, OpenAI o1/o3, Anthropic Claude und AlphaGeometry.
Automatisierte wissenschaftliche Entdeckung und mathematische Optimierung (Scientific Discovery): RL sucht in unbeschrifteten, komplexen Belohnungen und riesigen Suchräumen nach optimalen Strukturen oder Strategien und hat grundlegende Durchbrüche wie AlphaTensor, AlphaDev, Fusion RL erzielt, die über die menschliche Intuition hinaus explorative Fähigkeiten zeigen.
Ökonomische Entscheidungsfindung und Handelssysteme (Economic Decision-making & Trading): RL wird für Strategieoptimierung, hochdimensionale Risikokontrolle und adaptive Handelssystemgenerierung verwendet und kann im Vergleich zu traditionellen quantitativen Modellen in unsicheren Umgebungen kontinuierlich lernen und ist ein wichtiger Bestandteil intelligenter Finanzen.
Drei. Die natürliche Übereinstimmung zwischen verstärktem Lernen und Web3
Die enge Verbindung zwischen verstärktem Lernen (RL) und Web3 ergibt sich daraus, dass beide im Wesentlichen „anreizgesteuerte Systeme“ sind. RL optimiert Strategien basierend auf Belohnungssignalen, während Blockchain wirtschaftliche Anreize verwendet, um das Verhalten der Teilnehmer zu koordinieren, was beide auf der Mechanismus-Ebene auf natürliche Weise konsistent macht. Der Kernbedarf von RL – großflächige heterogene Rollouts, Belohnungsverteilung und Echtheitsprüfung – ist genau die strukturelle Stärke von Web3.
Entkopplung von Inferenz und Training: Der Trainingsprozess des verstärkten Lernens kann klar in zwei Phasen unterteilt werden:
Rollout (Erkundungssampling): Modelle generieren basierend auf der aktuellen Strategie eine große Menge an Daten, die rechenintensiv, aber kommunikationssparend sind. Es erfordert keine häufige Kommunikation zwischen Knoten, was es ideal macht, um in global verteilten Verbrauchergrafikprozessoren parallel zu erzeugen.
Update (Parameteraktualisierung): Basierend auf den gesammelten Daten werden die Modellgewichte aktualisiert, was eine zentrale Node mit hoher Bandbreite benötigt.
Die natürliche Entkopplung von „Inferenz – Training“ passt perfekt zur dezentralen heterogenen Rechenstruktur: Rollouts können an ein offenes Netzwerk ausgelagert werden, und durch ein Token-System nach Beitrag abgerechnet werden, während Modellaktualisierungen zentralisiert bleiben, um Stabilität zu gewährleisten.
Verifizierbarkeit (Verifiability): ZK und Proof-of-Learning bieten Mittel zur Überprüfung, ob Knoten tatsächlich Inferenz durchführen, und lösen die Ehrlichkeitsproblematik in offenen Netzwerken. Bei deterministischen Aufgaben wie Code und mathematischen Ableitungen müssen Validierer lediglich die Antworten überprüfen, um die Arbeitslast zu bestätigen, was die Glaubwürdigkeit dezentraler RL-Systeme erheblich erhöht.
Anreizschicht, basierend auf einem tokenbasierten Feedbackproduktionsmechanismus: Das Token-System von Web3 kann direkt die Beitragenden des Präferenzfeedbacks von RLHF/RLAIF belohnen, was die Generierung von Präferenzdaten transparent, abrechenbar und genehmigungsfrei macht; Staking und Slashing schränken zusätzlich die Qualität des Feedbacks ein und bilden einen effizienteren und besser ausgerichteten Feedbackmarkt als traditionelles Crowdsourcing.
Potenzial des Multi-Agenten-verstärkten Lernens (MARL): Blockchain ist im Wesentlichen eine offene, transparente, kontinuierlich sich entwickelnde Multi-Agenten-Umgebung, in der Konten, Verträge und Agenten kontinuierlich ihre Strategien unter Anreizbedingungen anpassen, was sie von Natur aus zur Schaffung großangelegter MARL-Experimente befähigt. Obwohl es sich noch in der frühen Phase befindet, bietet seine Offenheit, verifizierbare Ausführungen und programmierbare Anreize grundsätzliche Vorteile für die zukünftige Entwicklung von MARL.
Vier. Analyse klassischer Web3 + verstärktes Lernprojekte
Basierend auf dem oben genannten theoretischen Rahmen werden wir eine kurze Analyse der aktuell repräsentativsten Projekte im Ökosystem durchführen:
Prime Intellect: Asynchrone verstärkte Lernparadigmen prime-rl
Prime Intellect widmet sich dem Aufbau eines globalen offenen Rechenleistungsmarktes, um die Trainingsbarrieren zu senken, dezentrales kollaboratives Training zu fördern und einen vollständigen offenen Superintelligenz-Technologiestack zu entwickeln. Das System umfasst: Prime Compute (einheitliche Cloud / verteilte Rechenumgebung), INTELLECT Modellfamilie (10B–100B+), Open Reinforcement Learning Environment Center (Environments Hub) sowie einen großangelegten synthetischen Daten-Engine (SYNTHETIC-1/2).
Die Kerninfrastrukturkomponente von Prime Intellect, das prime-rl-Framework, wurde speziell für asynchrone verteilte Umgebungen entwickelt und ist stark mit verstärktem Lernen verbunden. Weitere Komponenten umfassen das OpenDiLoCo-Kommunikationsprotokoll, das Bandbreitenengpässe überwindet, sowie das TopLoc-Validierungsmechanismus, das die Berechnungskonstanz gewährleistet.
Überblick über die Kerninfrastrukturkomponenten von Prime Intellect

Technologische Grundlage: prime-rl asynchrone verstärkte Lernframework
prime-rl ist die zentrale Trainingsmaschine von Prime Intellect, die speziell für großflächige asynchrone dezentrale Umgebungen entwickelt wurde und eine vollständige Entkopplung von Hochdurchsatzinferenz und stabilen Aktualisierungen durch Actor-Learner erreicht. Akteure (Rollout Worker) und Lernende (Trainer) blockieren sich nicht mehr synchron, Knoten können jederzeit beitreten oder austreten, sie müssen nur die neuesten Strategien kontinuierlich abrufen und die generierten Daten hochladen:
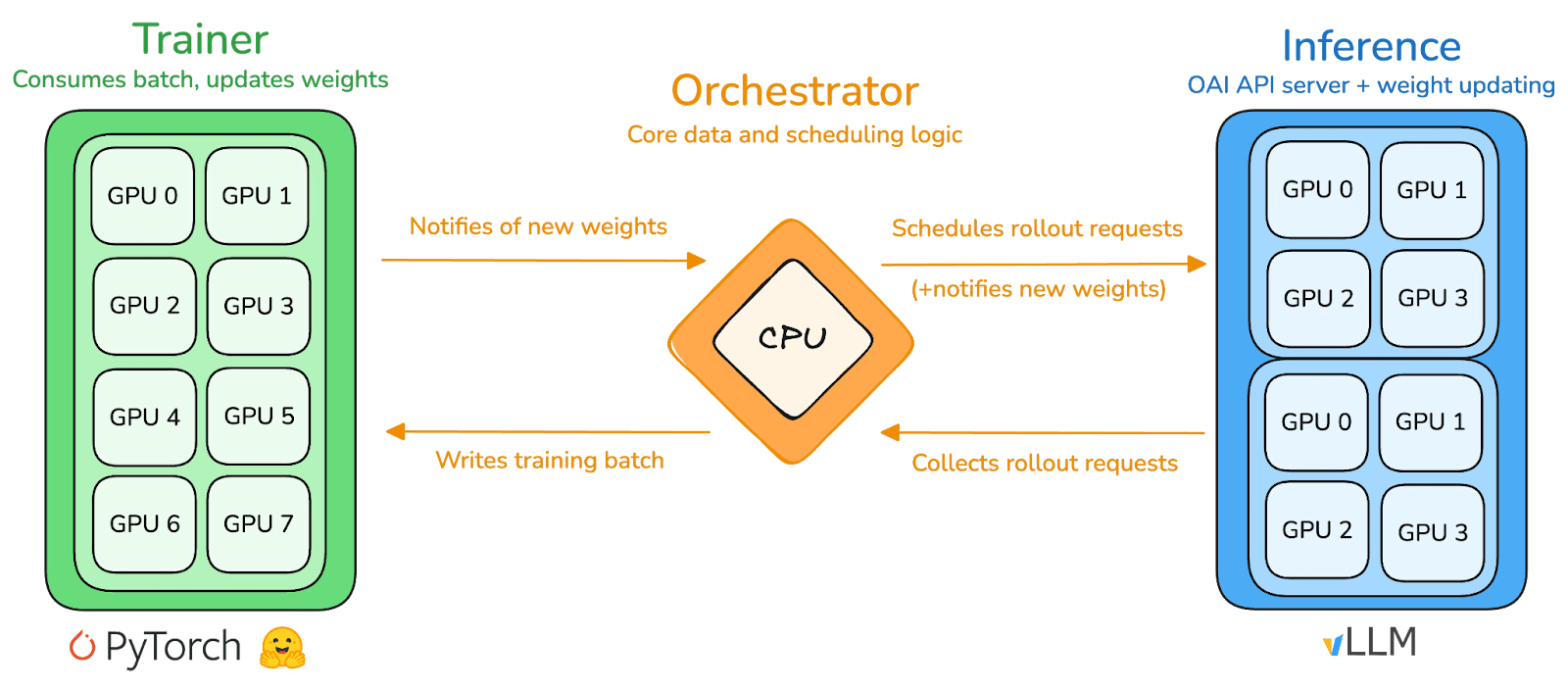
Ausführende Actor (Rollout Workers): Verantwortlich für Modellinferenz und Datengenerierung. Prime Intellect hat innovativ den vLLM-Inferenz-Engine am Actor-Ende integriert. Die PagedAttention-Technologie von vLLM und die Fähigkeit zur kontinuierlichen Batchverarbeitung ermöglichen es den Akteuren, Inferenzbahnen mit extrem hohem Durchsatz zu erzeugen.
Lernende Learner (Trainer): Verantwortlich für Strategieoptimierungen. Learner zieht asynchron Daten aus dem gemeinsamen Erfahrungsspeicher (Experience Buffer) zur Gradientaktualisierung, ohne auf die Fertigstellung aller Akteure des aktuellen Batches warten zu müssen.
Koordinator (Orchestrator): Verantwortlich für die Planung von Modellgewichten und Datenströmen.
Die Schlüsselinnovation von prime-rl:
Echte Asynchronität (True Asynchrony): prime-rl verwirft das traditionelle synchronisierte Paradigma von PPO, wartet nicht auf langsame Knoten und erfordert keine Batch-Ausrichtung, sodass beliebige Mengen und Leistungsfähigkeiten von GPUs jederzeit beitreten können, was die Umsetzbarkeit von dezentralem RL festlegt.
Tiefe Integration von FSDP2 und MoE: Durch FSDP2-Parameter-Slicing und MoE-sparsity-Aktivierungen ermöglicht prime-rl die effiziente Schulung von Modellen mit Milliarden von Parametern in verteilten Umgebungen, wobei Actor nur aktive Experten ausführt, was den Speicher- und Inferenzkosten erheblich senkt.
GRPO+ (Gruppenrelative Politikoptimierung): GRPO entbindet sich vom Kritiker-Netzwerk, reduziert signifikant den Rechen- und Speicherbedarf und passt sich natürlich asynchronen Umgebungen an. Das GRPO+ von prime-rl gewährleistet zudem durch Stabilisierungsmethoden eine zuverlässige Konvergenz unter hohen Verzögerungen.
INTELLECT Modellfamilie: Ein Zeichen für die Reife der dezentralen RL-Technologie
INTELLECT-1 (10B, Oktober 2024) hat erstmals bewiesen, dass OpenDiLoCo in heterogenen Netzwerken über drei Kontinente hinweg effizient trainieren kann (Kommunikation <2%, Auslastung 98%), wodurch die physikalische Wahrnehmung des grenzüberschreitenden Trainings überwunden wurde.
INTELLECT-2 (32B, April 2025) ist das erste Genehmigungsfreie RL-Modell, das die stabile Konvergenzfähigkeit von prime-rl und GRPO+ in Umgebungen mit mehrstufigen Verzögerungen und Asynchronität validiert und die dezentrale RL-Teilnahme mit globaler offener Rechenleistung ermöglicht.
INTELLECT-3 (106B MoE, November 2025) verwendet eine spärliche Architektur, die nur 12B Parameter aktiviert, wird auf 512×H200 trainiert und erreicht Spitzenleistungen bei der Inferenz (AIME 90,8%, GPQA 74,4%, MMLU-Pro 81,9% usw.), wobei die Gesamtleistung nahe an oder sogar über der von zentralisierten, geschlossenen Modellen mit viel größeren Maßstäben liegt.
Prime Intellect hat außerdem mehrere unterstützende Infrastrukturen aufgebaut: OpenDiLoCo reduziert durch zeitlich spärliche Kommunikation und gewichtete Unterschiede die Kommunikationsmenge für grenzüberschreitendes Training um Hunderte von Malen, sodass INTELLECT-1 in einem Netzwerk über drei Kontinente hinweg eine Auslastung von 98 % aufrechterhält; TopLoc + Verifiers bilden eine dezentrale vertrauenswürdige Ausführungsebene, um durch Aktivierungsfingerabdrücke und Sandbox-Validierung die Echtheit von Inferenz- und Belohnungsdaten sicherzustellen; die SYNTHETIC-Datenmaschine produziert großflächige qualitativ hochwertige Inferenzketten und ermöglicht es, dass 671B-Modelle effizient in Verbrauchergrafikprozessoren betrieben werden. Diese Komponenten bieten die entscheidende Ingenieurbasis für die Datengenerierung, Validierung und Inferenzdurchsatz im dezentralen RL. Die INTELLECT-Serie hat bewiesen, dass dieser Technologiestack ausgereifte weltklasse Modelle erzeugen kann, was die praktische Umsetzbarkeit des dezentralen Trainingssystems von der Konzeptphase in die praktische Phase überführt.
Gensyn: Kernstapel des verstärkten Lernens RL Swarm und SAPO
Das Ziel von Gensyn ist es, die weltweit ungenutzte Rechenleistung zu einem offenen, vertrauenslosen und unbegrenzt skalierbaren KI-Trainingsinfrastruktur zu bündeln. Zu den Kernkomponenten gehören eine standardisierte Ausführungsschicht über Geräte hinweg, ein Peer-to-Peer-Koordinationsnetzwerk und ein vertrauensloses Aufgabensystem zur Validierung, die alle durch Smart Contracts automatisch Aufgaben und Belohnungen zuteilen. Um die Merkmale des verstärkten Lernens zu berücksichtigen, führt Gensyn Kernmechanismen wie RL Swarm, SAPO und SkipPipe ein, die die drei Phasen der Generierung, Bewertung und Aktualisierung entkoppeln und die kollektive Evolution durch ein „Schwarm“-Netzwerk aus globalen heterogenen GPUs ermöglichen. Das Endziel ist nicht nur Rechenleistung, sondern verifizierbare Intelligenz (Verifiable Intelligence).
Anwendungen des verstärkten Lernens im Gensyn-Stack

RL Swarm: Dezentralisierte kollaborative verstärkte Lernmaschine
RL Swarm zeigt ein neues Kooperationsmodell. Es handelt sich nicht mehr um einfache Aufgabenverteilung, sondern um einen dezentralen Zyklus von „Generierung – Bewertung – Aktualisierung“, der den kollaborativen Lernprozess simuliert und unendlich zirkuliert:
Solver (Ausführende): Verantwortlich für lokale Modellinferenz und Rollout-Generierung, wobei die Heterogenität der Knoten kein Hindernis darstellt. Gensyn integriert lokal einen hochdurchsatzfähigen Inferenz-Engine (wie CodeZero), der vollständige Trajektorien und nicht nur Antworten ausgeben kann.
Proposer (Aufgeber): Dynamisches Generieren von Aufgaben (Mathematikfragen, Programmierprobleme usw.), unterstützt die Vielfalt der Aufgaben und die adaptive Schwierigkeit wie bei Curriculum Learning.
Evaluatoren (Bewertende): Verwenden gefrorene „Schiedsrichtermodelle“ oder Regeln, um lokale Rollouts zu bewerten und lokale Belohnungssignale zu erzeugen. Der Bewertungsprozess kann auditiert werden, um den Raum für böswilliges Verhalten zu verringern.
Die drei bilden eine P2P-RL-Organisationsstruktur, die großflächiges kollaboratives Lernen ohne zentrale Koordination ermöglicht.
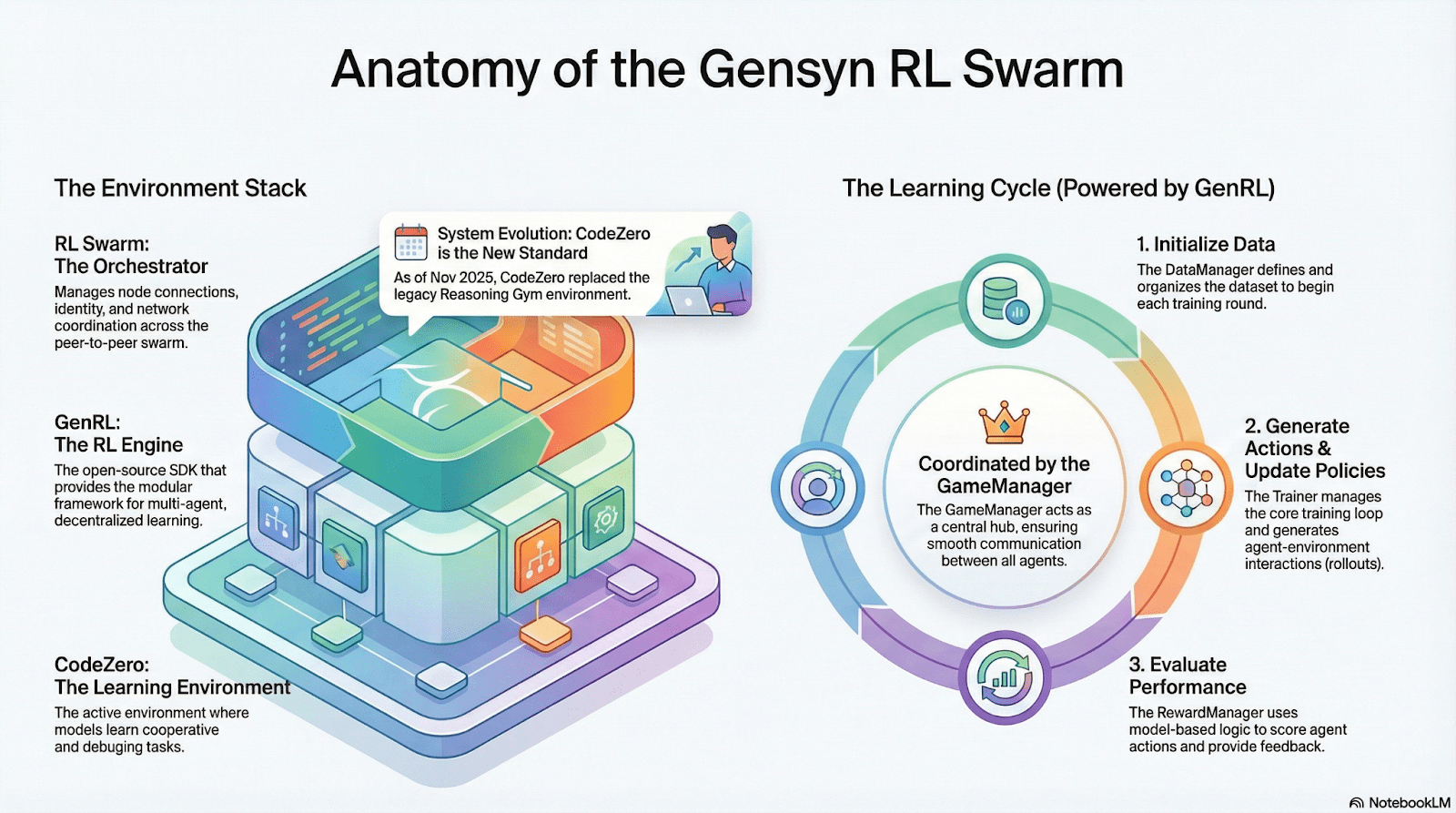
SAPO: Eine für die Dezentralisierung umgestaltete Strategieoptimierungsalgorithmen: SAPO (Swarm Sampling Policy Optimization) zielt darauf ab, „Rollouts zu teilen und Proben ohne Gradientensignale zu filtern, anstatt Gradienten zu teilen“. Durch großflächiges dezentrales Rollout-Sampling werden empfangene Rollouts als lokal generiert betrachtet, wodurch eine stabile Konvergenz in einem Umfeld ohne zentrale Koordination und signifikante Knotenverzögerungen aufrechterhalten wird. Im Vergleich zu PPO, das auf ein Kritiker-Netzwerk angewiesen ist und hohe Berechnungskosten verursacht, oder zu GRPO, das auf Gruppen-Vorteilsabschätzungen basiert, ermöglicht SAPO, dass auch Verbrauchergrafikprozessoren effizient an der großflächigen Optimierung des verstärkten Lernens teilnehmen können.
Durch RL Swarm und SAPO hat Gensyn bewiesen, dass verstärktes Lernen (insbesondere in der Nachtrainingsphase von RLVR) nativ an dezentrale Strukturen anpassbar ist – da es mehr auf großflächige, vielfältige Erkundung (Rollout) angewiesen ist als auf hochfrequente Parametersynchronisation. In Kombination mit den Validierungssystemen von PoL und Verde bietet Gensyn einen alternativen Weg für das Training von Billionen von Parametern, der nicht mehr von einem einzelnen Technologieriesen abhängt: ein selbstentwickeltes Superintelligenznetzwerk, das aus Millionen von heterogenen GPUs weltweit besteht.
Nous Research: Verifizierbare verstärkte Lernumgebung Atropos
Nous Research ist dabei, eine dezentrale, selbstentwickelnde kognitive Infrastruktur aufzubauen. Ihre Kernkomponenten – Hermes, Atropos, DisTrO, Psyche und World Sim – sind zu einem kontinuierlichen geschlossenen intelligenten Evolutionssystem organisiert. Anders als der traditionelle lineare Prozess „Vortraining – Nachtraining – Inferenz“ integriert Nous verstärkte Lerntechniken wie DPO, GRPO und Ablehnungssampling, um Datengenerierung, Validierung, Lernen und Inferenz in einen kontinuierlichen Feedbackzyklus zu vereinen und ein sich ständig selbst verbesserndes geschlossenes KI-Ökosystem zu schaffen.
Überblick über die Komponenten von Nous Research

Modellschicht: Hermes und die Evolution der Inferenzfähigkeiten
Die Hermes-Serie ist die Hauptmodellschnittstelle von Nous Research, deren Evolution klar den Übergang von der traditionellen SFT/DPO-Ausrichtung zum Reasoning Reinforcement Learning (Reasoning RL) zeigt:
Hermes 1–3: Anweisungsausrichtung und frühe Agentenfähigkeiten: Hermes 1–3 erreicht robuste Anweisungsausrichtung durch kostengünstige DPO und nutzt in Hermes 3 synthetische Daten und die erstmals eingeführte Atropos-Validierungsmechanik.
Hermes 4 / DeepHermes: Über die Denkketten wird System-2-artiges langsames Denken in Gewichte geschrieben, um durch Testzeit-Skalierung die mathematischen und Code-Leistungen zu steigern, und nutzt „Ablehnungs-Sampling + Atropos-Validierung“, um hochreine Inferenzdaten zu generieren.
DeepHermes verwendet GRPO anstelle von PPO, das schwer auf verteilte Umgebungen zu bringen ist, sodass Inferenz-RL im dezentralen GPU-Netzwerk von Psyche betrieben werden kann und die Ingenieurbasis für die Skalierbarkeit von Open-Source-Inferenz-RL gelegt wird.
Atropos: Verifizierbare belohnungsgetriebene verstärkte Lernumgebung
Atropos ist der wahre Dreh- und Angelpunkt des Nous RL-Systems. Es fasst Aufforderungen, Werkzeugaufrufe, Codeausführungen und mehrstufige Interaktionen in einer standardisierten RL-Umgebung zusammen, die direkt überprüfen kann, ob die Ausgabe korrekt ist, und somit deterministische Belohnungssignale liefert, die teure und nicht skalierbare menschliche Annotationen ersetzen. Noch wichtiger ist, dass Atropos in dem dezentralen Trainingsnetzwerk Psyche als „Schiedsrichter“ fungiert, um zu überprüfen, ob Knoten tatsächlich die Strategien verbessern, und die auditierbare Proof-of-Learning unterstützt, um das Problem der Vertrauenswürdigkeit von Belohnungen im verteilten RL grundlegend zu lösen.
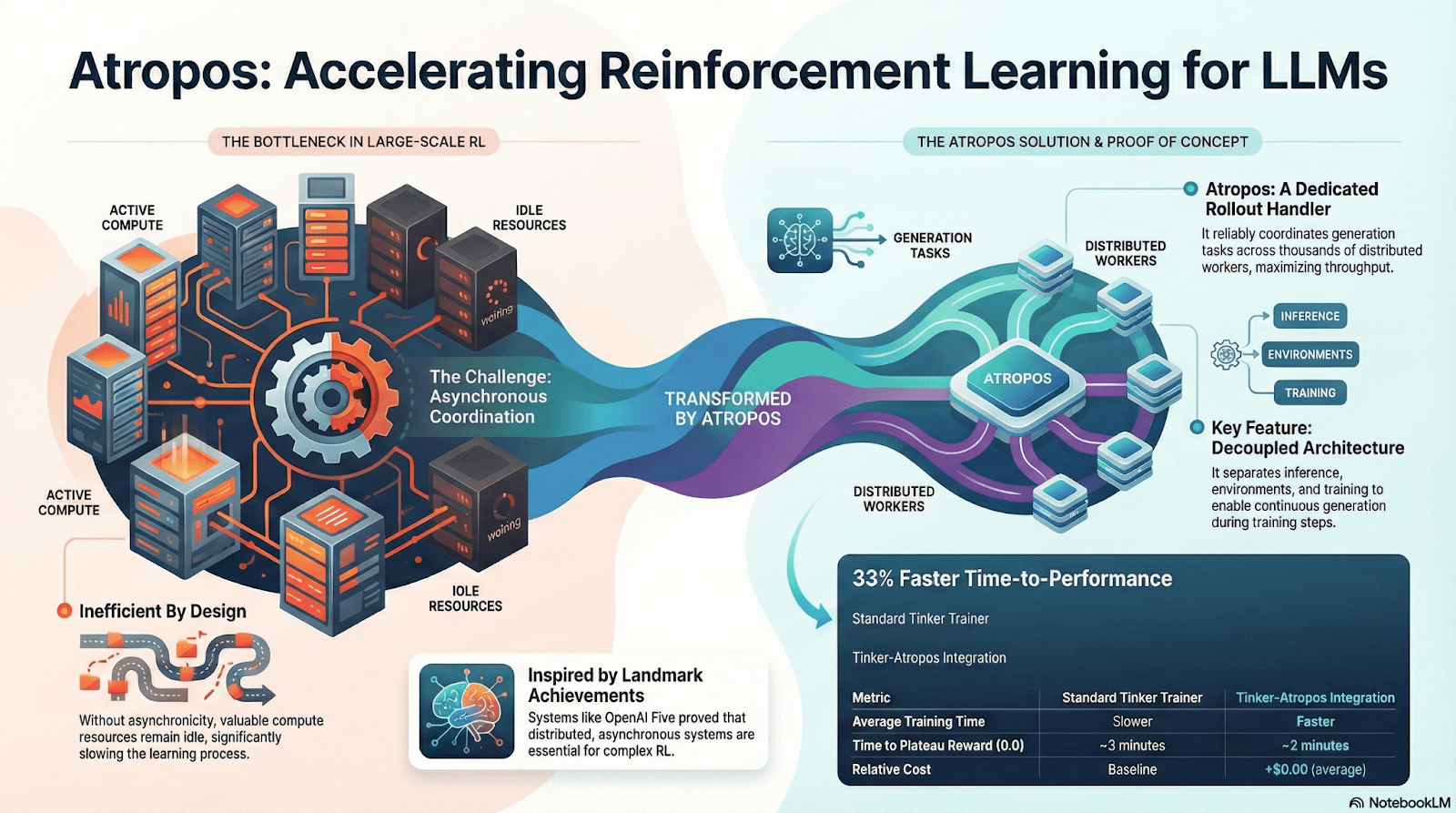
DisTrO und Psyche: Optimierungsschicht für dezentrales verstärktes Lernen
Traditionelles RLHF/RLAIF-Training ist auf zentralisierte Hochbandbreitencluster angewiesen, was eine Kernbarriere darstellt, die nicht in der Open-Source-Welt reproduzierbar ist. DisTrO hat durch Momentum-Decoupling und Gradient Compression die Kommunikationskosten von RL um mehrere Größenordnungen gesenkt, sodass das Training über Internetbandbreiten durchgeführt werden kann; Psyche hat dieses Trainingsmechanismus im Blockchain-Netzwerk bereitgestellt, sodass Knoten Inferenz, Validierung, Belohnungsbewertung und Gewichtserneuerungen lokal abschließen können und einen vollständigen geschlossenen Zyklus im RL bilden.
In Nous' System validiert Atropos die Denkketten; DisTrO komprimiert das Training; Psyche führt den RL-Zyklus aus; World Sim bietet komplexe Umgebungen; Forge erfasst reale Inferenz; Hermes schreibt alle Lerninhalte in Gewichte. Verstärktes Lernen ist nicht nur eine Trainingsphase, sondern das Kernprotokoll in der Nous-Architektur, das Daten, Umgebungen, Modelle und Infrastrukturen verbindet und Hermes zu einem lebenden System macht, das sich in einem offenen Rechenleistungsnetzwerk kontinuierlich selbst verbessern kann.
Gradientennetzwerk: Architektur des verstärkten Lernens Echo
Die Kernvision des Gradientennetzwerks besteht darin, das Rechenparadigma von KI durch einen „Offenen Intelligenzprotokollstapel“ (Open Intelligence Stack) neu zu gestalten. Der Technologiestack von Gradient besteht aus einer Gruppe unabhängig evolvierender und heterogen kooperierender Kernprotokolle. Sein System umfasst von der unteren Kommunikation bis zur oberen intelligenten Zusammenarbeit: Parallax (verteilte Inferenz), Echo (dezentrales RL-Training), Lattica (P2P-Netzwerk), SEDM / Massgen / Symphony / CUAHarm (Speicher, Zusammenarbeit, Sicherheit), VeriLLM (vertrauenswürdige Validierung), Mirage (hohe Treue Simulation), die zusammen eine kontinuierlich evolvierende dezentrale intelligente Infrastruktur bilden.

Echo – Architektur des verstärkten Lernens
Echo ist das verstärkte Lernframework von Gradient, dessen zentraler Entwurf darin besteht, das Training, die Inferenz und die Daten (Belohnungs-)Pfad im verstärkten Lernen zu entkoppeln, sodass Rollout-Generierung, Strategieoptimierung und Belohnungsbewertung in heterogenen Umgebungen unabhängig skaliert und verwaltet werden können. Das System arbeitet kooperativ in einem heterogenen Netzwerk, das aus Inferenz- und Trainingsknoten besteht, und verwendet leichtgewichtige Synchronisierungsmechanismen, um die Stabilität des Trainings in weiträumigen heterogenen Umgebungen aufrechtzuerhalten und die herkömmliche DeepSpeed RLHF / VERL-Problematik zu mildern, bei der das Mischen von Inferenz und Training zu einem Versagen von SPMD und zu Flaschenhälsen der GPU-Nutzung führt.
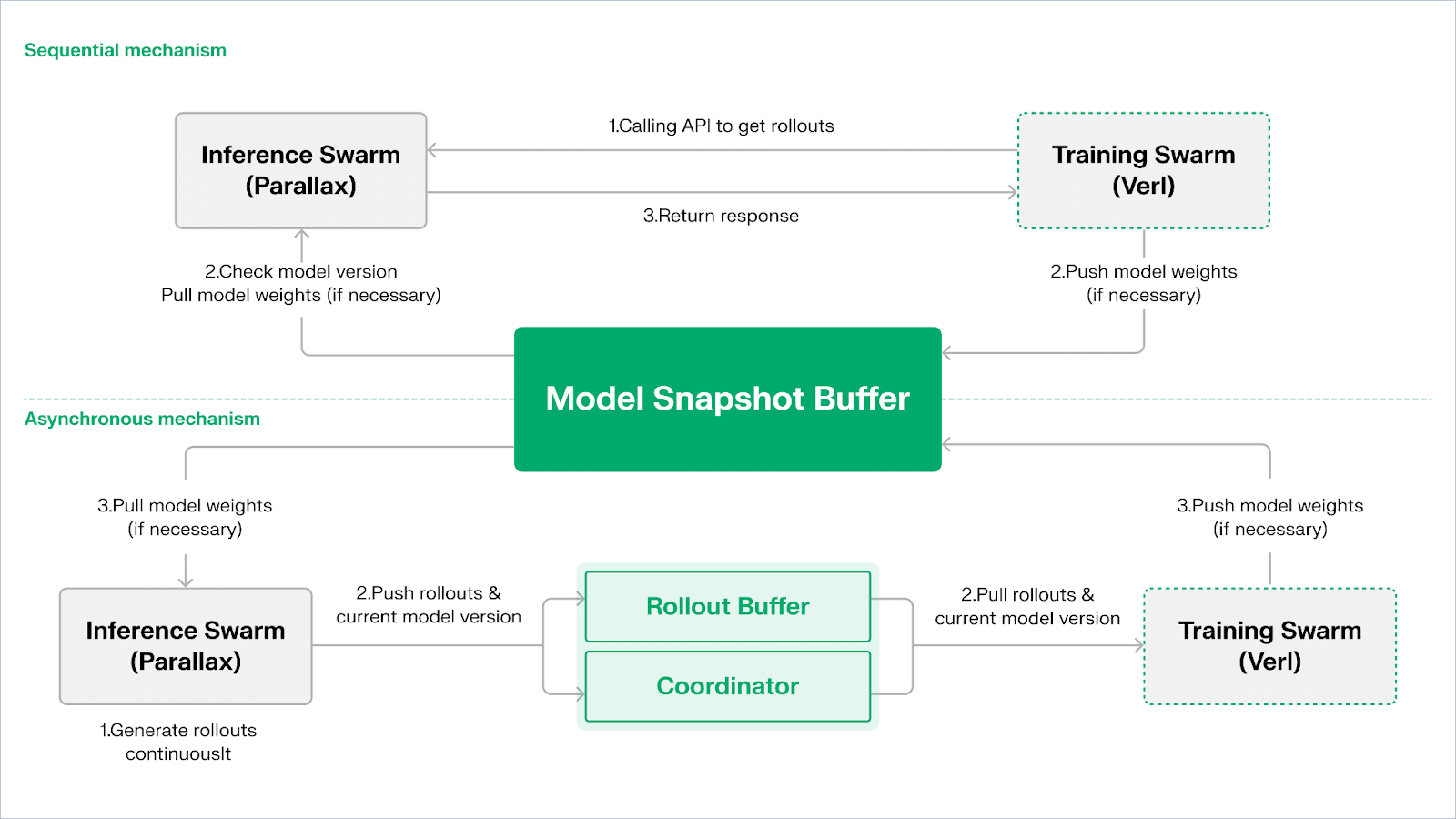
Echo verwendet eine „Inferenz – Trainings-Doppel-Schwarm-Architektur“, um die Auslastung der Rechenleistung zu maximieren, wobei beide Schwärme unabhängig voneinander arbeiten und sich nicht gegenseitig blockieren:
Maximierung des Sampling-Durchsatzes: Der Inferenz-Schwarm besteht aus Verbrauchergrafikprozessoren und Edge-Geräten, die über Parallax einen hochdurchsatzfähigen Sampler im Pipeline-Parallelmodus aufbauen, der sich auf die Trajektoriensynthese konzentriert;
Maximierung der Gradientenkraft: Der Trainingsschwarm besteht aus Verbrauchergrafikprozessor-Netzwerken, die in zentralisierten Clustern oder weltweit an verschiedenen Standorten betrieben werden können und für die Gradientenkonsolidierung, Parametersynchronisation und LoRA-Finetuning verantwortlich sind, wobei der Fokus auf dem Lernprozess liegt.
Um die Konsistenz von Strategien und Daten aufrechtzuerhalten, bietet Echo zwei Arten von leichten Synchronisierungsprotokollen: sequentiell (Sequential) und asynchron (Asynchronous), um die bidirektionale Konsistenzverwaltung von Strategiegewichten und Trajektorien zu erreichen:
Sequentielles Abrufen (Pull) – Modus | Präzisionspriorität: Die Trainingsseite zwingt Knoten vor dem Abrufen neuer Trajektorien, die Modellversion zu aktualisieren, um die Frische der Trajektorien sicherzustellen, was bei stark sensiblen Aufgaben für veraltete Strategien geeignet ist;
Asynchrones Push-Pull-Modell | Effizienzpriorität: Die Inferenzseite generiert kontinuierlich Trajektorien mit Versionsmarkierungen, während die Trainingsseite in ihrem eigenen Tempo konsumiert. Der Koordinator überwacht die Versionsabweichungen und löst Gewichtserneuerungen aus, um die Geräteeffizienz zu maximieren.
Auf der unteren Ebene baut Echo auf Parallax (heterogene Inferenz in Umgebungen mit niedriger Bandbreite) und leichten verteilten Trainingseinheiten (wie VERL) auf und nutzt LoRA, um die Synchronisationskosten zwischen Knoten zu senken, damit verstärktes Lernen stabil in globalen heterogenen Netzwerken betrieben werden kann.
Grail: Verstärktes Lernen im Bittensor-Ökosystem
Bittensor hat durch seinen einzigartigen Yuma-Konsensmechanismus ein riesiges, spärliches und nichtstationäres Netzwerk von Belohnungsfunktionen aufgebaut.
Das Covenant AI im Bittensor-Ökosystem hat mit SN3 Templar, SN39 Basilica und SN81 Grail eine vertikal integrierte Pipeline vom Vortraining bis zum Nachtraining von RL aufgebaut. Dabei ist SN3 Templar für das Vortraining des Basis-Modells verantwortlich, SN39 Basilica bietet einen dezentralen Rechenleistungsmarkt, während SN81 Grail als „verifizierbare Inferenzschicht“ für das Nachtraining von RL fungiert und den Kernprozess von RLHF/RLAIF übernimmt, um eine geschlossene Optimierung vom Basis-Modell zur Strategiekonvergenz abzuschließen.

Das Ziel von GRAIL ist es, die Echtheit jeder Rollout von verstärktem Lernen durch kryptografische Mittel zu beweisen und die Identität des Modells zu binden, um sicherzustellen, dass RLHF in einem vertrauenslosen Umfeld sicher ausgeführt werden kann. Das Protokoll etabliert durch drei Mechanismen eine vertrauenswürdige Kette:
Deterministische Herausforderungsgenerierung: Verwendung von drand-Random-Beacons und Block-Hashes zur Generierung unvorhersehbarer, aber reproduzierbarer herausfordernder Aufgaben (wie SAT, GSM8K), um vorab berechneten Betrug auszuschließen;
Durch PRF-Indexsampling und Sketch-Commitments können Validierer mit extrem niedrigen Kosten Token-Level-Logprobs und Inferenzketten stichprobenartig überprüfen und bestätigen, dass Rollouts tatsächlich von den angegebenen Modellen erzeugt werden.
Modellidentitätsbindung: Bindet den Inferenzprozess an die strukturelle Signatur von Modellgewichten und Tokenverteilungen, um sicherzustellen, dass der Austausch von Modellen oder die Wiederholung von Ergebnissen sofort erkannt wird. Dies bietet eine grundlegende Grundlage für die Echtheit von Inferenzpfaden (Rollouts) im RL.
Auf dieser Mechanik hat das Grail-Subnetz einen verifizierbaren Nachtrainingsprozess im GRPO-Stil implementiert: Miner generieren mehrere Inferenzpfade für dasselbe Problem, die Validierer bewerten die Richtigkeit, die Qualität der Inferenzkette und die SAT-Erfüllung und schreiben die normalisierten Ergebnisse in die Blockchain als TAO-Gewichtung. Öffentliche Experimente zeigen, dass dieses Framework die MATH-Genauigkeit von Qwen2.5-1.5B von 12,7 % auf 47,6 % gesteigert hat, was beweist, dass es sowohl Betrug verhindern als auch die Modellfähigkeiten erheblich verstärken kann. In der Trainingspipeline von Covenant AI ist Grail das Fundament für Vertrauen und Ausführung in dezentralem RLVR/RLAIF und ist derzeit noch nicht offiziell im Hauptnetz online.
Fraction AI: wettbewerbsbasiertes verstärktes Lernen RLFC
Die Architektur von Fraction AI ist klar um wettbewerbsbasiertes verstärktes Lernen (Reinforcement Learning from Competition, RLFC) und spielerische Datenannotation herum aufgebaut und ersetzt die statischen Belohnungen und menschlichen Annotationen von traditionellem RLHF durch eine offene, dynamische Wettbewerbsumgebung. Agenten konkurrieren in unterschiedlichen Spaces, und ihre relative Rangordnung und die Bewertungen von KI-Richtern bilden gemeinsam die Echtzeitbelohnungen, wodurch der Ausrichtungsprozess zu einem kontinuierlichen, online arbeitenden Multi-Agenten-Spielsystem wird.
Der wesentliche Unterschied zwischen traditionellem RLHF und dem RLFC von Fraction AI besteht darin:

Der Kernwert von RLFC liegt darin, dass die Belohnungen nicht mehr von einem einzelnen Modell kommen, sondern von ständig sich entwickelnden Gegnern und Bewertenden, um zu vermeiden, dass das Belohnungsmodell ausgenutzt wird, und durch strategische Diversität zu verhindern, dass das Ökosystem in lokale Optima verfällt. Die Struktur von Spaces bestimmt die Spielnatur (Nullsummenspiel oder positiv summiert) und fördert komplexes Verhalten durch Gegeneinander und Zusammenarbeit.
In Bezug auf die Systemarchitektur hat Fraction AI den Trainingsprozess in vier Schlüsselkomponenten zerlegt:
Agenten: Leichte Strategiemodule, die auf Open-Source-LLMs basieren, werden durch QLoRA mit differentiellen Gewichten erweitert, kostengünstig aktualisiert;
Spaces: Isolierte Aufgabenbereich-Umgebungen, in die Agenten gegen Gebühr eintreten und durch Gewinne oder Verluste Belohnungen erhalten;
KI-Richter: Sofortige Belohnungsschichten, die mit RLAIF aufgebaut werden, bieten skalierbare und dezentrale Bewertungen;
Proof-of-Learning: Bindet die Strategienaktualisierung an spezifische Wettbewerbsergebnisse, um sicherzustellen, dass der Trainingsprozess verifizierbar und betrugsfest ist.
Das Wesen von Fraction AI besteht darin, eine evolutionäre Maschine für Mensch-Maschine-Kollaboration zu schaffen. Die Benutzer fungieren als „Meta-Optimierer“ auf der Strategiebene, die durch Prompt Engineering und Hyperparameter-Konfiguration die Erkundungsrichtung leiten; während Agenten in mikro-konkurrenzierenden Umgebungen automatisch eine Fülle von hochwertigen Präferenzdatenpaaren generieren. Dieses Modell ermöglicht es, Datenannotation durch „vertrauensloses Feintuning“ (Trustless Fine-tuning) zu einem geschlossenen Handelszyklus zu machen.
Vergleich der Architektur von verstärkten Lern-Web3-Projekten

Fünf. Zusammenfassung und Ausblick: Wege und Chancen des verstärkten Lernens × Web3
Basierend auf der Dekonstruktionsanalyse der oben genannten Spitzenprojekte haben wir beobachtet: Obwohl die Einstiegspunkte der verschiedenen Teams (Algorithmus, Engineering oder Markt) unterschiedlich sind, konvergiert die zugrunde liegende Architekturlogik, wenn verstärktes Lernen (RL) mit Web3 kombiniert wird, zu einem hoch konsistenten „Entkopplungs-Validierungs-Anreiz“-Paradigma. Dies ist nicht nur eine technische Zufälligkeit, sondern auch das unvermeidliche Ergebnis der Anpassung der einzigartigen Eigenschaften des verstärkten Lernens an das dezentrale Netzwerk.
Allgemeine Architekturmerkmale des verstärkten Lernens: Lösung zentraler physischer Einschränkungen und Vertrauensprobleme
Entkopplung von Rollouts & Lernen (Decoupling of Rollouts & Learning) – Standardberechnungs-Topologie
Kommunikationssparsamkeit, parallelisierbare Rollouts werden an globalen Verbrauchergrafikprozessoren ausgelagert, während hochbandbreitige Parameteraktualisierungen auf eine kleine Anzahl von Trainingsknoten konzentriert werden, von Prime Intellects asynchronem Actor-Learner bis hin zur Doppel-Schwarmarchitektur von Gradient.
Verifizierungsgetriebenes Vertrauensniveau (Verification-Driven Trust) – infrastrukturell
In einem genehmigungsfreien Netzwerk muss die Berechnung der Echtheit durch mathematische und mechanische Entwurfsprinzipien sichergestellt werden, was die Implementierung umfasst, einschließlich Gensyns PoL, Prime Intellects TOPLOC und Grails kryptografische Validierung.
Tokenisierte Anreizschleife (Tokenized Incentive Loop) – Markt selbstregulierend
Rechenleistungsangebot, Datengenerierung, Verifizierungsreihenfolge und Belohnungsverteilung bilden einen geschlossenen Zyklus, der Teilnahmen durch Anreize fördert und Betrug durch Slash unterdrückt, sodass das Netzwerk in offenen Umgebungen stabil und kontinuierlich weiterentwickelt bleibt.
Differenzierte technische Pfade: Unterschiedliche „Durchbruchpunkte“ unter einer einheitlichen Architektur
Obwohl die Architektur konvergiert, haben verschiedene Projekte je nach ihren Genen unterschiedliche technische Schutzmechanismen gewählt:
Algorithmus Durchbruch Fraktion (Nous Research): Versucht, die grundlegenden Widersprüche des verteilten Trainings (Bandbreitenengpass) von der mathematischen Basis aus zu lösen. Ihr DisTrO-Optimierer zielt darauf ab, die Gradientendatenkommunikation um Tausende von Malen zu komprimieren, um zu ermöglichen, dass Haushaltsbandbreiten auch große Modelltrainings durchführen können, was eine „Dimensionaleinschränkung“ der physikalischen Einschränkungen darstellt.
Systemtechnik Fraktion (Prime Intellect, Gensyn, Gradient): Fokussiert auf den Aufbau der nächsten Generation von „KI-Laufzeitsystemen“. ShardCast von Prime Intellect und Parallax von Gradient sind beide darauf ausgelegt, unter den bestehenden Netzwerkbedingungen die höchste Effizienz heterogener Cluster durch extreme Ingenieursmethoden herauszuholen.
Marktspiel Fraktion (Bittensor, Fraction AI): Fokussiert auf das Design von Belohnungsfunktionen (Reward Function). Durch das Design raffinierter Bewertungsmechanismen werden Miner dazu gebracht, optimale Strategien zu finden, um die Emergenz von Intelligenz zu beschleunigen.
Vorteile, Herausforderungen und Ausblick auf das Ende
Im Paradigma der Verbindung von verstärktem Lernen und Web3 zeigen sich die systemischen Vorteile zunächst in der Umgestaltung von Kostenstrukturen und Governance-Strukturen.
Kostenumformung: Die Nachfrage nach Rollouts im RL-Nachtraining ist unbegrenzt, Web3 kann globale Long-Tail-Rechenleistung zu extrem niedrigen Kosten mobilisieren, was den zentralisierten Cloud-Anbietern schwer zu erreichen ist.
Souveräne Ausrichtung (Sovereign Alignment): Durchbrechen der Monopolstellung großer Unternehmen in Bezug auf die Werte von KI (Alignment), sodass Gemeinschaften durch Token-Votierungen entscheiden können, was ein „gutes Ergebnis“ ist, um die Demokratisierung der KI-Governance zu erreichen.
In der Zwischenzeit sieht sich dieses System auch zwei strukturellen Einschränkungen gegenüber.
Bandbreitenwand (Bandwidth Wall): Trotz Innovationen wie DisTrO bleibt die physische Verzögerung ein limitierender Faktor für das vollständige Training von sehr großen Modellen (70B+), sodass Web3 AI derzeit mehr auf Feinabstimmung und Inferenz beschränkt ist.
Goodhart's Gesetz (Reward Hacking): In stark incentivierten Netzwerken neigen Miner dazu, die Belohnungsregeln (Punkte zu manipulieren) zu „überanpassen“, anstatt echte Intelligenz zu fördern. Die Entwicklung robuster Belohnungsfunktionen zur Betrugsvermeidung ist ein zeitloses Spiel.
Bösartige byzantinische Angriffe (BYZANTINE worker): Durch aktive Manipulation und Vergiftung von Trainingssignalen wird das Modellkonvergenz gefährdet. Der Kern liegt nicht in der ständigen Gestaltung von Betrugsvermeidung für Belohnungsfunktionen, sondern im Aufbau eines Mechanismus mit adversarialer Robustheit.
Die Verbindung von verstärktem Lernen und Web3 besteht im Wesentlichen darin, die Mechanismen, durch die Intelligenz produziert, ausgerichtet und Wert verteilt wird, neu zu schreiben. Der evolutionäre Pfad kann als drei komplementäre Richtungen zusammengefasst werden:
Dezentrales Trainingsnetzwerk: Von Rechenleistungsminen zu Strategienetzwerken werden parallele und verifizierbare Rollouts an globale Long-Tail-GPUs ausgelagert, kurzfristig auf den verifizierbaren Inferenzmarkt fokussiert und mittelfristig zu einem Cluster von verstärkten Lernsubnetzen gewachsen;
Die Kapitalisierung von Präferenzen und Belohnungen: Von annotierten Arbeitskräften zu Datenaktien. Die Kapitalisierung von Präferenzen und Belohnungen zu realisieren, um hochwertiges Feedback und das Belohnungsmodell in verwaltbare, verteilbare Datenassets zu verwandeln, ist ein Upgrade von „annotierten Arbeitskräften“ zu „Datenaktien“.
Vertikale Szenarien mit „klein und fein“ Evolution: In vertikalen Szenarien, in denen Ergebnisse verifiziert und Erträge quantifizierbar sind, entstehen kleine, aber starke spezialisierte RL-Agenten, wie DeFi-Strategien, Code-Generierung, wodurch Strategieverbesserungen und Wertabschöpfungen direkt gebunden werden und die Chance haben, allgemeine geschlossene Modelle zu übertreffen.
Insgesamt liegt die wahre Chance von verstärktem Lernen × Web3 nicht darin, eine dezentralisierte Version von OpenAI zu reproduzieren, sondern darin, die „Intelligenzproduktionsverhältnisse“ neu zu schreiben: Das Training soll zum offenen Rechenleistungsmarkt werden, die Belohnungen und Präferenzen sollen zu verwaltbaren On-Chain-Assets werden, und der Wert, den Intelligenz mit sich bringt, soll nicht mehr auf der Plattform konzentriert sein, sondern zwischen Trainern, Ausrichtern und Nutzern neu verteilt werden.
Haftungsausschluss: Dieser Artikel wurde bei der Erstellung durch die KI-Tools ChatGPT-5 und Gemini 3 unterstützt. Der Autor hat sich bemüht, die Informationen zu überprüfen und deren Richtigkeit und Genauigkeit sicherzustellen, doch es können dennoch Fehler auftreten, dafür bitten wir um Verständnis. Es sollte besonders darauf hingewiesen werden, dass der Kryptowerte-Markt im Allgemeinen von einer Divergenz zwischen den Grundlagen eines Projekts und der Preisentwicklung auf dem Sekundärmarkt betroffen ist. Der Inhalt dieses Artikels dient lediglich der Informationsintegration und dem akademischen / Forschungsverkehr und stellt keine Anlageberatung dar, noch sollte er als Empfehlung für den Kauf oder Verkauf irgendeines Tokens angesehen werden.