Autor: 0xjacobzhao | https://linktr.ee/0xjacobzhao
Dieser unabhängige Forschungsbericht wird von IOSG Ventures unterstützt. Der Forschungs- und Schreibprozess wurde von der Arbeit von Sam Lehman (Pantera Capital) zur Verstärkungslernen inspiriert. Danke an Ben Fielding (Gensyn.ai), Gao Yuan (Gradient), Samuel Dare & Erfan Miahi (Covenant AI), Shashank Yadav (Fraction AI), Chao Wang für ihre wertvollen Vorschläge zu diesem Artikel. Dieser Artikel strebt nach Objektivität und Genauigkeit, aber einige Ansichten beinhalten subjektive Urteile und können Vorurteile enthalten. Wir schätzen das Verständnis der Leser.
Künstliche Intelligenz wandelt sich von musterbasierter statistischer Lernweise zu strukturierten Denk-Systemen, wobei das Post-Training – insbesondere verstärkendes Lernen – zentral für die Skalierung der Fähigkeiten wird. DeepSeek-R1 signalisiert einen Paradigmenwechsel: Verstärkendes Lernen verbessert jetzt nachweislich die Denkvertiefung und komplexe Entscheidungsfindung und entwickelt sich von einem bloßen Ausrichtungswerkzeug zu einem kontinuierlichen Weg zur Intelligenzsteigerung.
Parallel dazu verwandelt Web3 die KI-Produktion durch dezentrale Berechnung und Krypto-Anreize, deren Überprüfbarkeit und Koordination sich natürlich mit den Bedürfnissen des verstärkenden Lernens decken. Dieser Bericht untersucht KI-Trainingsparadigmen und Grundlagen des verstärkenden Lernens, hebt die strukturellen Vorteile von "Verstärkendes Lernen × Web3" hervor und analysiert Prime Intellect, Gensyn, Nous Research, Gradient, Grail und Fraction AI.
I. Drei Phasen des KI-Trainings
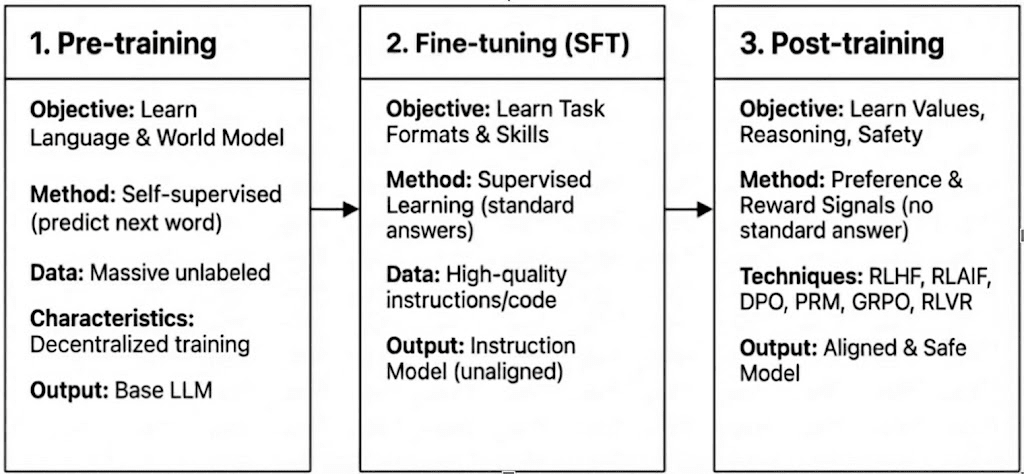
Das moderne LLM-Training umfasst drei Phasen – Pre-Training, überwachte Feinabstimmung (SFT) und Post-Training/verstärkendes Lernen – die dem Aufbau eines Weltmodells, der Einspeisung von Aufgabenfähigkeiten und der Gestaltung von Denken und Werten entsprechen. Ihre Rechen- und Überprüfungsmerkmale bestimmen, wie kompatibel sie mit der Dezentralisierung sind.
Pre-Training: legt die grundlegenden statistischen und multimodalen Grundlagen durch massives selbstüberwachtes Lernen, was 80–95 % der Gesamtkosten verbraucht und enge Synchronisation, homogene GPU-Cluster und einen hohen Bandbreitenzugang erfordert, was es inhärent zentralisiert macht.
Überwachte Feinabstimmung (SFT): fügt Aufgaben- und Anweisungsfähigkeiten mit kleineren Datensätzen und geringeren Kosten (5–15 %) hinzu, verwendet oft PEFT-Methoden wie LoRA oder Q-LoRA, hängt jedoch weiterhin von der Gradienten-Synchronisation ab, was die Dezentralisierung einschränkt.
Post-Training: Post-Training besteht aus mehreren iterativen Phasen, die die Denkfähigkeit, Werte und Sicherheitsgrenzen eines Modells formen. Es umfasst sowohl RL-basierte Ansätze (z. B. RLHF, RLAIF, GRPO), nicht-RL-Präferenzoptimierung (z. B. DPO) und Prozess-Belohnungsmodelle (PRM). Mit geringeren Daten- und Kostenanforderungen (ca. 5–10 %) konzentriert sich die Rechnung auf Rollouts und Politikaktualisierungen. Die native Unterstützung für asynchrone, verteilte Ausführung – oft ohne vollständige Modellgewichte zu benötigen – macht das Post-Training zur Phase, die am besten für Web3-basierte dezentrale Trainingsnetzwerke geeignet ist, wenn es mit überprüfbarer Berechnung und on-chain-Anreizen kombiniert wird.
II. Landschaft der Verstärkenden Lerntechnologie
2.1 Systemarchitektur des verstärkenden Lernens
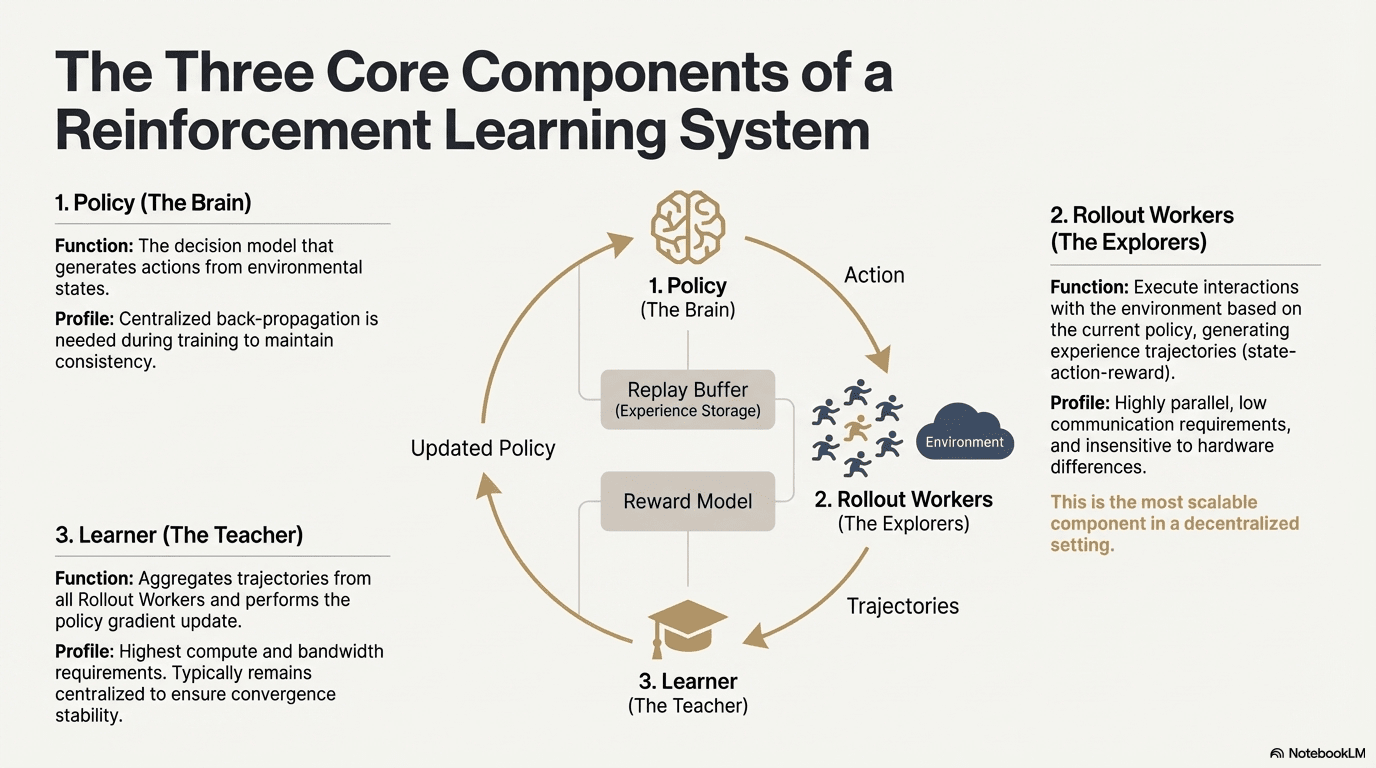
Verstärkendes Lernen ermöglicht es Modellen, die Entscheidungsfindung durch einen Feedbackloop aus Umweltinteraktion, Belohnungssignalen und Politikaktualisierungen zu verbessern. Strukturell besteht ein RL-System aus drei Kernkomponenten: dem Politiknetzwerk, Rollout für Erfahrungssampling und dem Lernenden für die Politikoptimierung. Die Politik generiert Trajektorien durch Interaktion mit der Umwelt, während der Lernende die Politik basierend auf Belohnungen aktualisiert und einen kontinuierlichen iterativen Lernprozess bildet.
Politiknetzwerk (Politik): Generiert Aktionen aus Umweltzuständen und ist der Entscheidungsfindungskern des Systems. Es erfordert zentralisierte Rückpropagation, um die Konsistenz während des Trainings aufrechtzuerhalten; während der Inferenz kann es auf verschiedene Knoten verteilt werden, um parallel zu arbeiten.
Erfahrungssampling (Rollout): Knoten führen Umweltinteraktionen basierend auf der Politik aus und generieren Zustands-Aktions-Belohnungstrajektorien. Dieser Prozess ist hochgradig parallel, hat extrem niedrige Kommunikation, ist unempfindlich gegenüber Hardware-Unterschieden und ist die am besten geeignete Komponente für die Erweiterung in der Dezentralisierung.
Lernender: Aggregiert alle Rollout-Trajektorien und führt Aktualisierungen des Politikgradienten aus. Es ist das einzige Modul mit den höchsten Anforderungen an Rechenleistung und Bandbreite, daher wird es normalerweise zentralisiert oder leicht zentralisiert gehalten, um die Stabilität der Konvergenz zu gewährleisten.
2.2 Rahmen des verstärkenden Lernens
Verstärkendes Lernen kann normalerweise in fünf Phasen unterteilt werden, und der gesamte Prozess sieht wie folgt aus:
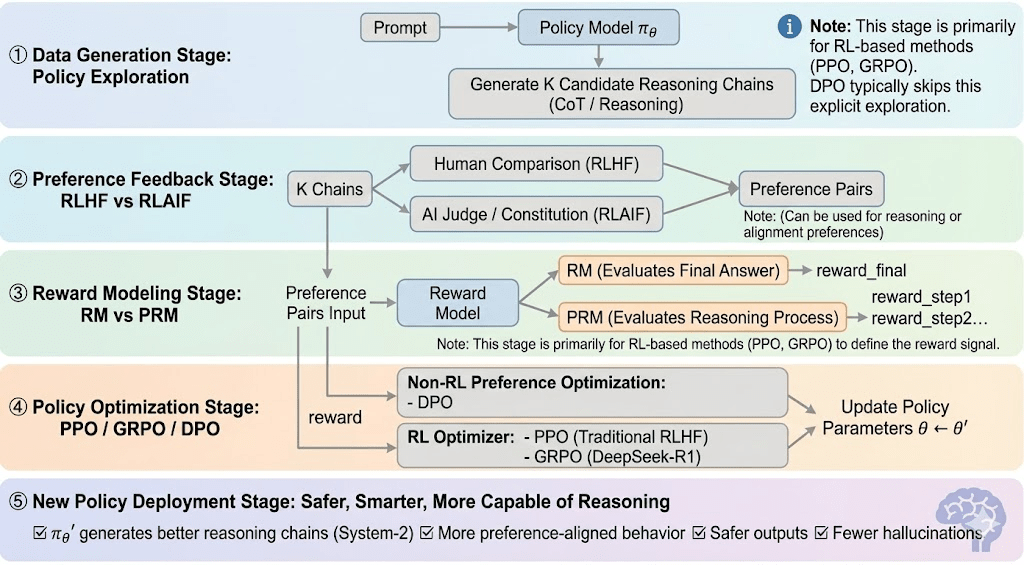
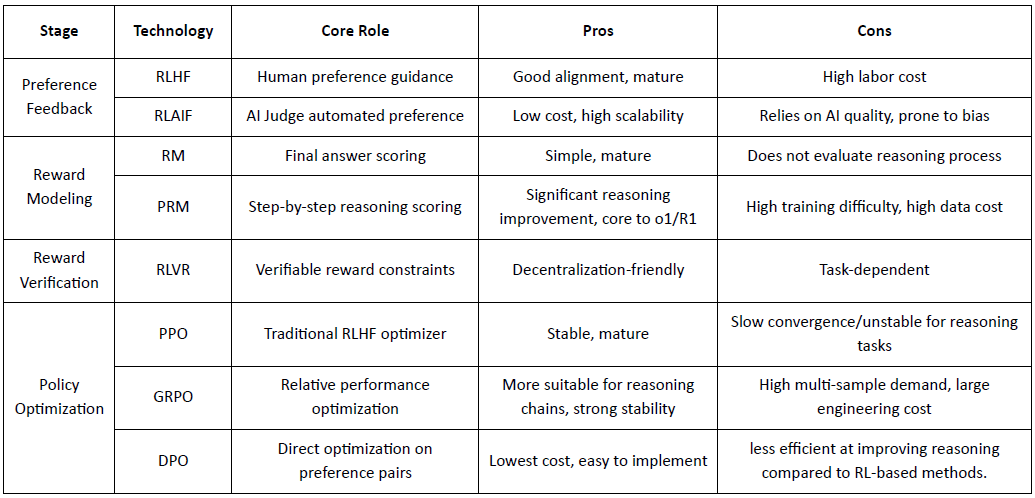
Daten-Generierungsphase (Politikexploration): Gegeben einer Eingabeaufforderung, sampelt die Politik mehrere Denkstränge oder Trajektorien und liefert die Kandidaten für die Präferenzbewertung und Belohnungsmodellierung und definiert den Umfang der Politikexploration.
Präferenz-Feedback-Phase (RLHF / RLAIF):
RLHF (Verstärkendes Lernen aus menschlichem Feedback): trainiert ein Belohnungsmodell aus menschlichen Präferenzen und verwendet dann RL (typischerweise PPO), um die Politik basierend auf diesem Belohnungssignal zu optimieren.
RLAIF (Verstärkendes Lernen aus KI-Feedback): ersetzt Menschen durch KI-Richter oder konstitutionelle Regeln, senkt Kosten und skaliert die Ausrichtung – jetzt der dominierende Ansatz für Anthropic, OpenAI und DeepSeek.
Belohnungsmodellierungsphase (Belohnungsmodellierung): Lernt, Ausgaben basierend auf Präferenzpaaren auf Belohnungen zuzuordnen. RM lehrt das Modell "was die richtige Antwort ist", während PRM das Modell lehrt "wie man korrekt denkt."
RM (Belohnungsmodell): Wird verwendet, um die Qualität der finalen Antwort zu bewerten, und bewertet nur die Ausgabe.
Prozess-Belohnungsmodell (PRM): bewertet schrittweises Denken und trainiert effektiv den Denkprozess des Modells (z. B. in o1 und DeepSeek-R1).
Belohnungsüberprüfung (RLVR / Belohnungsüberprüfbarkeit): Eine Belohnungsüberprüfungsschicht beschränkt Belohnungssignale auf die Ableitung aus reproduzierbaren Regeln, Grundwahrheiten oder Konsensmechanismen. Dies reduziert Belohnungshacking und systematische Voreingenommenheit und verbessert die Auditierbarkeit und Robustheit in offenen und verteilten Trainingsumgebungen.
Politikoptimierungsphase (Politikoptimierung): Aktualisiert Politikparameter $\theta$ unter der Anleitung von Signalen, die vom Belohnungsmodell gegeben werden, um eine Politik $\pi_{\theta'}$ mit stärkeren Denkfähigkeiten, höherer Sicherheit und stabileren Verhaltensmustern zu erhalten. Zu den gängigen Optimierungsmethoden gehören:
PPO (Proximal Policy Optimization): der Standard-RLHF-Optimierer, geschätzt für Stabilität, aber durch langsame Konvergenz bei komplexem Denken eingeschränkt.
GRPO (Gruppenverwandte Politikoptimierung): eingeführt von DeepSeek-R1, optimiert Politiken mithilfe von Gruppen-Advantage-Schätzungen anstelle einfacher Ranglisten, bewahrt den Wert und ermöglicht stabilere Optimierung von Denkketten.
DPO (Direkte Präferenzoptimierung): umgeht RL, indem es direkt auf Präferenzpaaren optimiert – kostengünstig und stabil für die Ausrichtung, aber ineffektiv bei der Verbesserung des Denkens.
Neue Politikbereitstellungsphase (Neue Politikbereitstellung): das aktualisierte Modell zeigt stärkeres System-2-Denken, bessere Präzisionsausrichtung, weniger Halluzinationen und höhere Sicherheit und verbessert sich weiterhin durch iterative Feedbackschleifen.
2.3 Industrielle Anwendungen des verstärkenden Lernens
Verstärkendes Lernen (RL) hat sich von früherer Spielintelligenz zu einem Kernrahmen für autonome Entscheidungsfindung über Branchen hinweg entwickelt. Seine Anwendungsszenarien, basierend auf technologischer Reife und industrieller Implementierung, lassen sich in fünf Hauptkategorien zusammenfassen:
Spiel & Strategie: Die früheste Richtung, in der RL verifiziert wurde. In Umgebungen mit "perfekten Informationen + klaren Belohnungen" wie AlphaGo, AlphaZero, AlphaStar und OpenAI Five hat RL eine Entscheidungsintelligenz gezeigt, die mit der von menschlichen Experten vergleichbar oder überlegen ist, und legt damit die Grundlage für moderne RL-Algorithmen.
Robotik & Verkörperte KI: Durch kontinuierliche Kontrolle, dynamische Modellierung und Umweltinteraktion ermöglicht RL Robotern, Manipulation, Bewegungssteuerung und multimodale Aufgaben (z. B. RT-2, RT-X) zu erlernen. Es bewegt sich schnell in Richtung Industrialisierung und ist ein wichtiger technischer Weg für den Einsatz von Robotern in der realen Welt.
Digitale Denkweise / LLM System-2: RL + PRM treibt große Modelle von "Sprachimitation" zu "strukturiertem Denken." Repräsentative Errungenschaften umfassen DeepSeek-R1, OpenAI o1/o3, Anthropic Claude und AlphaGeometry. Im Wesentlichen führt es Belohnungsoptimierung auf Ebene der Denkketten durch, anstatt nur die finale Antwort zu bewerten.
Wissenschaftliche Entdeckung & Mathematikoptimierung: RL findet optimale Strukturen oder Strategien in label-freien, komplexen Belohnungen und riesigen Suchräumen. Es hat grundlegende Durchbrüche in AlphaTensor, AlphaDev und Fusion RL erzielt und zeigt Erkundungsfähigkeiten, die über menschliche Intuition hinausgehen.
Ökonomische Entscheidungsfindung & Handel: RL wird für Strategieoptimierung, hochdimensionale Risikokontrolle und adaptive Handelssystemgenerierung verwendet. Im Vergleich zu traditionellen quantitativen Modellen kann es kontinuierlich in unsicheren Umgebungen lernen und ist ein wichtiger Bestandteil der intelligenten Finanzen.
III. Natürliche Übereinstimmung zwischen verstärkendem Lernen und Web3
Verstärkendes Lernen und Web3 sind natürlich als anreizgetriebene Systeme ausgerichtet: RL optimiert Verhalten durch Belohnungen, während Blockchains Teilnehmer durch wirtschaftliche Anreize koordinieren. Die Kernbedürfnisse von RL – großflächige heterogene Rollouts, Belohnungsverteilung und überprüfbare Ausführung – stimmen direkt mit den strukturellen Stärken von Web3 überein.
Entkopplung von Denken und Training: Verstärkendes Lernen teilt sich in Rollout- und Aktualisierungsphasen: Rollouts sind rechenintensiv, aber kommunikationsarm und können parallel auf verteilten Verbraucher-GPUs ausgeführt werden, während Aktualisierungen zentrale, hochbandbreitige Ressourcen erfordern. Diese Entkopplung ermöglicht es offenen Netzwerken, Rollouts mit Token-Anreizen zu verwalten, während zentrale Aktualisierungen die Trainingsstabilität aufrechterhalten.
Überprüfbarkeit: ZK (Zero-Knowledge) und Proof-of-Learning bieten Möglichkeiten, zu überprüfen, ob Knoten tatsächlich Denken ausgeführt haben, und lösen das Ehrlichkeitsproblem in offenen Netzwerken. Bei deterministischen Aufgaben wie Code- und mathematischem Denken müssen Prüfer nur die Antwort überprüfen, um die Arbeitslast zu bestätigen, was die Glaubwürdigkeit dezentraler RL-Systeme erheblich verbessert.
Anreisschicht, tokenökonomie-basiertes Feedbackproduktionsmechanismus: Web3-Tokenanreize können direkt RLHF/RLAIF-Feedbackbeiträger belohnen, was eine transparente, erlaubnisfreie Präferenzgenerierung ermöglicht, wobei Staking und Slashing die Qualität effizienter durchsetzen als traditionelle Crowdsourcing-Methoden.
Potenzial für Multi-Agenten-Verstärkendes Lernen (MARL): Blockchains bilden offene, anreizegetriebene Multi-Agenten-Umgebungen mit öffentlichem Zustand, überprüfbarer Ausführung und programmierbaren Anreizen, was sie zu einem natürlichen Testfeld für großflächiges MARL macht, obwohl das Feld noch in den Anfängen steckt.
IV. Analyse der Web3 + Verstärkendes Lernen-Projekte
Basierend auf dem obigen theoretischen Rahmen werden wir die derzeit repräsentativsten Projekte im aktuellen Ökosystem kurz analysieren:
Prime Intellect: Asynchrones Verstärkendes Lernen prime-rl
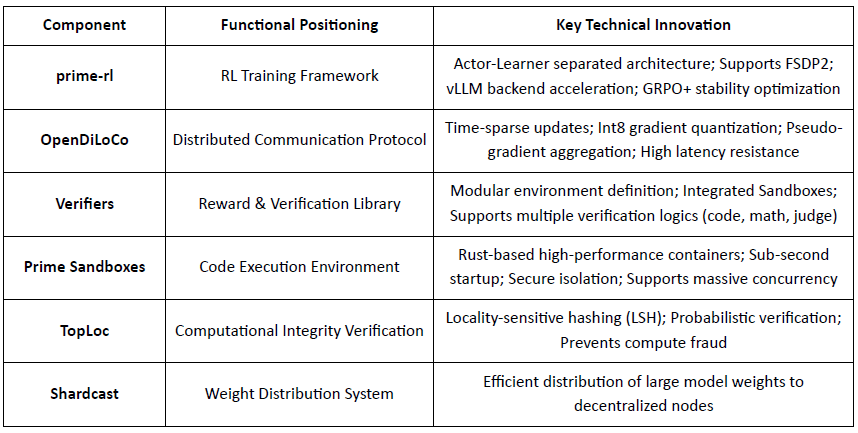
Prime Intellect zielt darauf ab, einen offenen globalen Compute-Markt und einen Open-Source-Superintelligenz-Stack aufzubauen, der Prime Compute, die INTELLECT-Modellfamilie, offene RL-Umgebungen und großflächige synthetische Datenmaschinen umfasst. Sein prim-rl-Rahmenwerk ist gezielt für asynchrones verteiltes RL entwickelt, ergänzt durch OpenDiLoCo für bandbreiteneffizientes Training und TopLoc für die Verifizierung.
Übersicht über die Kerninfrastrukturkomponenten von Prime Intellect
Technische Grundlage: prime-rl Asynchrones Verstärkendes Lernframework
prime-rl ist die Kerntrainingsmaschine von Prime Intellect, entworfen für großflächige asynchrone dezentrale Umgebungen. Es erreicht hochdurchsatzfähige Inferenz und stabile Updates durch vollständige Entkopplung von Actor–Learner. Ausführer (Rollout-Arbeiter) und Lernende (Trainer) blockieren sich nicht synchron. Knoten können jederzeit beitreten oder verlassen, müssen nur kontinuierlich die neueste Politik abrufen und generierte Daten hochladen:
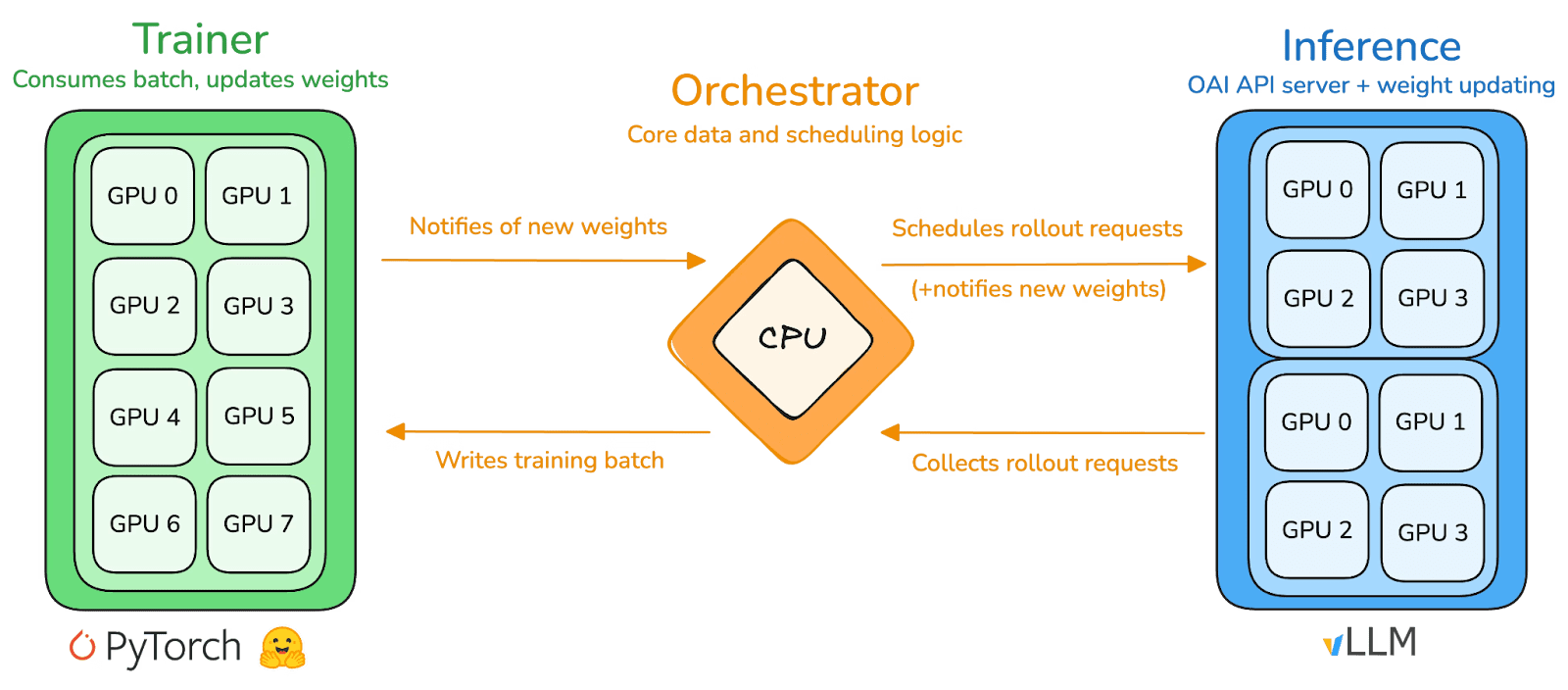
Actor (Rollout-Arbeiter): Verantwortlich für die Modellinferenz und Datengenerierung. Prime Intellect hat innovativ die vLLM-Inferenz-Engine am Actor-Ende integriert. Die PagedAttention-Technologie von vLLM und die kontinuierliche Batch-Verarbeitung ermöglichen es den Akteuren, Inferenztrajektorien mit extrem hohem Durchsatz zu generieren.
Lernender (Trainer): Verantwortlich für die Politikoptimierung. Der Lernende zieht asynchron Daten aus dem gemeinsamen Erfahrungspuffer für Gradient-Updates, ohne darauf zu warten, dass alle Akteure den aktuellen Batch abgeschlossen haben.
Orchestrator: Verantwortlich für die Planung von Modellgewichten und Datenfluss.
Schlüsselinnovationen von prime-rl:
Echte Asynchronität: prime-rl hat das traditionelle synchrone Paradigma von PPO aufgegeben, wartet nicht auf langsame Knoten und erfordert keine Batch-Ausrichtung, wodurch jede Anzahl und Leistung von GPUs jederzeit zugänglich ist und die Machbarkeit von dezentralem RL etabliert wird.
Tiefe Integration von FSDP2 und MoE: Durch FSDP2-Parameter-Sharding und MoE-spärliche Aktivierung ermöglicht prime-rl, dass Modelle mit zig Milliarden von Parametern effizient in verteilten Umgebungen trainiert werden. Akteure führen nur aktive Experten aus, was die VRAM- und Inferenzkosten erheblich senkt.
GRPO+ (Gruppenverwandte Politikoptimierung): GRPO beseitigt das Kritiker-Netzwerk, was die Berechnung und den VRAM-Overhead erheblich reduziert und sich natürlich an asynchrone Umgebungen anpasst. Das GRPO+ von prime-rl gewährleistet zuverlässigen Konvergenz unter Bedingungen hoher Latenz durch Stabilisierungsmethoden.
INTELLECT-Modellfamilie: Ein Symbol für die Reife der dezentralen RL-Technologie
INTELLECT-1 (10B, Okt 2024): Beweis dafür, dass OpenDiLoCo zum ersten Mal effizient in einem heterogenen Netzwerk über drei Kontinente hinweg trainieren kann (Kommunikationsanteil < 2 %, Rechenauslastung 98 %), und damit die physischen Wahrnehmungen des grenzüberschreitenden Trainings durchbricht.
INTELLECT-2 (32B, Apr 2025): Als erstes erlaubnisfreies RL-Modell validiert es die stabile Konvergenzfähigkeit von prime-rl und GRPO+ in mehrstufigen Latenz- und asynchronen Umgebungen und verwirklicht dezentrales RL mit globaler offener Rechenbeteiligung.
INTELLECT-3 (106B MoE, Nov 2025): Adoptiert eine spärliche Architektur, die nur 12B Parameter aktiviert, trainiert auf 512×H200 und erreicht eine Spitzenleistungsfähigkeit bei der Inferenz (AIME 90,8 %, GPQA 74,4 %, MMLU-Pro 81,9 % usw.). Die Gesamtleistung nähert sich oder übertrifft zentralisierte Closed-Source-Modelle, die viel größer sind als sie selbst.
Prime Intellect hat einen vollständigen dezentralisierten RL-Stack aufgebaut: OpenDiLoCo reduziert den Trainingsverkehr über Regionen um Größenordnungen, während es ~98 % Auslastung über Kontinente aufrechterhält; TopLoc und Verifizierer gewährleisten vertrauenswürdige Inferenz und Belohnungsdaten über Aktivierungsfingerabdrücke und sandboxed Verifizierung; und die SYNTHETIC-Datenmaschine generiert hochwertige Denkstränge, während sie es großen Modellen ermöglicht, effizient auf Verbraucher-GPUs über Pipeline-Parallelismus zu laufen. Zusammen bilden diese Komponenten skalierbare Datengenerierung, Verifizierung und Inferenz im dezentralen RL, wobei die INTELLECT-Serie zeigt, dass solche Systeme in der Praxis Weltklasse-Modelle liefern können.
Gensyn: RL-Core-Stack RL Swarm und SAPO
Gensyn strebt danach, globale inaktive Rechenleistung in ein vertrauensloses, skalierbares KI-Trainingsnetzwerk zu vereinen, das standardisierte Ausführung, P2P-Koordination und on-chain-Aufgabenverifizierung kombiniert. Durch Mechanismen wie RL Swarm, SAPO und SkipPipe entkoppelt es Generierung, Bewertung und Updates über heterogene GPUs und liefert nicht nur Rechenleistung, sondern überprüfbare Intelligenz.
RL-Anwendungen im Gensyn-Stack
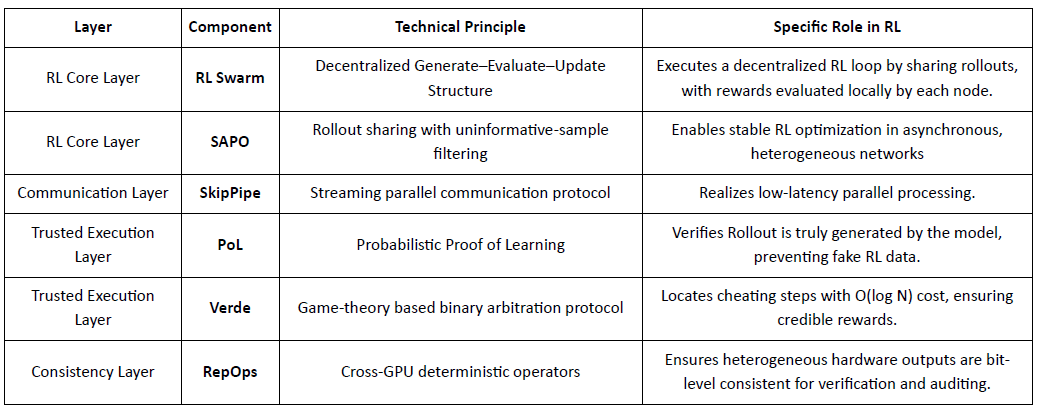
RL Swarm: Dezentralisierte kollaborative Verstärkende Lern-Engine
RL Swarm demonstriert einen brandneuen Kollaborationsmodus. Es handelt sich nicht mehr um einfache Aufgabenverteilung, sondern um eine unendliche Schleife eines dezentralen Generierens–Bewertens–Aktualisierens, inspiriert von kollaborativem Lernen, das menschliches soziales Lernen simuliert:
Solver (Ausführer): Verantwortlich für lokale Modellinferenz und Rollout-Generierung, unbeeinträchtigt von der Heterogenität der Knoten. Gensyn integriert lokal Hochdurchsatz-Inferenzmaschinen (wie CodeZero), um vollständige Trajektorien anstelle nur von Antworten auszugeben.
Vorschlagende: Generieren dynamisch Aufgaben (Mathematikprobleme, Codefragen usw.), die Aufgabenvielfalt und curriculum-ähnliche Anpassung ermöglichen, um die Trainingsschwierigkeit an die Modellfähigkeiten anzupassen.
Bewertende: Verwenden eingefrorene "Richtermodelle" oder Regeln, um die Ausgabequalität zu überprüfen, und bilden lokale Belohnungssignale, die unabhängig von jedem Knoten bewertet werden. Der Bewertungsprozess kann auditiert werden, was den Raum für Bosheit verringert.
Die drei bilden eine P2P-RL-Organisationsstruktur, die großflächiges kollaboratives Lernen ohne zentrale Planung abschließen kann.
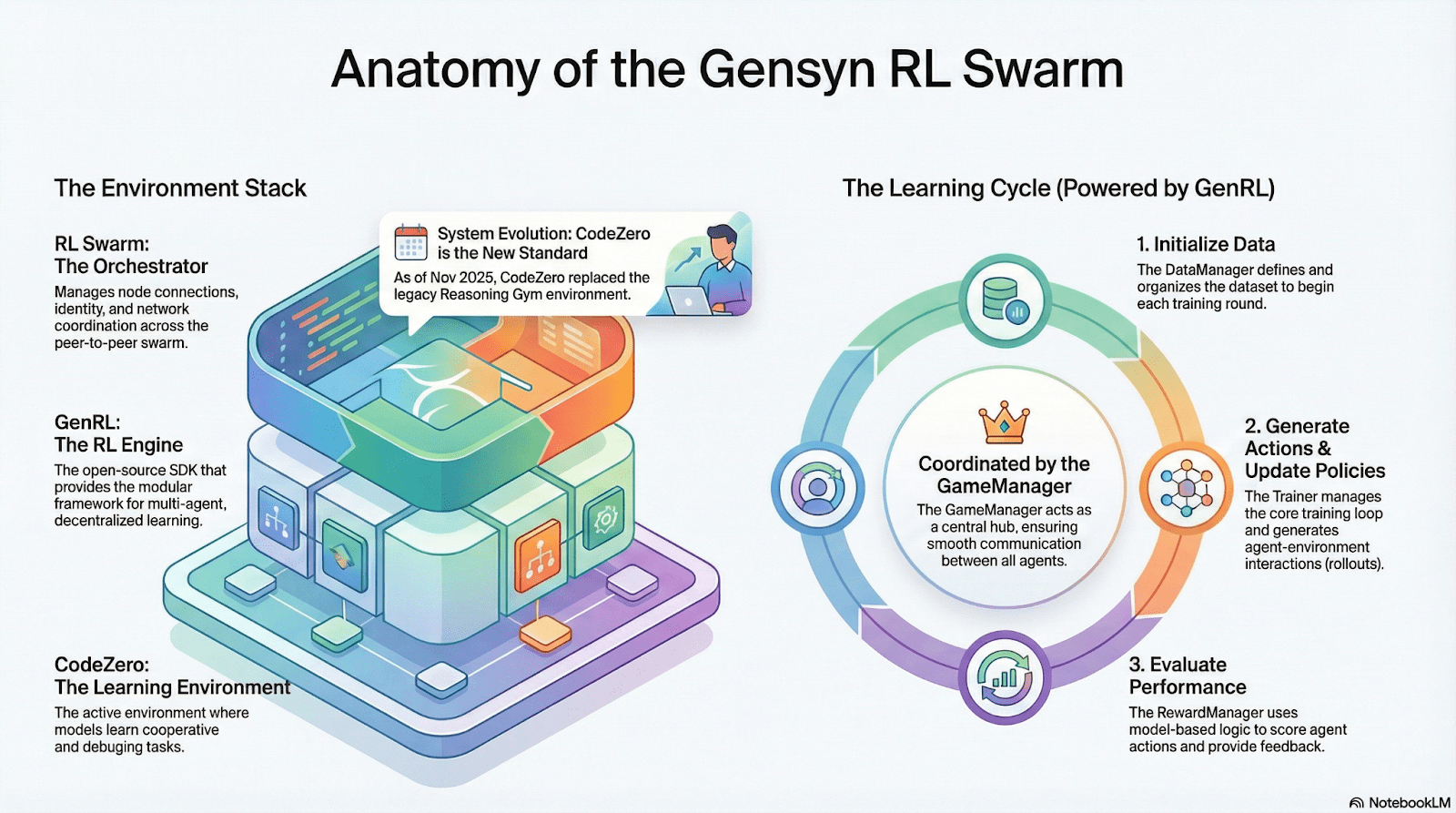
SAPO: Politikoptimierungsalgorithmus umgebaut für Dezentralisierung
SAPO (Swarm Sampling Policy Optimization) konzentriert sich auf das Teilen von Rollouts, während es diejenigen ohne Gradientensignal filtert, anstatt Gradienten zu teilen. Durch die Ermöglichung großflächiger dezentraler Rollout-Sampling und die Behandlung empfangener Rollouts als lokal generiert, hält SAPO die stabile Konvergenz in Umgebungen ohne zentrale Koordination und mit signifikanten Knotenlatenz-Heterogenitäten aufrecht. Im Vergleich zu PPO (das auf einem Kritiker-Netzwerk basiert, das die Rechenkosten dominiert) oder GRPO (das auf Gruppen-Advantage-Schätzungen basiert und nicht auf einfachen Ranglisten) ermöglicht SAPO, dass Verbraucher-GPUs effektiv an großflächigen RL-Optimierungen mit extrem geringen Bandbreitenanforderungen teilnehmen.
Durch RL Swarm und SAPO zeigt Gensyn, dass verstärkendes Lernen – insbesondere das Post-Training RLVR – sich natürlich für dezentrale Architekturen eignet, da es mehr von vielfältiger Erkundung über Rollouts abhängt als von hochfrequenten Parametersynchronisationen. In Kombination mit PoL- und Verde-Verifizierungssystemen bietet Gensyn einen alternativen Weg zum Training von Billionen-Parameter-Modellen: ein sich selbst entwickelndes Superintelligenznetzwerk, das aus Millionen heterogener GPUs weltweit besteht.
Nous Research: Verstärkende Lernumgebung Atropos
Nous Research baut einen dezentralisierten, sich selbst entwickelnden kognitiven Stapel auf, in dem Komponenten wie Hermes, Atropos, DisTrO, Psyche und World Sim ein geschlossenes intelligentes System bilden. Durch den Einsatz von RL-Methoden wie DPO, GRPO und Ablehnungssampling ersetzt es lineare Trainingspipelines durch kontinuierliches Feedback über Datengenerierung, Lernen und Inferenz.
Übersicht über die Nous Research Komponenten
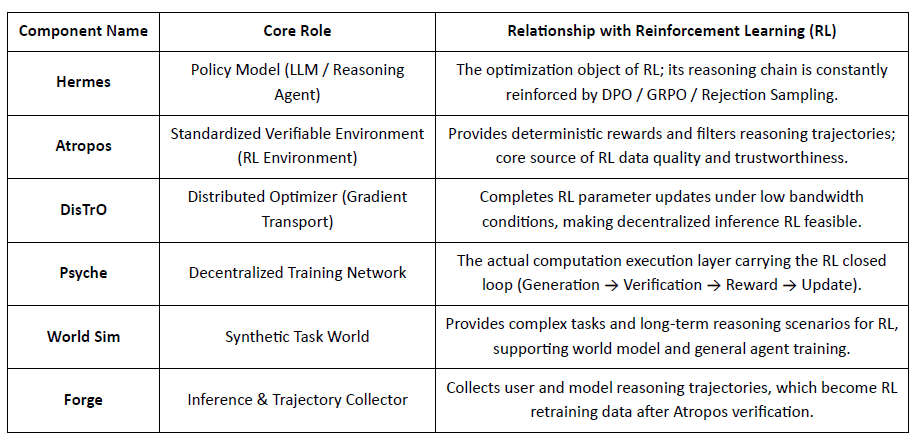
Modellschicht: Hermes und die Evolution der Denkfähigkeiten
Die Hermes-Serie ist die Hauptmodell-Schnittstelle von Nous Research, die sich an Benutzer richtet. Ihre Evolution zeigt deutlich den Industrieweg, der von traditioneller SFT/DPO-Ausrichtung zu Reasoning RL migriert:
Hermes 1–3: Anweisungs-Ausrichtung & Frühe Agentenfähigkeiten: Hermes 1–3 stützte sich auf kostengünstige DPO für robuste Anweisungsausrichtung und nutzte synthetische Daten und die erste Einführung von Atropos-Verifizierungsmechanismen in Hermes 3.
Hermes 4 / DeepHermes: Schreibt System-2-Stil langsames Denken in Gewichte über Chain-of-Thought, verbessert Mathematik- und Codeleistungen mit Test-Time-Scaling und verlässt sich auf "Ablehnungs-Sampling + Atropos-Verifizierung", um hochreine Denkdaten zu erstellen.
DeepHermes übernimmt weiter GRPO, um PPO zu ersetzen (das hauptsächlich schwer zu implementieren ist), und ermöglicht es Reasoning RL, im Psyche-dezentralen GPU-Netzwerk zu laufen, wodurch die ingenieurtechnische Grundlage für die Skalierbarkeit von Open-Source-Reasoning RL gelegt wird.
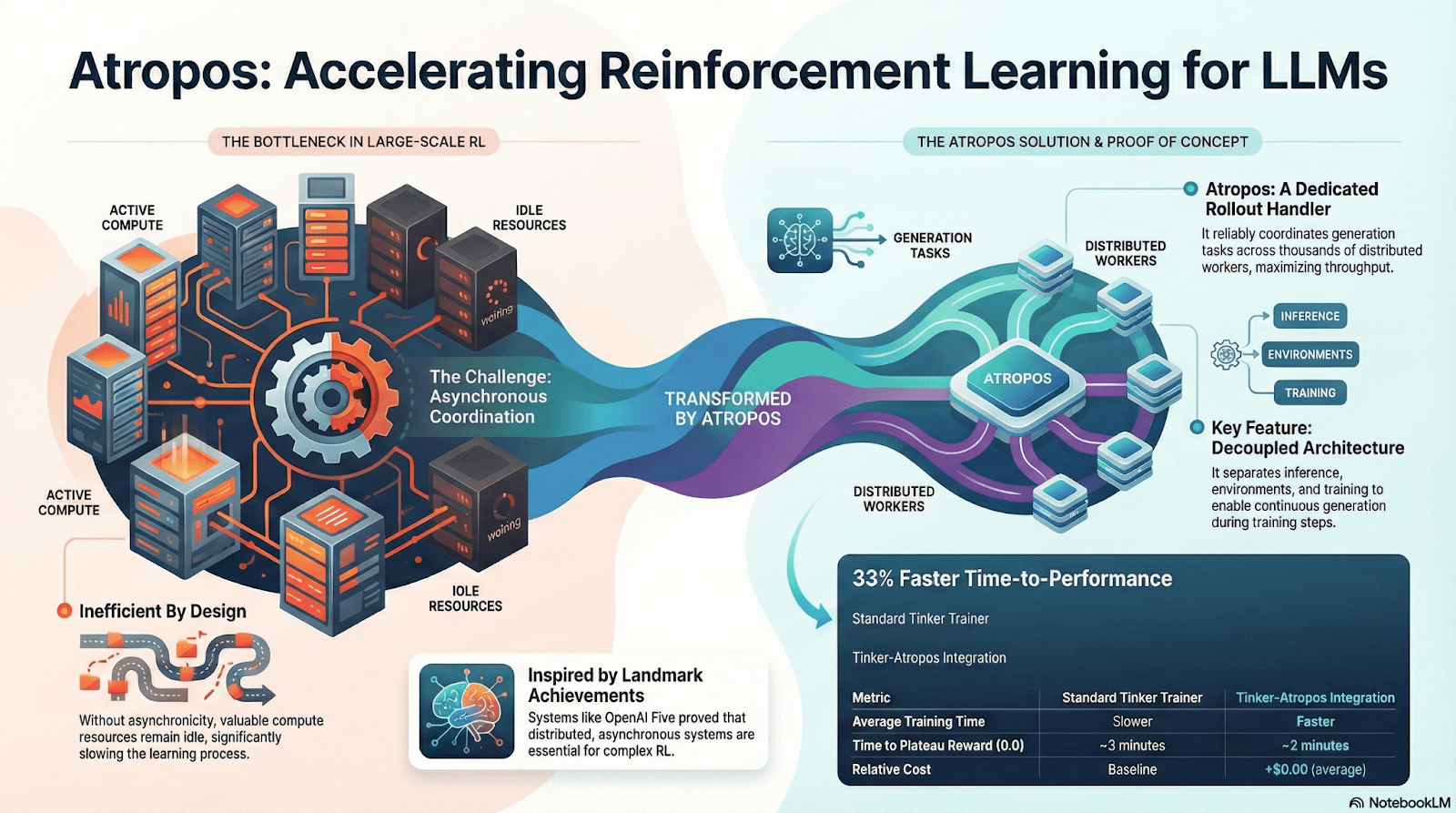
Atropos: Überprüfbare Belohnungsgetriebene Verstärkende Lernumgebung
Atropos ist der wahre Knotenpunkt des Nous RL-Systems. Es kapselt Eingabeaufforderungen, Werkzeugaufrufe, Codeausführungen und Mehr-Runden-Interaktionen in einer standardisierten RL-Umgebung und überprüft direkt, ob die Ausgaben korrekt sind, wodurch deterministische Belohnungssignale bereitgestellt werden, um teure und nicht skalierbare menschliche Kennzeichnungen zu ersetzen. Noch wichtiger ist, dass Atropos im dezentralen Trainingsnetzwerk Psyche als "Richter" fungiert, um zu überprüfen, ob Knoten die Politik tatsächlich verbessert haben, was auditable Beweise für das Lernen unterstützt und das Problem der Glaubwürdigkeit von Belohnungen im verteilten RL grundlegend löst.
DisTrO und Psyche: Optimierungsschicht für dezentrales verstärkendes Lernen
Traditionelles RLF (RLHF/RLAIF) Training basiert auf zentralisierten Hochbandbreiten-Clustern, einem zentralen Hindernis, das Open Source nicht replizieren kann. DisTrO reduziert die RL-Kommunikationskosten um Größenordnungen durch Momentum-Entkopplung und Gradientenkompression, wodurch das Training über Internet-Bandbreite durchgeführt werden kann; Psyche setzt diesen Trainingsmechanismus in einem on-chain-Netzwerk ein, das es Knoten ermöglicht, Inferenz, Verifizierung, Belohnungsbewertung und Gewichtserneuerungen lokal abzuschließen, wodurch ein vollständiger RL-geschlossener Kreislauf gebildet wird.
Im Nous-System überprüft Atropos Gedankenketten; DisTrO komprimiert die Trainingskommunikation; Psyche führt die RL-Schleife aus; World Sim bietet komplexe Umgebungen; Forge sammelt echtes Denken; Hermes schreibt alles Lernen in Gewichte. Verstärkendes Lernen ist nicht nur eine Trainingsphase, sondern das zentrale Protokoll, das Daten, Umwelt, Modelle und Infrastruktur in der Nous-Architektur verbindet und Hermes zu einem lebendigen System macht, das fähig ist, sich kontinuierlich selbst zu verbessern in einem offenen Rechen-Netzwerk.
Gradient-Netzwerk: Verstärkendes Lernarchitektur Echo
Das Gradient-Netzwerk zielt darauf ab, KI-Berechnungen über einen Open Intelligence Stack neu aufzubauen: ein modulares Set interoperabler Protokolle, das P2P-Kommunikation (Lattica), verteilte Inferenz (Parallax), dezentrales RL-Training (Echo), Verifizierung (VeriLLM), Simulation (Mirage) und höherwertige Speicher- und Agentenkoordination umfasst – zusammen bilden sie eine sich entwickelnde dezentrale Intelligenzinfrastruktur.
Echo — Architektur für verstärktes Lernen
Echo ist Gradients Rahmen für verstärkendes Lernen. Sein zentrales Designprinzip liegt in der Entkopplung von Training, Inferenz und Daten (Belohnungs-) Wegen im verstärkenden Lernen, die getrennt in heterogenen Inferenz- und Trainingsschwärmen betrieben werden, wobei ein stabiles Optimierungsverhalten über weiträumige heterogene Umgebungen mit leichten Synchronisationsprotokollen aufrechterhalten wird. Dies mildert effektiv die SPMD-Fehler und Engpässe bei der GPU-Nutzung, die durch die Vermischung von Inferenz und Training in traditionellem DeepSpeed RLHF / VERL verursacht werden.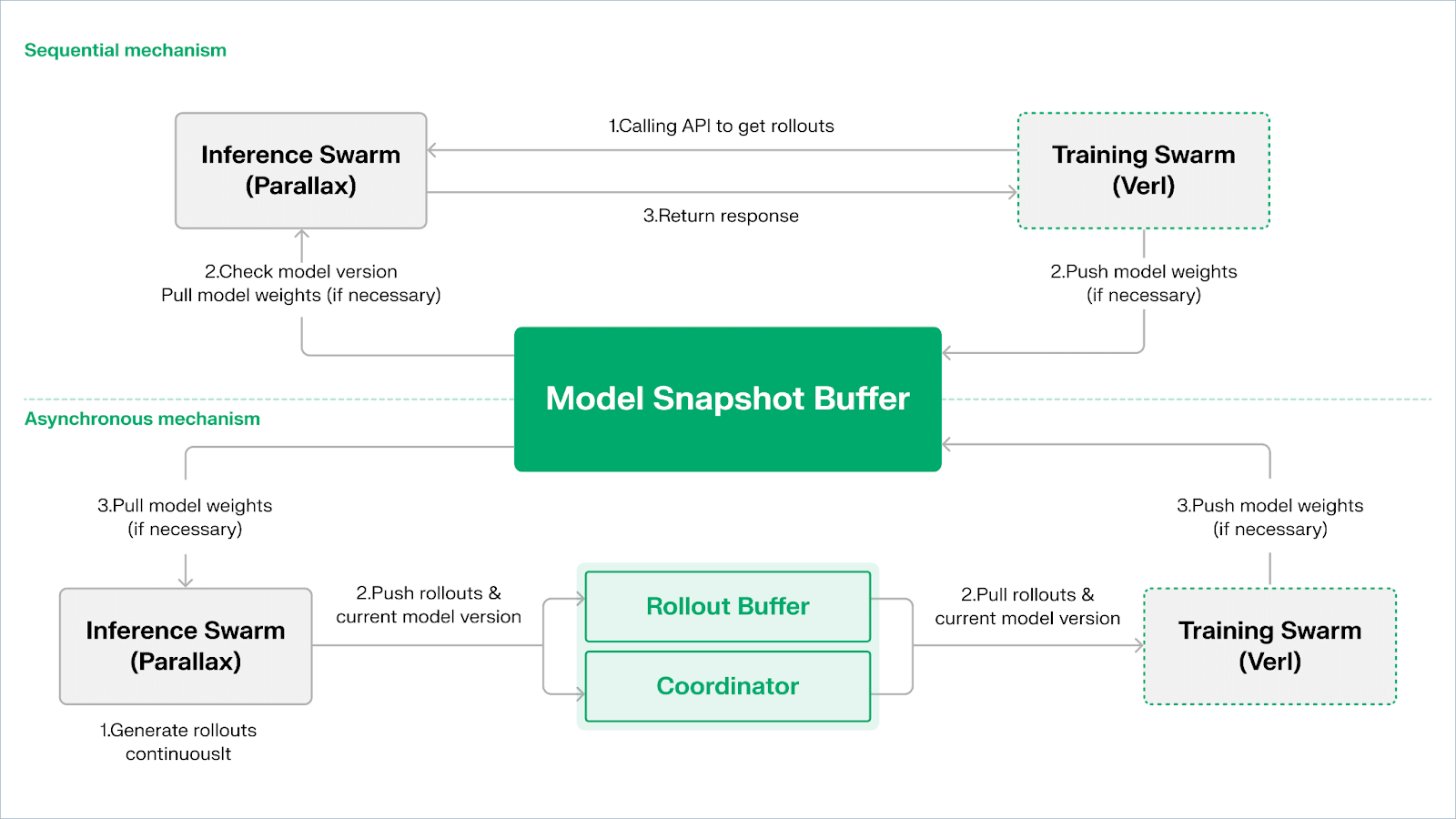
Echo verwendet eine "Inferenz-Trainings-Dual-Schwarm-Architektur", um die Nutzung der Rechenleistung zu maximieren. Die beiden Schwärme laufen unabhängig voneinander, ohne sich gegenseitig zu blockieren:
Maximiere Sampling-Durchsatz: Der Inferenzschwarm besteht aus Verbraucher-GPUs und Edge-Geräten, die hochdurchsatzfähige Sampler über Pipeline-parallel mit Parallax erstellen, wobei der Fokus auf der Trajektoriengenerierung liegt.
Maximiere Gradient-Rechenleistung: Der Trainingsschwarm kann auf zentralisierten Clustern oder global verteilten Verbraucher-GPU-Netzwerken laufen, verantwortlich für Gradient-Aktualisierungen, Parameter-Synchronisation und LoRA-Fine-Tuning, mit dem Fokus auf den Lernprozess.
Um die Konsistenz von Politik und Daten aufrechtzuerhalten, bietet Echo zwei Arten von leichten Synchronisationsprotokollen: Sequential und Asynchronous, die die bidirektionale Konsistenz von Politikgewichten und Trajektorien verwalten:
Sequentieller Zugmodus (Genauigkeit zuerst): Die Trainingsseite zwingt Inferenzknoten, die Modellversion zu aktualisieren, bevor sie neue Trajektorien abrufen, um die Frische der Trajektorien sicherzustellen, geeignet für Aufgaben, die sehr empfindlich auf die Alterung von Politiken reagieren.
Asynchroner Push-Pull-Modus (Effizienz zuerst): Die Inferenzseite generiert kontinuierlich Trajektorien mit Versions-Tags, und die Trainingsseite konsumiert sie in ihrem eigenen Tempo. Der Koordinator überwacht die Versionsabweichung und löst Gewichtserneuerungen aus, um die Geräteeffizienz zu maximieren.
In der untersten Schicht basiert Echo auf Parallax (heterogene Inferenz in Umgebungen mit geringer Bandbreite) und leichten verteilten Trainingskomponenten (z. B. VERL), die auf LoRA angewiesen sind, um die Kosten für die Synchronisation zwischen Knoten zu reduzieren, sodass verstärkendes Lernen stabil in globalen heterogenen Netzwerken ausgeführt werden kann.
Grail: Verstärkendes Lernen im Bittensor-Ökosystem
Bittensor konstruiert ein riesiges, spärliches, nicht-stationäres Belohnungsfunktionsnetzwerk durch seinen einzigartigen Yuma-Konsensmechanismus.
Covenant AI im Bittensor-Ökosystem baut eine vertikal integrierte Pipeline vom Pre-Training bis zum RL-Post-Training durch SN3 Templar, SN39 Basilica und SN81 Grail auf. Unter ihnen ist SN3 Templar für das Pre-Training des Basismodells verantwortlich, SN39 Basilica bietet einen Markt für verteilte Rechenleistung, und SN81 Grail fungiert als "überprüfbare Inferenzschicht" für das RL-Post-Training und trägt die Kernprozesse von RLHF / RLAIF und vervollständigt die geschlossene Optimierung vom Basismodell zur ausgerichteten Politik.

GRAIL verifiziert kryptographisch RL-Rollouts und bindet sie an die Modellidentität, was vertrauensloses RLHF ermöglicht. Es verwendet deterministische Herausforderungen, um Vorberechnungen, kostengünstiges Sampling und Verpflichtungen zu verhindern, um Rollouts zu überprüfen, und Modell-Fingerprinting, um Substitution oder Replay zu erkennen – und sorgt so für die End-to-End-Echtheit von RL-Inferenztrajektorien.
Das Subnetz von Grail implementiert eine überprüfbare GRPO-Stil-Post-Training-Schleife: Miner produzieren mehrere Denkpfade, Validatoren bewerten Richtigkeit und Denkqualität, und normierte Ergebnisse werden on-chain geschrieben. Öffentliche Tests steigerten die Qwen2.5-1.5B MATH-Genauigkeit von 12,7 % auf 47,6 %, was sowohl Betrugsresistenz als auch starke Leistungsgewinne zeigt; in Covenant AI fungiert Grail als das Vertrauens- und Ausführungszentrum für dezentrales RLVR/RLAIF.
Fraction AI: Wettbewerbsbasiertes Verstärkendes Lernen RLFC
Fraction AI stellt die Ausrichtung als Verstärkendes Lernen aus Wettbewerb um, indem es gamifizierte Kennzeichnung und Agenten-gegen-Agenten-Wettkämpfe nutzt. Relative Rangordnungen und KI-Richterbewertungen ersetzen statische menschliche Labels und verwandeln RLHF in ein kontinuierliches, wettbewerbsfähiges Mehr-Agenten-Spiel.
Kernunterschiede zwischen traditionellem RLHF und Fraction AIs RLFC:
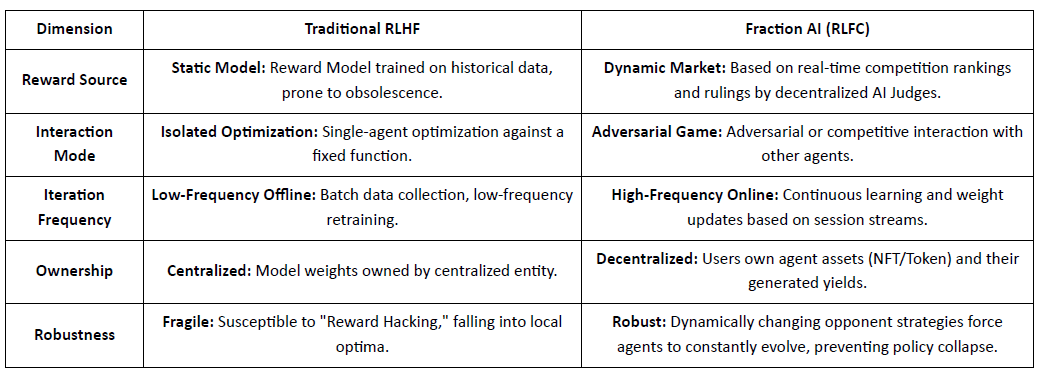
Der Kernwert von RLFC ist, dass Belohnungen von sich entwickelnden Gegnern und Bewertenden kommen, nicht von einem einzigen Modell, wodurch Belohnungshacking reduziert und die Diversität von Politiken bewahrt wird. Das Design des Raums gestaltet die Dynamik des Spiels und ermöglicht komplexe wettbewerbliche und kooperative Verhaltensweisen.
In der Systemarchitektur zerlegt Fraction AI den Trainingsprozess in vier Schlüsselkomponenten:
Agenten: Leichte politische Einheiten basierend auf Open-Source-LLMs, erweitert über QLoRA mit differenziellen Gewichten für kostengünstige Updates.
Räume: Isolierte Aufgabenbereich-Umgebungen, in denen Agenten bezahlen, um einzutreten und durch Gewinnen Belohnungen zu verdienen.
KI-Richter: Sofortige Belohnungsschicht, die mit RLAIF erstellt wurde und skalierbare, dezentrale Bewertungen bereitstellt.
Proof-of-Learning: Bindet Politikupdates an spezifische Wettbewerbsergebnisse, um sicherzustellen, dass der Trainingsprozess überprüfbar und betrugsresistent ist.
Fraction AI funktioniert als menschlich-maschinelles Ko-Evolutionswerkzeug: Benutzer agieren als Meta-Optimierer, die die Erkundung leiten, während Agenten konkurrieren, um qualitativ hochwertige Präferenzdaten zu generieren, was vertrauensloses, kommerzialisiertes Feintuning ermöglicht.
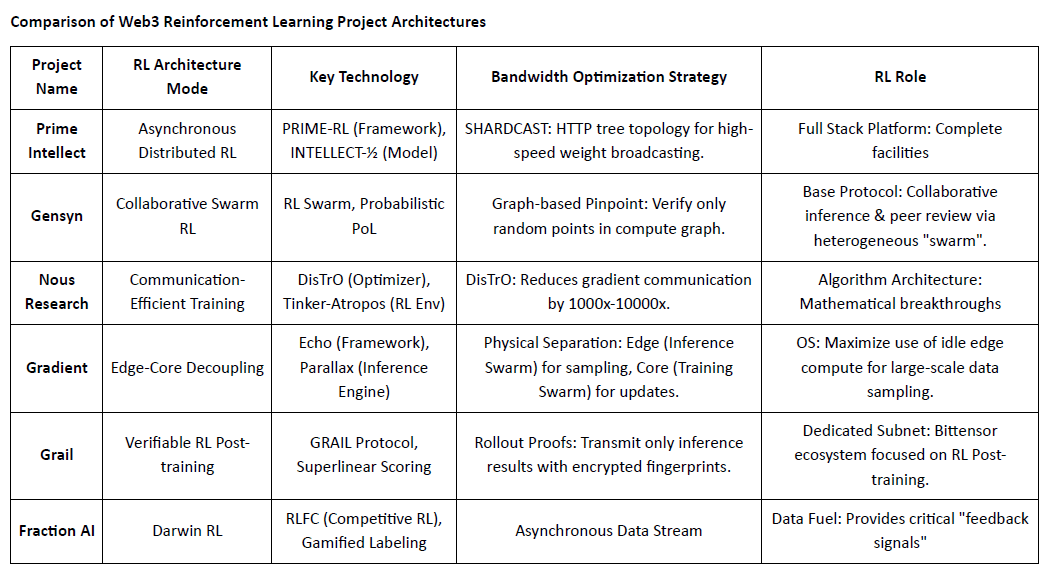
Vergleich der Architekturen von Web3-Verstärkendem Lernen-Projekten
V. Der Weg und die Gelegenheit des Verstärkenden Lernens × Web3
In diesen Grenzprojekten konvergieren, trotz unterschiedlicher Einstiegspunkte, RL und Web3 konsequent auf eine gemeinsame "Entkopplungs–Verifizierungs–Anreiz"-Architektur – ein unvermeidliches Ergebnis der Anpassung des verstärkenden Lernens an dezentrale Netzwerke.
Allgemeine Architekturmerkmale des verstärkenden Lernens: Lösung der grundlegenden physischen Grenzen und Vertrauensprobleme
Entkopplung von Rollouts & Lernen (Physische Trennung von Inferenz/Training) — Standard-Computing-Topologie: Kommunikationssparsame, parallelisierbare Rollouts werden an globale Verbraucher-GPUs ausgelagert, während hochbandbreitige Parameteraktualisierungen in wenigen Trainingsknoten konzentriert werden. Dies gilt vom asynchronen Actor–Learner von Prime Intellect bis zur Dual-Schwarm-Architektur von Gradient Echo.
Verifikationsgetriebenes Vertrauen — Infrastrukturalisierung: In erlaubnisfreien Netzwerken muss die rechnerische Authentizität durch Mathematik und Mechanismusdesign zwangsweise garantiert werden. Repräsentative Implementierungen umfassen Gensyns PoL, Prime Intellects TopLoc und Grails kryptographische Verifizierung.
Tokenisierte Anreizschleife — Marktselbstregulierung: Rechenangebot, Datengenerierung, Überprüfungs-sortierung und Belohnungsverteilung bilden einen geschlossenen Kreislauf. Belohnungen treiben die Teilnahme an, und Slashing unterdrückt Betrug, wodurch das Netzwerk stabil bleibt und sich kontinuierlich in einer offenen Umgebung weiterentwickelt.
Differenzierte technische Pfade: Unterschiedliche "Durchbruchspunkte" unter konsistenter Architektur
Obwohl sich die Architekturen annähern, wählen Projekte unterschiedliche technische Gräben basierend auf ihrer DNA:
Algorithmus Durchbruchschule (Nous Research): Bekämpft die Bandbreitenengpass beim verteilten Training auf der Optimierungsebene – DisTrO komprimiert die Gradientkommunikation um Größenordnungen, mit dem Ziel, das Training großer Modelle über das heimische Breitband zu ermöglichen.
Systemtechnikschule (Prime Intellect, Gensyn, Gradient): Konzentriert sich auf den Aufbau des nächsten "KI-Runtime-Systems." Prime Intellects ShardCast und Gradients Parallax sind darauf ausgelegt, die höchste Effizienz aus heterogenen Clustern unter bestehenden Netzwerkbedingungen durch extreme Ingenieurmethoden herauszuholen.
Marktspielschule (Bittensor, Fraction AI): Konzentriert sich auf das Design von Belohnungsfunktionen. Durch die Gestaltung ausgeklügelter Bewertungsmechanismen führen sie Miner dazu, spontan optimale Strategien zu finden, um die Entstehung von Intelligenz zu beschleunigen.
Vorteile, Herausforderungen und Ausblick auf das Endspiel
Im Paradigma des verstärkenden Lernens kombiniert mit Web3 zeigen sich die systemischen Vorteile zunächst in der Neugestaltung von Kostenstrukturen und Governance-Strukturen.
Kostenumgestaltung: RL-Post-Training hat eine unbegrenzte Nachfrage nach Sampling (Rollout). Web3 kann globale Langschwanz-Rechenleistung zu extrem niedrigen Kosten mobilisieren, einen Kostenvorteil, den zentralisierte Cloud-Anbieter schwer erreichen können.
Souveräne Ausrichtung: Durchbrechen des Monopols großer Technologieunternehmen über KI-Werte (Ausrichtung). Die Gemeinschaft kann entscheiden, "was eine gute Antwort" für das Modell ist, indem sie Token-Abstimmungen durchführt, und damit die Demokratisierung der KI-Governance verwirklichen.
Gleichzeitig steht dieses System vor zwei strukturellen Einschränkungen:
Bandbreitenwand: Trotz Innovationen wie DisTrO begrenzt die physische Latenz immer noch das vollständige Training von ultra-großen Parameter-Modellen (70B+). Derzeit ist Web3 KI eher auf Feinabstimmung und Inferenz beschränkt.
Belohnungshacking (Goodhart's Gesetz): In hochgradig incentivierten Netzwerken sind Miner extrem anfällig für "Überanpassung" an Belohnungsregeln (das System ausnutzen), anstatt die tatsächliche Intelligenz zu verbessern. Die Gestaltung betrugsresistenter robuster Belohnungsfunktionen ist ein ewiges Spiel.
Böswillige byzantinische Arbeiter: beziehen sich auf die absichtliche Manipulation und Vergiftung von Trainingssignalen, um die Modellkonvergenz zu stören. Die zentrale Herausforderung besteht nicht in der kontinuierlichen Gestaltung betrugsresistenter Belohnungsfunktionen, sondern in Mechanismen mit adversarialer Robustheit.
RL und Web3 gestalten Intelligenz über dezentrale Rollout-Netzwerke, on-chain assetisierte Feedbacks und vertikale RL-Agenten mit direkter Wertschöpfung um. Die wahre Gelegenheit liegt nicht in einem dezentralen OpenAI, sondern in neuen Intelligenzproduktionsbeziehungen – offenen Compute-Märkten, governierbaren Belohnungen und Präferenzen sowie gemeinsamem Wert über Trainer, Ausrichter und Benutzer.
Haftungsausschluss: Dieser Artikel wurde mit Unterstützung der KI-Tools ChatGPT-5 und Gemini 3 abgeschlossen. Der Autor hat alle Anstrengungen unternommen, um die Informationen auf Richtigkeit und Authentizität zu überprüfen, aber es können dennoch Auslassungen bestehen. Bitte haben Sie Verständnis. Es sollte besonders beachtet werden, dass der Markt für Krypto-Assets oft Abweichungen zwischen den Grundlagen des Projekts und der Preisleistung des Sekundärmarktes aufweist. Der Inhalt dieses Artikels dient nur der Informationsintegration und dem akademischen/forschungs Austausch und stellt keine Anlageberatung dar, noch sollte er als Empfehlung zum Kauf oder Verkauf von Token betrachtet werden.