Zunächst fühlte sich die Frage theoretisch an. Was, wenn ein KI-Agent eine Entscheidung trifft, basierend auf Daten, die er von Tausenden von Menschen gelernt hat, und diese Entscheidung echten Schaden verursacht? Der Bildschirm war voller Dashboards, nichts Dramatisches, doch die Unruhe war echt. Das System verhielt sich korrekt gemäß seinen eigenen Regeln, aber niemand konnte klar sagen, wer verantwortlich war. Diese Lücke ist der Punkt, an dem die meisten Agentensysteme scheitern.
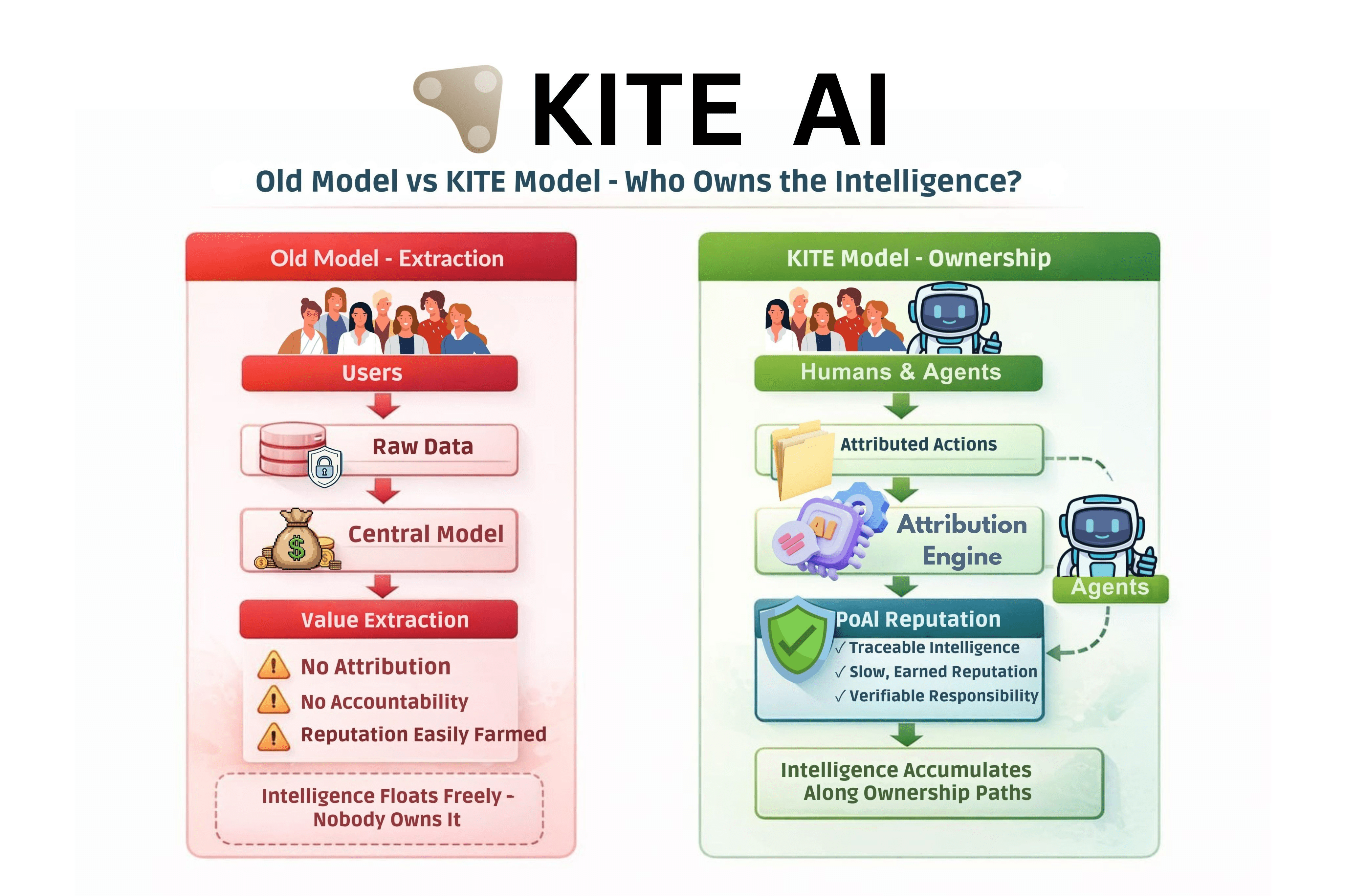
Ich war anfangs von den meisten Agentenplattformen aus demselben Grund skeptisch, aus dem ich frühen Reputationssystemen misstraue: Sie versprechen Koordination, verlassen sich jedoch auf Extraktion. Web2-Plattformen trainierten Modelle auf dem Nutzerverhalten, nannten es Optimierung und extrahierten nachhaltigen Wert. Empfehlungs-Engines, Kreditbewertungsmodelle, sogar frühe DAO-Reputationstools folgten alle demselben Verlauf. Daten gingen hinein, Intelligenz kam heraus, Eigentum verschwand. Das Versagen war nicht technischer Natur. Es war strukturell.
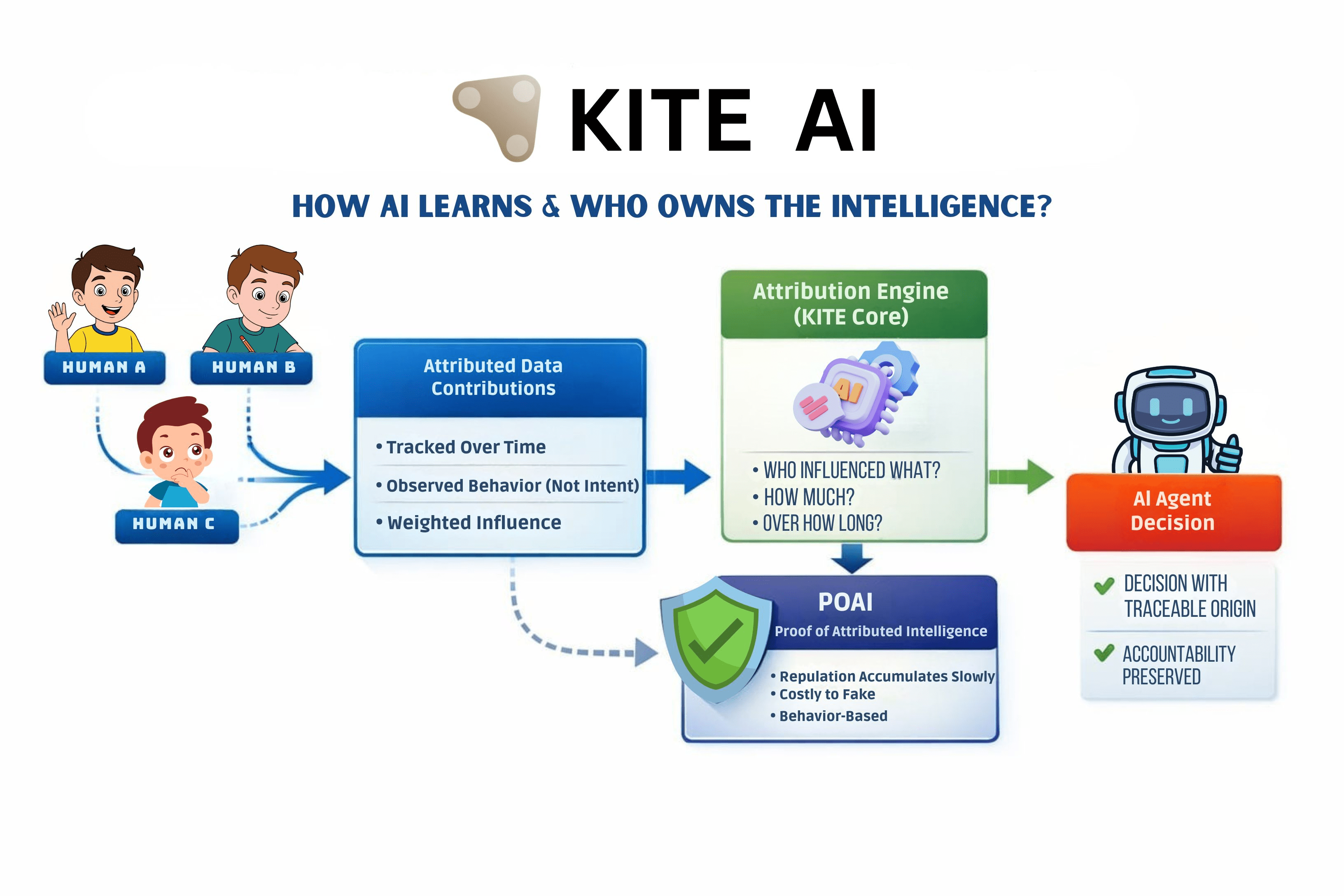
Was meine Sichtweise beim Studium von KITE veränderte, war nicht die KI-Schicht, sondern wie Verhalten zugeordnet und beibehalten wird. KITE behandelt das Nutzerverhalten eher wie einen Eintrag in ein Hauptbuch als wie einen Trainingsabfall. Ein konkretes Beispiel macht dies klarer. Wenn ein Agent seine Strategie aktualisiert, verfolgt das System, welche menschlichen oder agentenbasierten Signale diese Änderung beeinflusst haben, und weist gewichtete Zuordnungen basierend auf beobachtetem Verhalten über die Zeit zu, nicht auf der erklärten Absicht. Diese Zuordnung fließt in PoAI ein, eine verhaltensbasierte Reputationsschicht. Intelligenz schwebt nicht frei umher. Sie akkumuliert entlang nachverfolgbarer Pfade.
Dies ist der Ort, an dem frühere Modelle gescheitert sind. Token-Anreize, Emissionen oder einfache Rufwerte gingen von Ehrlichkeit oder Übereinstimmung aus. Wir haben auf die harte Tour gelernt, dass sie ausgebeutet werden können. Denken Sie an die frühe DeFi-Governance, bei der die Stimmkraft den Token folgte, nicht dem Verhalten, und böswillige Akteure die Ergebnisse billig eroberten. KITE kehrt dies um, indem es den Ruf kostspielig macht zu verdienen und langsam zu bewegen. Man kann keinen langfristigen Beitrag vortäuschen, ohne sich tatsächlich gut zu verhalten.
Die zu wenig diskutierte Implikation traf spät. Wenn Agenten beweisen können, woher ihre Intelligenz stammt, hört Daten auf, standardmäßig extraktiv zu sein. Das ist jetzt wichtig, denn 2025 bis 2026 ist der Zeitpunkt, an dem Agentennetzwerke anfangen, Geld, Arbeitsabläufe und Compliance zu berühren. Ohne Zuordnung werden Streitigkeiten zwischen menschlicher Absicht und Handeln des Agenten unlösbar. Mit ihr erfordert die Koordination keinen Konsens, sondern nur überprüfbare Verantwortung.
Es gibt einen Preis. Systeme wie dieses sind langsamer und schwieriger zu skalieren. Die Verhaltensverfolgung bringt Komplexität und neue Angriffspunkte mit sich. PoAI kann immer noch Vorurteile kodieren, wenn die gewählten Signale fehlerhaft sind. Und Token, die mit solchen Systemen verbunden sind, werden Nutzung und Vertrauensakkumulation widerspiegeln, nicht von Hype getriebenen Liquidität. Das schränkt kurzfristige Spekulationen ein, was einigen missfallen wird.
Die weitreichendere Implikation geht über KITE hinaus. Jedes Ökosystem, das Agenten ohne Datenbesitzgarantien einsetzt, baut unsichtbaren Hebel für jemand anderen auf. Wir haben bereits gesehen, dass dies bei sozialen Plattformen und Governance-DAOs gescheitert ist. Die unangenehme Erkenntnis ist, dass Intelligenz ohne Besitz nur Extraktion mit besserer Mathematik ist. Das Design von KITE löst nicht alles, macht dieses Risiko jedoch explizit, anstatt vorzutäuschen, dass es nicht existiert.

